QuadraticDiscriminantAnalysis#
- class sklearn.discriminant_analysis.QuadraticDiscriminantAnalysis(*, solver='svd', shrinkage=None, priors=None, reg_param=0.0, store_covariance=False, tol=0.0001, covariance_estimator=None)[source]#
Quadratische Diskriminanzanalyse.
Ein Klassifikator mit einer quadratischen Entscheidungsgrenze, der durch Anpassung der klassenbedingten Dichten an die Daten und Anwendung der Bayes-Regel erzeugt wird.
Das Modell passt eine Gaußsche Dichte an jede Klasse an.
Hinzugefügt in Version 0.17.
Für einen Vergleich zwischen
QuadraticDiscriminantAnalysisundLinearDiscriminantAnalysissiehe Linear und Quadratische Diskriminanzanalyse mit Kovarianzellipsoid.Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- solver{‘svd’, ‘eigen’}, default=’svd’
- Zu verwendender Löser, mögliche Werte
‘svd’: Singuläre Zerlegung (Standard). Berechnet die Kovarianzmatrix nicht, daher wird dieser Löser für Daten mit einer großen Anzahl von Merkmalen empfohlen.
‘eigen’: Eigenwertzerlegung. Kann mit Schrumpfung oder einem benutzerdefinierten Kovarianzschätzer kombiniert werden.
- shrinkage‘auto‘ oder float, default=None
- Schrumpfungsparameter, mögliche Werte
None: keine Schrumpfung (Standard).
‘auto’: automatische Schrumpfung nach dem Ledoit-Wolf-Lemma.
float zwischen 0 und 1: fester Schrumpfungsparameter.
Die Aktivierung der Schrumpfung wird voraussichtlich das Modell verbessern, wenn einige Klassen im Vergleich zur Anzahl der Merkmale relativ wenige Trainingsdatenpunkte aufweisen, indem sie Überanpassung während des Kovarianzschätzschritts mildert.
Dies sollte auf
Nonebelassen werden, wenncovariance_estimatorverwendet wird. Beachten Sie, dass die Schrumpfung nur mit dem ‘eigen’-Löser funktioniert.- priorsarray-like von Form (n_classes,), default=None
Klassen-A-priori-Wahrscheinlichkeiten. Standardmäßig werden die Klassenanteile aus den Trainingsdaten abgeleitet.
- reg_paramfloat, default=0.0
Reguliert die Kovarianzschätzungen pro Klasse, indem S2 transformiert wird als
S2 = (1 - reg_param) * S2 + reg_param * np.eye(n_features), wobei S2 demscaling_Attribut einer gegebenen Klasse entspricht.- store_covariancebool, default=False
Wenn True, werden die Klassenkovarianzmatrizen explizit berechnet und im Attribut
self.covariance_gespeichert.Hinzugefügt in Version 0.17.
- tolfloat, default=1.0e-4
Absolute Schwelle für die Kovarianzmatrix, damit sie nach Anwendung einer gewissen Regularisierung (siehe
reg_param) für jedeSk, wobeiSkdie Kovarianzmatrix für die k-te Klasse darstellt, als Rang-defizitär betrachtet wird. Dieser Parameter beeinflusst die Vorhersagen nicht. Er steuert, wann eine Warnung ausgegeben wird, wenn die Kovarianzmatrix nicht vollen Rang hat.Hinzugefügt in Version 0.17.
- covariance_estimatorKovarianzschätzer, default=None
Wenn nicht None, wird
covariance_estimatorverwendet, um die Kovarianzmatrizen zu schätzen, anstatt sich auf den empirischen Kovarianzschätzer (mit möglicher Schrumpfung) zu verlassen. Das Objekt sollte eine fit-Methode und eincovariance_Attribut wie die Schätzer insklearn.covariancehaben. Wenn None, steuert der Schrumpfungsparameter die Schätzung.Dies sollte auf
Nonebelassen werden, wennshrinkageverwendet wird. Beachten Sie, dasscovariance_estimatornur mit dem ‘eigen’-Löser funktioniert.
- Attribute:
- covariance_Liste von n_classes Elementen der Form ndarray von Shape (n_features, n_features)
Gibt für jede Klasse die Kovarianzmatrix an, die mithilfe der Stichproben dieser Klasse geschätzt wurde. Die Schätzungen sind unverzerrt. Nur vorhanden, wenn
store_covarianceTrue ist.- means_array-ähnlich der Form (n_classes, n_features)
Klassenweise Mittelwerte.
- priors_array-ähnlich der Form (n_classes,)
Klassen-A-priori-Wahrscheinlichkeiten (summiert sich zu 1).
- rotations_Liste von n_classes Elementen der Form ndarray von Shape (n_features, n_k)
Für jede Klasse k ein Array der Form (n_features, n_k), wobei
n_k = min(n_features, Anzahl der Elemente in Klasse k). Es ist die Rotation der Gaußschen Verteilung, d.h. ihre Hauptachse. Es entsprichtV, der Matrix der Eigenvektoren aus der SVD vonXk = U S Vt, wobeiXkdie zentrierte Matrix der Stichproben aus Klasse k ist.- scalings_Liste von n_classes Elementen der Form ndarray von Shape (n_k,)
Enthält für jede Klasse die Skalierung der Gaußschen Verteilungen entlang ihrer Hauptachsen, d.h. die Varianz im rotierten Koordinatensystem. Es entspricht
S^2 / (n_samples - 1), wobeiSdie Diagonalmatrix der singulären Werte aus der SVD vonXkist, wobeiXkdie zentrierte Matrix der Stichproben aus Klasse k ist.- classes_ndarray der Form (n_classes,)
Eindeutige Klassenbezeichnungen.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
Siehe auch
LinearDiscriminantAnalysisLineare Diskriminanzanalyse.
Beispiele
>>> from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis >>> import numpy as np >>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) >>> y = np.array([1, 1, 1, 2, 2, 2]) >>> clf = QuadraticDiscriminantAnalysis() >>> clf.fit(X, y) QuadraticDiscriminantAnalysis() >>> print(clf.predict([[-0.8, -1]])) [1]
- decision_function(X)[source]#
Anwenden der Entscheidungfunktion auf ein Array von Stichproben.
Die Entscheidungsfunktion ist gleich (bis auf einen konstanten Faktor) dem Log-Posteriori des Modells, d.h.
log p(y = k | x). In einem binären Klassifizierungsszenario entspricht dies stattdessen der Differenzlog p(y = 1 | x) - log p(y = 0 | x). Siehe Mathematische Formulierung der LDA- und QDA-Klassifikatoren.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Array von Stichproben (Testvektoren).
- Gibt zurück:
- Cndarray von Shape (n_samples,) oder (n_samples, n_classes)
Entscheidungsfunktionswerte, die sich auf jede Klasse pro Stichprobe beziehen. Im Fall von zwei Klassen hat die Form
(n_samples,)und gibt das Log-Likelihood-Verhältnis der positiven Klasse an.
- fit(X, y)[source]#
Modell anhand der gegebenen Trainingsdaten und Parameter anpassen.
Geändert in Version 0.19:
store_covarianceswurde in den Hauptkonstruktor alsstore_covarianceverschoben.Geändert in Version 0.19:
tolwurde in den Hauptkonstruktor verschoben.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Trainingsvektor, wobei
n_samplesdie Anzahl der Stichproben undn_featuresdie Anzahl der Merkmale ist.- yarray-like von Form (n_samples,)
Zielwerte (ganzzahlig).
- Gibt zurück:
- selfobject
Angepasster Schätzer.
- get_metadata_routing()[source]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[source]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X)[source]#
Klassifizierung auf einem Array von Vektoren
Xdurchführen.Gibt die Klassenbezeichnung für jede Stichprobe zurück.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Eingangsvektoren, wobei
n_samplesdie Anzahl der Stichproben undn_featuresdie Anzahl der Merkmale ist.
- Gibt zurück:
- y_predndarray von Form (n_samples,)
Klassenbezeichnung für jede Stichprobe.
- predict_log_proba(X)[source]#
Logarithmus der Klassenwahrscheinlichkeiten schätzen.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Eingabedaten.
- Gibt zurück:
- y_log_probandarray der Form (n_samples, n_classes)
Geschätzte Log-Wahrscheinlichkeiten.
- predict_proba(X)[source]#
Klassenwahrscheinlichkeiten schätzen.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Eingabedaten.
- Gibt zurück:
- y_probandarray der Form (n_samples, n_classes)
Wahrscheinlichkeitsschätzung der Stichprobe für jede Klasse im Modell, wobei die Klassen in der Reihenfolge sortiert sind, wie sie in
self.classes_vorkommen.
- score(X, y, sample_weight=None)[source]#
Gibt die Genauigkeit für die bereitgestellten Daten und Bezeichnungen zurück.
Bei der Multi-Label-Klassifizierung ist dies die Subset-Genauigkeit, eine strenge Metrik, da für jede Stichprobe verlangt wird, dass jede Label-Menge korrekt vorhergesagt wird.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben.
- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Bezeichnungen für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
Mittlere Genauigkeit von
self.predict(X)in Bezug aufy.
- set_params(**params)[source]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') QuadraticDiscriminantAnalysis[source]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
Galeriebeispiele#

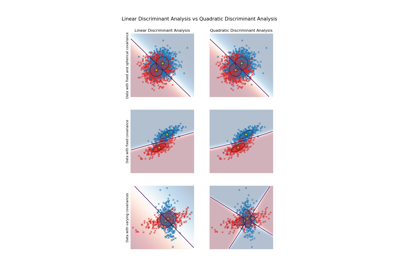
Lineare und Quadratische Diskriminanzanalyse mit Kovarianzellipsoid