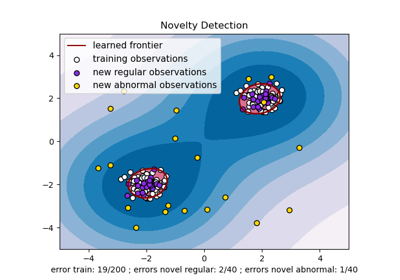
OneClassSVM#
- class sklearn.svm.OneClassSVM(*, kernel='rbf', degree=3, gamma='scale', coef0=0.0, tol=0.001, nu=0.5, shrinking=True, cache_size=200, verbose=False, max_iter=-1)[Quelle]#
Unüberwachte Ausreißererkennung.
Schätzt die Unterstützung einer hochdimensionalen Verteilung.
Die Implementierung basiert auf libsvm.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- kernel{‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’} oder aufrufbar, Standard=’rbf’
Gibt den Typ des im Algorithmus zu verwendenden Kernels an. Wenn keiner angegeben ist, wird 'rbf' verwendet. Wenn eine aufrufbare Funktion angegeben wird, wird diese zur Vorberechnung der Kernel-Matrix verwendet.
- degreeint, Standard=3
Grad der Polynomkernfunktion (‘poly’). Muss nicht-negativ sein. Wird von allen anderen Kernels ignoriert.
- gamma{‘scale’, ‘auto’} oder float, Standard=’scale’
Kernel-Koeffizient für ‘rbf’, ‘poly’ und ‘sigmoid’.
Wenn
gamma='scale'(Standard) übergeben wird, wird 1 / (n_features * X.var()) als Wert für gamma verwendet,wenn ‘auto’, wird 1 / n_features verwendet
Wenn float, muss nicht-negativ sein.
Geändert in Version 0.22: Der Standardwert von
gammawurde von ‘auto’ auf ‘scale’ geändert.- coef0float, Standard=0.0
Unabhängiger Term in der Kernelfunktion. Er ist nur in ‘poly’ und ‘sigmoid’ signifikant.
- tolfloat, Standard=1e-3
Toleranz für das Abbruchkriterium.
- nufloat, Standard=0.5
Eine Obergrenze für den Anteil der Trainingsfehler und eine Untergrenze für den Anteil der Stützvektoren. Sollte im Intervall (0, 1] liegen. Standardmäßig wird 0,5 angenommen.
- shrinkingbool, Standard=True
Ob die „shrinking“-Heuristik verwendet werden soll. Siehe Benutzerhandbuch.
- cache_sizefloat, Standard=200
Gibt die Größe des Kernel-Caches an (in MB).
- verbosebool, default=False
Aktiviert ausführliche Ausgabe. Beachten Sie, dass diese Einstellung eine laufende Prozess-Einstellung in libsvm nutzt, die, wenn sie aktiviert ist, in einem Multithreading-Kontext möglicherweise nicht ordnungsgemäß funktioniert.
- max_iterint, Standard=-1
Harte Obergrenze für Iterationen innerhalb des Solvers oder -1 für keine Obergrenze.
- Attribute:
coef_ndarray der Form (1, n_features)Gewichte, die den Merkmalen zugeordnet sind, wenn
kernel="linear".- dual_coef_ndarray der Form (1, n_SV)
Koeffizienten der Stützvektoren in der Entscheidungfunktion.
- fit_status_int
0, wenn korrekt angepasst, 1 andernfalls (löst eine Warnung aus)
- intercept_ndarray of shape (1,)
Konstante in der Entscheidungfunktion.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
- n_iter_int
Anzahl der Iterationen, die von der Optimierungsroutine zur Anpassung des Modells durchgeführt werden.
Hinzugefügt in Version 1.1.
n_support_ndarray der Form (n_classes,), dtype=int32Anzahl der Support-Vektoren pro Klasse.
- offset_float
Offset zur Definition der Entscheidungfunktion aus den Rohwerten. Wir haben die Relation: decision_function = score_samples -
offset_. Der Offset ist das Gegenteil vonintercept_und wird zur Konsistenz mit anderen Algorithmen zur Anomalieerkennung bereitgestellt.Hinzugefügt in Version 0.20.
- shape_fit_tuple von int der Form (n_dimensions_of_X,)
Array-Dimensionen des Trainingsvektors
X.- support_ndarray der Form (n_SV,)
Indizes der Support-Vektoren.
- support_vectors_ndarray der Form (n_SV, n_features)
Support-Vektoren.
Siehe auch
sklearn.linear_model.SGDOneClassSVMLöst lineare One-Class-SVM mit stochastischem Gradientenabstieg.
sklearn.neighbors.LocalOutlierFactorUnüberwachte Anomalieerkennung mittels Local Outlier Factor (LOF).
sklearn.ensemble.IsolationForestIsolation Forest Algorithmus.
Beispiele
>>> from sklearn.svm import OneClassSVM >>> X = [[0], [0.44], [0.45], [0.46], [1]] >>> clf = OneClassSVM(gamma='auto').fit(X) >>> clf.predict(X) array([-1, 1, 1, 1, -1]) >>> clf.score_samples(X) array([1.7798, 2.0547, 2.0556, 2.0561, 1.7332])
Für ein ausführlicheres Beispiel siehe Modellierung der Artenverteilung
- decision_function(X)[Quelle]#
Vorzeichenbehafteter Abstand zur trennenden Hyperebene.
Der vorzeichenbehaftete Abstand ist für einen Inlier positiv und für einen Outlier negativ.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Die Datenmatrix.
- Gibt zurück:
- decndarray der Form (n_samples,)
Gibt die Entscheidungfunktion der Samples zurück.
- fit(X, y=None, sample_weight=None)[Quelle]#
Erkennt die weiche Grenze der Menge der Samples X.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Menge von Samples, wobei
n_samplesdie Anzahl der Samples undn_featuresdie Anzahl der Merkmale ist.- yIgnoriert
Wird nicht verwendet, ist aber aus Gründen der API-Konsistenz per Konvention vorhanden.
- sample_weightarray-like der Form (n_samples,), Standardwert=None
Gewichte pro Sample. Skaliert C pro Sample neu. Höhere Gewichte zwingen den Klassifikator, mehr Betonung auf diese Punkte zu legen.
- Gibt zurück:
- selfobject
Angepasster Schätzer.
Anmerkungen
Wenn X kein C-kontinuierliches Array ist, wird es kopiert.
- fit_predict(X, y=None, **kwargs)[Quelle]#
Führt die Anpassung an X durch und gibt Labels für X zurück.
Gibt -1 für Ausreißer und 1 für Inlier zurück.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Eingabestichproben.
- yIgnoriert
Wird nicht verwendet, ist aber aus Gründen der API-Konsistenz per Konvention vorhanden.
- **kwargsdict
Argumente, die an
fitübergeben werden sollen.Hinzugefügt in Version 1.4.
- Gibt zurück:
- yndarray der Form (n_samples,)
1 für Inlier, -1 für Ausreißer.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X)[Quelle]#
Führt die Klassifizierung für Samples in X durch.
Für ein Ein-Klassen-Modell wird +1 oder -1 zurückgegeben.
- Parameter:
- X{array-artig, spärs matrix} der Form (n_samples, n_features) oder (n_samples_test, n_samples_train)
Für kernel="precomputed" hat X die erwartete Form (n_samples_test, n_samples_train).
- Gibt zurück:
- y_predndarray von Form (n_samples,)
Klassenbezeichnungen für Samples in X.
- score_samples(X)[Quelle]#
Roh-Bewertungsfunktion der Samples.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Die Datenmatrix.
- Gibt zurück:
- score_samplesndarray der Form (n_samples,)
Gibt die (nicht verschobene) Bewertungsfunktion der Samples zurück.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') OneClassSVM[Quelle]#
Konfiguriert, ob Metadaten für die
fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anfitübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anfit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinfit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
Galeriebeispiele#
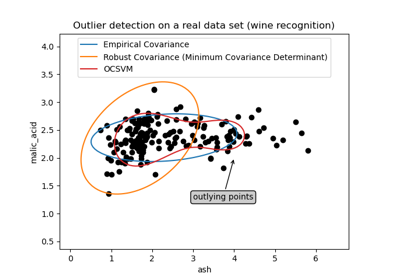
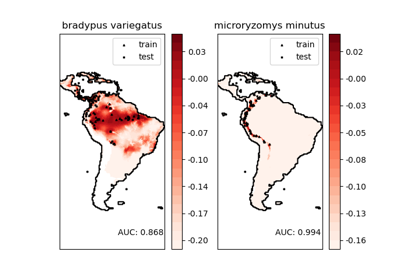
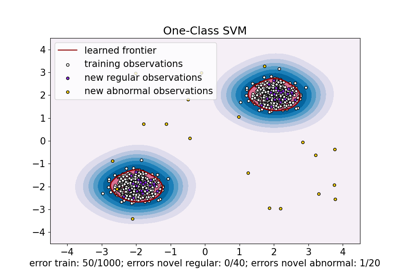
One-Class SVM vs. One-Class SVM mittels Stochastic Gradient Descent
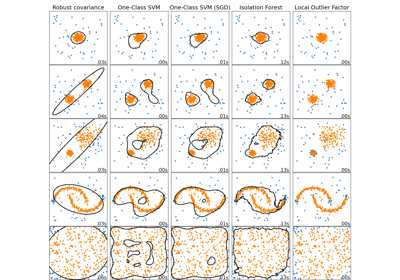
Vergleich von Anomalieerkennungsalgorithmen zur Ausreißererkennung auf Toy-Datensätzen