GaussianProcessClassifier#
- class sklearn.gaussian_process.GaussianProcessClassifier(kernel=None, *, optimizer='fmin_l_bfgs_b', n_restarts_optimizer=0, max_iter_predict=100, warm_start=False, copy_X_train=True, random_state=None, multi_class='one_vs_rest', n_jobs=None)[Quelle]#
Gauß'sche Prozess-Klassifikation (GPC) basierend auf Laplace-Approximation.
Die Implementierung basiert auf den Algorithmen 3.1, 3.2 und 5.1 aus [RW2006].
Intern wird die Laplace-Approximation verwendet, um die nicht-Gaußsche Posterior-Verteilung durch eine Gaußsche zu approximieren.
Derzeit ist die Implementierung auf die Verwendung der logistischen Link-Funktion beschränkt. Für Mehrklassenklassifizierung werden mehrere binäre One-vs-Rest-Klassifikatoren angepasst. Beachten Sie, dass diese Klasse somit keine echte Mehrklassen-Laplace-Approximation implementiert.
Lesen Sie mehr im Benutzerhandbuch.
Hinzugefügt in Version 0.18.
- Parameter:
- kernelKernel-Instanz, Standardwert=None
Der Kernel, der die Kovarianzfunktion des GP spezifiziert. Wenn None übergeben wird, wird als Standard der Kernel „1.0 * RBF(1.0)“ verwendet. Beachten Sie, dass die Hyperparameter des Kernels während des Anpassens optimiert werden. Kernel kann auch kein
CompoundKernelsein.- optimizer„fmin_l_bfgs_b“, aufrufbar oder None, Standardwert=„fmin_l_bfgs_b“
Kann entweder einer der intern unterstützten Optimierer zur Optimierung der Kernel-Parameter sein, spezifiziert durch einen String, oder ein extern definierter Optimierer, der als aufrufbare Funktion übergeben wird. Wenn eine aufrufbare Funktion übergeben wird, muss sie die Signatur
def optimizer(obj_func, initial_theta, bounds): # * 'obj_func' is the objective function to be maximized, which # takes the hyperparameters theta as parameter and an # optional flag eval_gradient, which determines if the # gradient is returned additionally to the function value # * 'initial_theta': the initial value for theta, which can be # used by local optimizers # * 'bounds': the bounds on the values of theta .... # Returned are the best found hyperparameters theta and # the corresponding value of the target function. return theta_opt, func_min
Standardmäßig wird der Algorithmus „L-BFGS-B“ von scipy.optimize.minimize verwendet. Wenn None übergeben wird, bleiben die Kernel-Parameter fixiert. Verfügbare interne Optimierer sind
'fmin_l_bfgs_b'- n_restarts_optimizerint, Standardwert=0
Die Anzahl der Neustarts des Optimierers zur Ermittlung der Kernel-Parameter, welche die Log-Marginal-Likelihood maximieren. Der erste Lauf des Optimierers erfolgt von den initialen Kernel-Parametern aus, die verbleibenden Läufe (falls vorhanden) von Thetas, die log-uniform zufällig aus dem Raum der erlaubten Theta-Werte gezogen wurden. Wenn größer als 0, müssen alle Grenzen endlich sein. Beachten Sie, dass n_restarts_optimizer=0 impliziert, dass ein Lauf durchgeführt wird.
- max_iter_predictint, Standardwert=100
Die maximale Anzahl von Iterationen in Newtons Methode zur Approximation der Posterior-Verteilung während der Vorhersage. Kleinere Werte reduzieren die Rechenzeit auf Kosten schlechterer Ergebnisse.
- warm_startbool, Standard=False
Wenn Warm-Starts aktiviert sind, wird die Lösung der letzten Newton-Iteration zur Laplace-Approximation des Posterior-Modus als Initialisierung für den nächsten Aufruf von _posterior_mode() verwendet. Dies kann die Konvergenz beschleunigen, wenn _posterior_mode mehrmals für ähnliche Probleme wie bei der Hyperparameter-Optimierung aufgerufen wird. Siehe Glossar.
- copy_X_trainbool, Standardwert=True
Wenn True, wird eine persistente Kopie der Trainingsdaten im Objekt gespeichert. Andernfalls wird nur eine Referenz auf die Trainingsdaten gespeichert, was dazu führen kann, dass sich Vorhersagen ändern, wenn die Daten extern modifiziert werden.
- random_stateint, RandomState-Instanz oder None, default=None
Bestimmt die Zufallszahlengenerierung, die zur Initialisierung der Zentren verwendet wird. Übergeben Sie eine Ganzzahl für reproduzierbare Ergebnisse über mehrere Funktionsaufrufe hinweg. Siehe Glossar.
- multi_class{„one_vs_rest“, „one_vs_one“}, Standardwert=„one_vs_rest“
Gibt an, wie Mehrklassen-Klassifizierungsprobleme behandelt werden. Unterstützt werden „one_vs_rest“ und „one_vs_one“. Bei „one_vs_rest“ wird für jede Klasse ein binärer Gaußscher Prozessklassifikator angepasst, der trainiert wird, diese Klasse von den übrigen zu trennen. Bei „one_vs_one“ wird für jedes Klassenpaar ein binärer Gaußscher Prozessklassifikator angepasst, der trainiert wird, diese beiden Klassen zu trennen. Die Vorhersagen dieser binären Prädiktoren werden zu Mehrklassen-Vorhersagen kombiniert. Beachten Sie, dass „one_vs_one“ keine Wahrscheinlichkeitsschätzungen unterstützt.
- n_jobsint, default=None
Die Anzahl der Jobs, die für die Berechnung verwendet werden: Die angegebenen Mehrklassenprobleme werden parallel berechnet.
Nonebedeutet 1, es sei denn, Sie befinden sich in einemjoblib.parallel_backend-Kontext.-1bedeutet, alle Prozessoren zu verwenden. Siehe Glossar für weitere Details.
- Attribute:
- base_estimator_
Estimator-Instanz Die Estimator-Instanz, die die Likelihood-Funktion unter Verwendung der beobachteten Daten definiert.
kernel_Kernel-InstanzGibt den Kernel des Basis-Estimators zurück.
- log_marginal_likelihood_value_float
Die Log-Marginal-Likelihood von
self.kernel_.theta- classes_array-ähnlich mit Form (n_classes,)
Eindeutige Klassenbezeichnungen.
- n_classes_int
Die Anzahl der Klassen in den Trainingsdaten
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
- base_estimator_
Siehe auch
GaussianProcessRegressorGauß'sche Prozess-Regression (GPR).
Referenzen
Beispiele
>>> from sklearn.datasets import load_iris >>> from sklearn.gaussian_process import GaussianProcessClassifier >>> from sklearn.gaussian_process.kernels import RBF >>> X, y = load_iris(return_X_y=True) >>> kernel = 1.0 * RBF(1.0) >>> gpc = GaussianProcessClassifier(kernel=kernel, ... random_state=0).fit(X, y) >>> gpc.score(X, y) 0.9866... >>> gpc.predict_proba(X[:2,:]) array([[0.83548752, 0.03228706, 0.13222543], [0.79064206, 0.06525643, 0.14410151]])
Zum Vergleich des GaussianProcessClassifier mit anderen Klassifikatoren siehe: Plot classification probability.
- fit(X, y)[Quelle]#
Passt das Gaußsche Prozess-Klassifizierungsmodell an.
- Parameter:
- Xarray-ähnlich mit Form (n_samples, n_features) oder Liste von Objekten
Feature-Vektoren oder andere Darstellungen von Trainingsdaten.
- yarray-like von Form (n_samples,)
Zielwerte, müssen binär sein.
- Gibt zurück:
- selfobject
Gibt eine Instanz von self zurück.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- latent_mean_and_variance(X)[Quelle]#
Berechnet den Mittelwert und die Varianz der latenten Funktion.
Basierend auf Algorithmus 3.2 von [RW2006] gibt diese Funktion den latenten Mittelwert (Zeile 4) und die Varianz (Zeile 6) des Gaußschen Prozess-Klassifizierungsmodells zurück.
Beachten Sie, dass diese Funktion nur für binäre Klassifizierung unterstützt wird.
Hinzugefügt in Version 1.7.
- Parameter:
- Xarray-ähnlich mit Form (n_samples, n_features) oder Liste von Objekten
Abfragepunkte, an denen der GP für die Klassifizierung ausgewertet wird.
- Gibt zurück:
- latent_meanarray-ähnlich mit Form (n_samples,)
Mittelwert der latenten Funktionswerte an den Abfragepunkten.
- latent_vararray-ähnlich mit Form (n_samples,)
Varianz der latenten Funktionswerte an den Abfragepunkten.
- log_marginal_likelihood(theta=None, eval_gradient=False, clone_kernel=True)[Quelle]#
Gibt die Log-Marginal-Likelihood von theta für Trainingsdaten zurück.
Im Fall von Mehrklassenklassifizierung werden die mittleren Log-Marginal-Likelihoods der One-vs-Rest-Klassifikatoren zurückgegeben.
- Parameter:
- thetaarray-ähnlich mit Form (n_kernel_params,), Standardwert=None
Kernel-Hyperparameter, für die die Log-Marginal-Likelihood ausgewertet wird. Im Fall von Mehrklassenklassifizierung kann theta die Hyperparameter des zusammengesetzten Kernels oder eines einzelnen Kernels sein. Im letzteren Fall werden allen individuellen Kernels die gleichen Theta-Werte zugewiesen. Wenn None, wird die vorberechnete Log-Marginal-Likelihood von
self.kernel_.thetazurückgegeben.- eval_gradientbool, Standardwert=False
Wenn True, wird zusätzlich der Gradient der Log-Marginal-Likelihood bezüglich der Kernel-Hyperparameter an der Position theta zurückgegeben. Beachten Sie, dass die Gradientenberechnung für nicht-binäre Klassifizierung nicht unterstützt wird. Wenn True, darf theta nicht None sein.
- clone_kernelbool, Standardwert=True
Wenn True, wird das Kernel-Attribut kopiert. Wenn False, wird das Kernel-Attribut modifiziert, was jedoch zu einer Leistungsverbesserung führen kann.
- Gibt zurück:
- log_likelihoodfloat
Log-Marginal-Likelihood von theta für Trainingsdaten.
- log_likelihood_gradientndarray mit Form (n_kernel_params,), optional
Gradient der Log-Marginal-Likelihood bezüglich der Kernel-Hyperparameter an der Position theta. Nur zurückgegeben, wenn
eval_gradientTrue ist.
- predict(X)[Quelle]#
Führt die Klassifizierung auf einem Array von Testvektoren X durch.
- Parameter:
- Xarray-ähnlich mit Form (n_samples, n_features) oder Liste von Objekten
Abfragepunkte, an denen der GP für die Klassifizierung ausgewertet wird.
- Gibt zurück:
- Cndarray der Form (n_samples,)
Vorhergesagte Zielwerte für X, Werte stammen aus
classes_.
- predict_proba(X)[Quelle]#
Gibt Wahrscheinlichkeitsschätzungen für den Testvektor X zurück.
- Parameter:
- Xarray-ähnlich mit Form (n_samples, n_features) oder Liste von Objekten
Abfragepunkte, an denen der GP für die Klassifizierung ausgewertet wird.
- Gibt zurück:
- Carray-like der Form (n_samples, n_classes)
Gibt die Wahrscheinlichkeit der Stichproben für jede Klasse im Modell zurück. Die Spalten entsprechen den Klassen in sortierter Reihenfolge, wie sie im Attribut classes_ erscheinen.
- score(X, y, sample_weight=None)[Quelle]#
Gibt die Genauigkeit für die bereitgestellten Daten und Bezeichnungen zurück.
Bei der Multi-Label-Klassifizierung ist dies die Subset-Genauigkeit, eine strenge Metrik, da für jede Stichprobe verlangt wird, dass jede Label-Menge korrekt vorhergesagt wird.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben.
- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Bezeichnungen für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
Mittlere Genauigkeit von
self.predict(X)in Bezug aufy.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') GaussianProcessClassifier[Quelle]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
Galeriebeispiele#

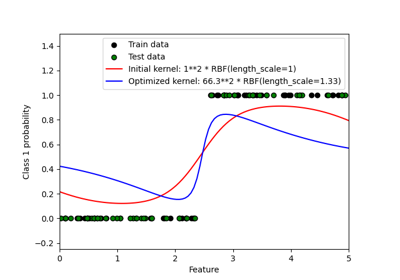
Probabilistische Vorhersagen mit Gauß-Prozess-Klassifikation (GPC)
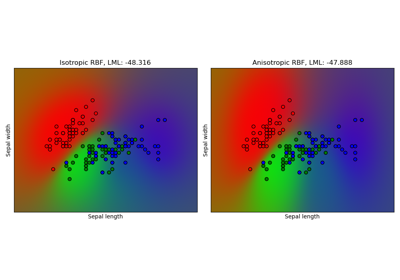
Gauß-Prozess-Klassifikation (GPC) auf dem Iris-Datensatz
Iso-Wahrscheinlichkeitslinien für Gauß-Prozesse Klassifikation (GPC)
Illustration der Gauß-Prozess-Klassifikation (GPC) auf dem XOR-Datensatz