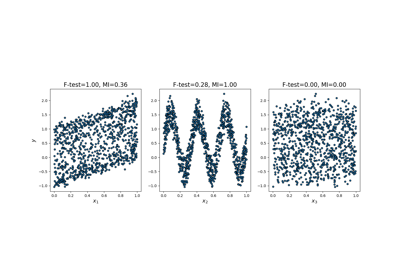
mutual_info_regression#
- sklearn.feature_selection.mutual_info_regression(X, y, *, discrete_features='auto', n_neighbors=3, copy=True, random_state=None, n_jobs=None)[Quelle]#
Schätzt die gegenseitige Information für eine kontinuierliche Zielvariable.
Die gegenseitige Information (MI) [1] zwischen zwei Zufallsvariablen ist ein nicht-negativer Wert, der die Abhängigkeit zwischen den Variablen misst. Er ist genau dann null, wenn zwei Zufallsvariablen unabhängig sind, und höhere Werte bedeuten höhere Abhängigkeit.
Die Funktion basiert auf nicht-parametrischen Methoden zur Schätzung der Entropie aus k-nächste-Nachbarn-Distanzen, wie in [2] und [3] beschrieben. Beide Methoden basieren auf der Idee, die ursprünglich in [4] vorgeschlagen wurde.
Sie kann zur univariaten Merkmalsauswahl verwendet werden, lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- Xarray-like oder sparse matrix, Form (n_samples, n_features)
Merkmalsmatrix.
- yarray-like von Form (n_samples,)
Zielvektor.
- discrete_features{‘auto’, bool, array-like}, Standardwert=’auto’
Wenn bool, wird bestimmt, ob alle Merkmale als diskret oder kontinuierlich betrachtet werden sollen. Wenn array, dann sollte es entweder eine boolesche Maske der Form (n_features,) oder ein Array mit den Indizes der diskreten Merkmale sein. Wenn ‚auto‘, wird es für dichte
Xauf False und für spärlicheXauf True gesetzt.- n_neighborsint, Standardwert=3
Anzahl der Nachbarn, die für die MI-Schätzung für kontinuierliche Variablen verwendet werden, siehe [2] und [3]. Höhere Werte reduzieren die Varianz der Schätzung, können aber einen Bias einführen.
- copybool, Standard=True
Ob eine Kopie der gegebenen Daten erstellt werden soll. Wenn auf False gesetzt, werden die ursprünglichen Daten überschrieben.
- random_stateint, RandomState-Instanz oder None, default=None
Bestimmt die Zufallszahlengenerierung zum Hinzufügen von kleinem Rauschen zu kontinuierlichen Variablen, um wiederholte Werte zu entfernen. Geben Sie eine Ganzzahl für reproduzierbare Ergebnisse über mehrere Funktionsaufrufe hinweg an. Siehe Glossar.
- n_jobsint, default=None
Die Anzahl der Jobs, die zur Berechnung der gegenseitigen Information verwendet werden. Die Parallelisierung erfolgt über die Spalten von
X.Nonebedeutet 1, außer in einemjoblib.parallel_backendKontext.-1bedeutet die Verwendung aller Prozessoren. Siehe Glossar für weitere Details.Hinzugefügt in Version 1.5.
- Gibt zurück:
- mindarray, Form (n_features,)
Geschätzte gegenseitige Information zwischen jedem Merkmal und dem Ziel in nat-Einheiten.
Anmerkungen
Der Begriff "diskrete Merkmale" wird anstelle von "kategorial" verwendet, da er das Wesentliche genauer beschreibt. Zum Beispiel sind Pixelintensitäten eines Bildes diskrete Merkmale (aber kaum kategorial) und Sie erzielen bessere Ergebnisse, wenn Sie sie als solche markieren. Beachten Sie auch, dass die Behandlung einer kontinuierlichen Variable als diskret und umgekehrt normalerweise zu falschen Ergebnissen führt, seien Sie also darauf aufmerksam.
Die wahre gegenseitige Information kann nicht negativ sein. Wenn ihre Schätzung negativ ausfällt, wird sie durch Null ersetzt.
Referenzen
[1]Gegenseitige Information auf Wikipedia.
[2] (1,2)A. Kraskov, H. Stogbauer und P. Grassberger, „Estimating mutual information“. Phys. Rev. E 69, 2004.
[3] (1,2)B. C. Ross „Mutual Information between Discrete and Continuous Data Sets“. PLoS ONE 9(2), 2014.
[4]L. F. Kozachenko, N. N. Leonenko, „Sample Estimate of the Entropy of a Random Vector“, Probl. Peredachi Inf., 23:2 (1987), 9-16
Beispiele
>>> from sklearn.datasets import make_regression >>> from sklearn.feature_selection import mutual_info_regression >>> X, y = make_regression( ... n_samples=50, n_features=3, n_informative=1, noise=1e-4, random_state=42 ... ) >>> mutual_info_regression(X, y) array([0.117, 2.645, 0.0287])