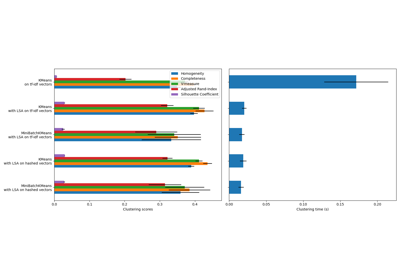
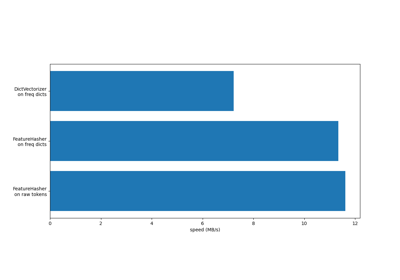
TfidfVectorizer#
- class sklearn.feature_extraction.text.TfidfVectorizer(input='content', encoding='utf-8', decode_error='strict', strip_accents=None, lowercase=True, preprocessor=None, tokenizer=None, analyzer='word', stop_words=None, token_pattern=r'(?u)\\b\\w\\w+\\b', ngram_range=(1, 1), max_df=1.0, min_df=1, max_features=None, vocabulary=None, binary=False, dtype=<class 'numpy.float64'>, norm='l2', use_idf=True, smooth_idf=True, sublinear_tf=False)[Quelle]#
Konvertiert eine Sammlung von Rohdokumenten in eine Matrix von TF-IDF-Merkmalen.
Äquivalent zu
CountVectorizergefolgt vonTfidfTransformer.Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- input{‘filename’, ‘file’, ‘content’}, standardmäßig=’content’
Wenn
'filename', wird erwartet, dass die als Argument an fit übergebene Sequenz eine Liste von Dateinamen ist, die gelesen werden müssen, um den zu analysierenden Rohinhalt abzurufen.Wenn
'file', müssen die Sequenzelemente eine „read“-Methode (dateiähnliches Objekt) haben, die aufgerufen wird, um die Bytes im Speicher abzurufen.Wenn
'content', wird erwartet, dass die Eingabe eine Sequenz von Elementen ist, die vom Typ String oder Byte sein können.
- encodingstr, standardmäßig=’utf-8’
Wenn Bytes oder Dateien zur Analyse übergeben werden, wird diese Kodierung zum Dekodieren verwendet.
- decode_error{‘strict’, ‘ignore’, ‘replace’}, standardmäßig=’strict’
Anweisung, was zu tun ist, wenn eine Byte-Sequenz zur Analyse übergeben wird, die Zeichen enthält, die nicht zur gegebenen
encodinggehören. Standardmäßig ist dies „strict“, was bedeutet, dass ein UnicodeDecodeError ausgelöst wird. Andere Werte sind „ignore“ und „replace“.- strip_accents{‘ascii’, ‘unicode’} oder aufrufbar, standardmäßig=None
Entfernen Sie Akzente und führen Sie andere Zeichennormalisierungen während des Vorverarbeitungsschritts durch. „ascii“ ist eine schnelle Methode, die nur auf Zeichen funktioniert, die eine direkte ASCII-Entsprechung haben. „unicode“ ist eine etwas langsamere Methode, die auf beliebigen Zeichen funktioniert. None (Standard) bedeutet, dass keine Zeichennormalisierung durchgeführt wird.
Sowohl „ascii“ als auch „unicode“ verwenden die NFKD-Normalisierung von
unicodedata.normalize.- lowercasebool, standardmäßig=True
Konvertiert alle Zeichen vor der Tokenisierung in Kleinbuchstaben.
- preprocessoraufrufbar, standardmäßig=None
Überschreiben Sie die Vorverarbeitungsstufe (String-Transformation) unter Beibehaltung der Tokenisierungs- und N-Gramm-Generierungsschritte. Gilt nur, wenn
analyzernicht aufrufbar ist.- tokenizeraufrufbar, standardmäßig=None
Überschreibt den Zeichenketten-Tokenisierungsschritt unter Beibehaltung der Schritte für Vorverarbeitung und N-Gramm-Generierung. Gilt nur, wenn
analyzer == 'word'.- analyzer{‘word’, ‘char’, ‘char_wb’} oder aufrufbar, standardmäßig=’word’
Ob die Features aus Wort- oder Zeichen-N-Grammen gebildet werden sollen. Die Option 'char_wb' erstellt Zeichen-N-Gramme nur aus Text innerhalb von Wortgrenzen; N-Gramme am Rand von Wörtern werden mit Leerzeichen aufgefüllt.
Wenn ein Aufrufbares übergeben wird, wird es verwendet, um die Sequenz von Merkmalen aus den rohen, unverarbeiteten Eingaben zu extrahieren.
Geändert in Version 0.21: Seit v0.21 werden, wenn
input'filename'oder'file'ist, die Daten zuerst aus der Datei gelesen und dann an den angegebenen aufrufbaren Analyzer übergeben.- stop_words{‘english’}, list, standardmäßig=None
Wenn es sich um einen String handelt, wird er an _check_stop_list übergeben und die entsprechende Stoppwortliste zurückgegeben. „english“ ist derzeit der einzige unterstützte String-Wert. Es gibt mehrere bekannte Probleme mit „english“ und Sie sollten eine Alternative in Betracht ziehen (siehe Verwendung von Stoppwörtern).
Wenn eine Liste, wird angenommen, dass diese Liste Stoppwörter enthält, die alle aus den resultierenden Tokens entfernt werden. Gilt nur, wenn
analyzer == 'word'.Wenn None, werden keine Stoppwörter verwendet. In diesem Fall kann das Setzen von
max_dfauf einen höheren Wert, z. B. im Bereich (0,7, 1,0), automatisch Stoppwörter basierend auf der intra-Korpus-Dokumentfrequenz von Begriffen erkennen und filtern.- token_patternstr, Standardwert=r”(?u)\b\w\w+\b”
Regulärer Ausdruck, der definiert, was ein „Token“ ausmacht. Wird nur verwendet, wenn
analyzer == 'word'. Der Standard-RegExp wählt Tokens von 2 oder mehr alphanumerischen Zeichen aus (Satzzeichen werden vollständig ignoriert und immer als Trennzeichen behandelt).Wenn es eine Erfassungsgruppe im token_pattern gibt, dann wird der Inhalt der erfassten Gruppe und nicht der gesamte Treffer zum Token. Es ist höchstens eine Erfassungsgruppe zulässig.
- ngram_rangeTupel (min_n, max_n), standardmäßig=(1, 1)
Die untere und obere Grenze des Bereichs von N-Werten für verschiedene zu extrahierende N-Gramme. Alle N-Werte, für die min_n <= n <= max_n gilt, werden verwendet. Zum Beispiel bedeutet ein
ngram_rangevon(1, 1)nur Unigramme,(1, 2)bedeutet Unigramme und Bigramme, und(2, 2)bedeutet nur Bigramme. Gilt nur, wennanalyzernicht aufrufbar ist.- max_dffloat oder int, Standardwert=1.0
Beim Erstellen des Vokabulars werden Begriffe mit einer Dokumentfrequenz, die strikt höher als der angegebene Schwellenwert ist (korpusbezogene Stoppwörter), ignoriert. Wenn float im Bereich [0,0, 1,0] liegt, repräsentiert der Parameter einen Anteil der Dokumente, ganzzahlige absolute Zählungen. Dieser Parameter wird ignoriert, wenn Vokabular nicht None ist.
- min_dffloat oder int, Standardwert=1
Beim Erstellen des Vokabulars werden Begriffe mit einer Dokumentfrequenz, die strikt niedriger als der angegebene Schwellenwert ist, ignoriert. Dieser Wert wird in der Literatur auch als Cut-off bezeichnet. Wenn float im Bereich [0,0, 1,0] liegt, repräsentiert der Parameter einen Anteil der Dokumente, ganzzahlige absolute Zählungen. Dieser Parameter wird ignoriert, wenn Vokabular nicht None ist.
- max_featuresint, Standardwert=None
Wenn nicht None, wird ein Vokabular erstellt, das nur die obersten
max_featuresberücksichtigt, geordnet nach der Termfrequenz im Korpus. Andernfalls werden alle Features verwendet.Dieser Parameter wird ignoriert, wenn Vokabular nicht None ist.
- vocabularyMapping oder Iterable, Standardwert=None
Entweder ein Mapping (z. B. ein Dictionary), bei dem die Schlüssel Begriffe und die Werte Indizes in der Feature-Matrix sind, oder ein Iterable über Begriffe. Wenn nicht angegeben, wird ein Vokabular aus den Eingabedokumenten bestimmt.
- binarybool, standardmäßig=False
Wenn True, werden alle von Null verschiedenen Term-Counts auf 1 gesetzt. Das bedeutet nicht, dass die Ausgaben nur 0/1-Werte enthalten, sondern nur, dass der TF-Term in TF-IDF binär ist. (Setzen Sie
binaryauf True,use_idfauf False undnormauf None, um 0/1-Ausgaben zu erhalten).- dtypedtype, Standardwert=float64
Typ der von fit_transform() oder transform() zurückgegebenen Matrix.
- norm{‘l1’, ‘l2’} oder None, Standardwert=’l2’
Jede Ausgabereihe hat die Einheitsnorm, entweder
‘l2’: Summe der Quadrate der Vektorelemente ist 1. Die Kosinusähnlichkeit zwischen zwei Vektoren ist ihr Skalarprodukt, wenn die l2-Norm angewendet wurde.
‘l1’: Summe der Absolutwerte der Vektorelemente ist 1. Siehe
normalize.None: Keine Normalisierung.
- use_idfbool, Standardwert=True
Inverse-Dokumentfrequenz-Neugewichtung aktivieren. Wenn False, ist idf(t) = 1.
- smooth_idfbool, Standardwert=True
Glättet IDF-Gewichte, indem zu den Dokumentfrequenzen eins addiert wird, als ob ein zusätzliches Dokument gesehen worden wäre, das jeden Begriff in der Sammlung genau einmal enthält. Verhindert Nullteilungen.
- sublinear_tfbool, Standardwert=False
Sublineare TF-Skalierung anwenden, d. h. TF durch 1 + log(TF) ersetzen.
- Attribute:
- vocabulary_dict
Ein Mapping von Begriffen zu Feature-Indizes.
- fixed_vocabulary_bool
True, wenn ein festes Vokabular von Begriff-zu-Index-Mappings vom Benutzer bereitgestellt wird.
idf_Array der Form (n_features,)Inverse Dokumentfrequenzvektor, nur definiert, wenn
use_idf=True.
Siehe auch
CountVectorizerTransformiert Text in eine Sparse-Matrix von N-Gramm-Zählungen.
TfidfTransformerFührt die TF-IDF-Transformation aus einer bereitgestellten Zählmatrix durch.
Beispiele
>>> from sklearn.feature_extraction.text import TfidfVectorizer >>> corpus = [ ... 'This is the first document.', ... 'This document is the second document.', ... 'And this is the third one.', ... 'Is this the first document?', ... ] >>> vectorizer = TfidfVectorizer() >>> X = vectorizer.fit_transform(corpus) >>> vectorizer.get_feature_names_out() array(['and', 'document', 'first', 'is', 'one', 'second', 'the', 'third', 'this'], ...) >>> print(X.shape) (4, 9)
- build_analyzer()[Quelle]#
Gibt eine aufrufbare Funktion zurück, um Eingabedaten zu verarbeiten.
Die aufrufbare Funktion kümmert sich um Vorverarbeitung, Tokenisierung und N-Gramm-Generierung.
- Gibt zurück:
- analyzer: callable
Eine Funktion zur Verarbeitung von Vorverarbeitung, Tokenisierung und N-Gramm-Generierung.
- build_preprocessor()[Quelle]#
Gibt eine Funktion zurück, die den Text vor der Tokenisierung vorverarbeitet.
- Gibt zurück:
- preprocessor: callable
Eine Funktion, die den Text vor der Tokenisierung vorverarbeitet.
- build_tokenizer()[Quelle]#
Gibt eine Funktion zurück, die einen String in eine Sequenz von Tokens aufteilt.
- Gibt zurück:
- tokenizer: callable
Eine Funktion, die einen String in eine Sequenz von Tokens aufteilt.
- decode(doc)[Quelle]#
Dekodiert die Eingabe in einen String aus Unicode-Symbolen.
Die Dekodierungsstrategie hängt von den Parametern des Vektorisierers ab.
- Parameter:
- docbytes oder str
Der zu dekodierende String.
- Gibt zurück:
- doc: str
Ein String aus Unicode-Symbolen.
- fit(raw_documents, y=None)[Quelle]#
Vokabular und IDF aus dem Trainingsdatensatz lernen.
- Parameter:
- raw_documentsIterable
Ein Iterable, das entweder Zeichenketten, Unicode-Zeichenketten oder Dateiobjekte erzeugt.
- yNone
Dieser Parameter wird nicht benötigt, um TF-IDF zu berechnen.
- Gibt zurück:
- selfobject
Gefitteter Vektorisierer.
- fit_transform(raw_documents, y=None)[Quelle]#
Vokabular und IDF lernen, Dokument-Term-Matrix zurückgeben.
Dies ist äquivalent zu fit gefolgt von transform, aber effizienter implementiert.
- Parameter:
- raw_documentsIterable
Ein Iterable, das entweder Zeichenketten, Unicode-Zeichenketten oder Dateiobjekte erzeugt.
- yNone
Dieser Parameter wird ignoriert.
- Gibt zurück:
- XSparse Matrix von (n_samples, n_features)
TF-IDF-gewichtete Dokument-Term-Matrix.
- get_feature_names_out(input_features=None)[Quelle]#
Holt die Ausgabemerkmale für die Transformation.
- Parameter:
- input_featuresarray-like von str oder None, default=None
Nicht verwendet, hier zur API-Konsistenz durch Konvention vorhanden.
- Gibt zurück:
- feature_names_outndarray von str-Objekten
Transformierte Merkmalnamen.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- get_stop_words()[Quelle]#
Erstellt oder ruft die effektive Stoppwortliste ab.
- Gibt zurück:
- stop_words: list oder None
Eine Liste von Stoppwörtern.
- inverse_transform(X)[Quelle]#
Gibt Begriffe pro Dokument mit Nicht-Null-Einträgen in X zurück.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Dokument-Term-Matrix.
- Gibt zurück:
- X_originalListe von Arrays der Form (n_samples,)
Liste von Arrays von Begriffen.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- transform(raw_documents)[Quelle]#
Transformiert Dokumente in eine Dokument-Term-Matrix.
Verwendet das Vokabular und die Dokumentfrequenzen (df), die mit fit (oder fit_transform) gelernt wurden.
- Parameter:
- raw_documentsIterable
Ein Iterable, das entweder Zeichenketten, Unicode-Zeichenketten oder Dateiobjekte erzeugt.
- Gibt zurück:
- XSparse Matrix von (n_samples, n_features)
TF-IDF-gewichtete Dokument-Term-Matrix.
Galeriebeispiele#
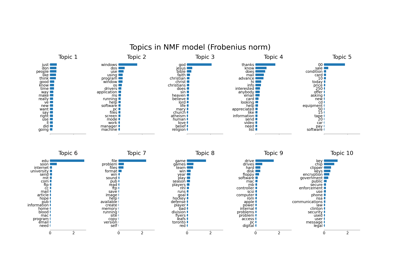
Themenextraktion mit Non-negative Matrix Factorization und Latent Dirichlet Allocation

Biclustering von Dokumenten mit dem Spectral Co-Clustering Algorithmus

Beispiel-Pipeline für Textmerkmal-Extraktion und -Bewertung
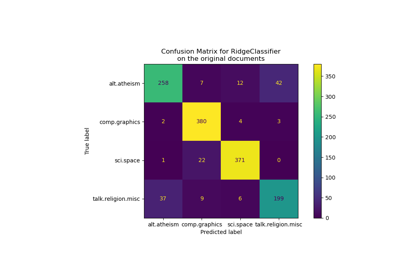
Klassifikation von Textdokumenten mit spärlichen Merkmalen