OneHotEncoder#
- class sklearn.preprocessing.OneHotEncoder(*, categories='auto', drop=None, sparse_output=True, dtype=<class 'numpy.float64'>, handle_unknown='error', min_frequency=None, max_categories=None, feature_name_combiner='concat')[Quelle]#
Kodiert kategoriale Merkmale als eine One-Hot-numerische Matrix.
Die Eingabe für diesen Transformer sollte ein Array-ähnliches Objekt aus ganzen Zahlen oder Zeichenketten sein, das die Werte bezeichnet, die von kategorialen (diskreten) Merkmalen angenommen werden. Die Merkmale werden mithilfe eines One-Hot- (auch „one-of-K“ oder „Dummy“-) Kodierungsschemas kodiert. Dies erstellt eine binäre Spalte für jede Kategorie und gibt eine sparse Matrix oder ein dichtes Array zurück (abhängig vom Parameter
sparse_output).Standardmäßig leitet der Encoder die Kategorien basierend auf den eindeutigen Werten in jedem Merkmal ab. Alternativ können Sie die
categoriesauch manuell angeben.Diese Kodierung ist erforderlich, um kategoriale Daten an viele scikit-learn-Schätzer zu übergeben, insbesondere an lineare Modelle und SVMs mit den Standardkernen.
Hinweis: Für die One-Hot-Kodierung von y-Labels sollten Sie stattdessen einen LabelBinarizer verwenden.
Lesen Sie mehr im Benutzerhandbuch. Für einen Vergleich verschiedener Encoder siehe: Vergleich des Target Encoders mit anderen Encodern.
- Parameter:
- categories„auto“ oder eine Liste von array-ähnlichen Objekten, Standard=„auto“
Kategorien (eindeutige Werte) pro Merkmal
„auto“ : Kategorien automatisch aus den Trainingsdaten ableiten.
list :
categories[i]enthält die Kategorien, die in der i-ten Spalte erwartet werden. Die übergebenen Kategorien sollten keine Strings und numerische Werte innerhalb eines einzelnen Merkmals mischen und bei numerischen Werten sortiert sein.
Die verwendeten Kategorien finden Sie im Attribut
categories_.Hinzugefügt in Version 0.20.
- drop{‚first‘, ‚if_binary‘} oder ein Array-ähnliches Objekt der Form (n_features,), Standard=None
Gibt eine Methodik zur Entfernung einer Kategorie pro Merkmal an. Dies ist nützlich in Situationen, in denen perfekt kollineare Merkmale Probleme verursachen, z. B. beim Übergeben der resultierenden Daten an ein nicht reguliertes lineares Regressionsmodell.
Das Entfernen einer Kategorie bricht jedoch die Symmetrie der ursprünglichen Darstellung und kann daher zu Verzerrungen in nachgelagerten Modellen führen, z. B. für strafende lineare Klassifizierungs- oder Regressionsmodelle.
None : Alle Merkmale beibehalten (Standard).
„first“ : Die erste Kategorie in jedem Merkmal entfernen. Wenn nur eine Kategorie vorhanden ist, wird das Merkmal vollständig entfernt.
„if_binary“ : Die erste Kategorie in jedem Merkmal mit zwei Kategorien entfernen. Merkmale mit 1 oder mehr als 2 Kategorien bleiben unverändert.
array :
drop[i]ist die Kategorie im MerkmalX[:, i], die entfernt werden soll.
Wenn
max_categoriesodermin_frequencykonfiguriert ist, um seltene Kategorien zu gruppieren, wird das Verhalten beim Entfernen nach der Gruppierung behandelt.Hinzugefügt in Version 0.21: Der Parameter
dropwurde in 0.21 hinzugefügt.Geändert in Version 0.23: Die Option
drop='if_binary'wurde in 0.23 hinzugefügt.Geändert in Version 1.1: Unterstützung für das Entfernen seltener Kategorien.
- sparse_outputbool, Standard=True
Wenn
True, wird einescipy.sparse.csr_matrix, d. h. eine sparse Matrix im Format „Compressed Sparse Row“ (CSR), zurückgegeben.Hinzugefügt in Version 1.2:
sparsewurde insparse_outputumbenannt.- dtypenumerischer Typ, Standard=np.float64
Gewünschter Datentyp der Ausgabe.
- handle_unknown{‚error‘, ‚ignore‘, ‚infrequent_if_exist‘, ‚warn‘}, Standard=„error“
Gibt die Art und Weise an, wie unbekannte Kategorien während der
transformbehandelt werden.„error“ : Löst einen Fehler aus, wenn während der Transformation eine unbekannte Kategorie vorhanden ist.
„ignore“ : Wenn während der Transformation eine unbekannte Kategorie angetroffen wird, sind die resultierenden One-Hot-kodierten Spalten für dieses Merkmal alle Nullen. Bei der inversen Transformation wird eine unbekannte Kategorie als None dargestellt.
„infrequent_if_exist“ : Wenn während der Transformation eine unbekannte Kategorie angetroffen wird, werden die resultierenden One-Hot-kodierten Spalten für dieses Merkmal auf die seltene Kategorie abgebildet, falls diese vorhanden ist. Die seltene Kategorie wird an die letzte Position in der Kodierung abgebildet. Bei der inversen Transformation wird eine unbekannte Kategorie auf die Kategorie abgebildet, die als
'infrequent'bezeichnet wird, falls diese vorhanden ist. Wenn die Kategorie'infrequent'nicht existiert, dann verhält sichtransformundinverse_transformbei einer unbekannten Kategorie wie beihandle_unknown='ignore'. Seltene Kategorien existieren basierend aufmin_frequencyundmax_categories. Lesen Sie mehr im Benutzerhandbuch.„warn“ : Wenn während der Transformation eine unbekannte Kategorie angetroffen wird, wird eine Warnung ausgegeben und die Kodierung wird dann wie für
handle_unknown="infrequent_if_exist"beschrieben fortgesetzt.
Geändert in Version 1.1:
'infrequent_if_exist'wurde hinzugefügt, um unbekannte und seltene Kategorien automatisch zu behandeln.Hinzugefügt in Version 1.6: Die Option
"warn"wurde in 1.6 hinzugefügt.- min_frequencyint oder float, Standard=None
Gibt die Mindesthäufigkeit an, unter der eine Kategorie als selten betrachtet wird.
Wenn
int, werden Kategorien mit einer geringeren Kardinalität als selten betrachtet.Wenn
float, werden Kategorien mit einer geringeren Kardinalität alsmin_frequency * n_samplesals selten betrachtet.
Hinzugefügt in Version 1.1: Lesen Sie mehr im Benutzerhandbuch.
- max_categoriesint, Standard=None
Gibt eine Obergrenze für die Anzahl der Ausgabemerkmale für jedes Eingabemerkmale unter Berücksichtigung seltener Kategorien an. Wenn es seltene Kategorien gibt, enthält
max_categoriesdie Kategorie, die die seltenen Kategorien repräsentiert, zusammen mit den häufigen Kategorien. WennNone, gibt es keine Begrenzung der Anzahl der Ausgabemerkmale.Hinzugefügt in Version 1.1: Lesen Sie mehr im Benutzerhandbuch.
- feature_name_combiner„concat“ oder aufrufbar, Standard=„concat“
Aufrufbar mit der Signatur
def callable(input_feature, category), die eine Zeichenkette zurückgibt. Dies wird verwendet, um Merkmalsnamen zu erstellen, die vonget_feature_names_outzurückgegeben werden."concat"verkettet den kodierten Merkmalsnamen und die Kategorie mitfeature + "_" + str(category). Z. B. Merkmal X mit den Werten 1, 6, 7 erstellt die MerkmalsnamenX_1, X_6, X_7.Hinzugefügt in Version 1.3.
- Attribute:
- categories_Liste von Arrays
Die Kategorien jedes Merkmals, die während des Fits bestimmt wurden (in der Reihenfolge der Merkmale in X und entsprechend der Ausgabe von
transform). Dies schließt die indropangegebene Kategorie (falls vorhanden) ein.- drop_idx_Array der Form (n_features,)
drop_idx_[i]ist der Index incategories_[i]der Kategorie, die für jedes Merkmal entfernt werden soll.drop_idx_[i] = None, wenn keine Kategorie aus dem Merkmal mit Indexientfernt werden soll, z. B. wenndrop='if_binary'und das Merkmal nicht binär ist.drop_idx_ = None, wenn alle transformierten Merkmale beibehalten werden.
Wenn seltene Kategorien durch Setzen von
min_frequencyodermax_categoriesauf einen nicht standardmäßigen Wert aktiviert werden unddrop_idx[i]einer seltenen Kategorie entspricht, wird die gesamte seltene Kategorie entfernt.Geändert in Version 0.23: Möglichkeit hinzugefügt,
None-Werte zu enthalten.infrequent_categories_Liste von ndarraysSeltene Kategorien für jedes Merkmal.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 1.0.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
- feature_name_combineraufrufbar oder None
Aufrufbar mit der Signatur
def callable(input_feature, category), die eine Zeichenkette zurückgibt. Dies wird verwendet, um Merkmalsnamen zu erstellen, die vonget_feature_names_outzurückgegeben werden.Hinzugefügt in Version 1.3.
Siehe auch
OrdinalEncoderFührt eine ordinale (ganzzahlige) Kodierung der kategorialen Merkmale durch.
TargetEncoderKodiert kategoriale Merkmale anhand des Ziels.
sklearn.feature_extraction.DictVectorizerFührt eine One-Hot-Kodierung von Wörterbucheinträgen durch (behandelt auch Merkmale mit Zeichenkettenwerten).
sklearn.feature_extraction.FeatureHasherFührt eine ungefähre One-Hot-Kodierung von Wörterbucheinträgen oder Zeichenketten durch.
LabelBinarizerBinarisiert Labels im One-vs-All-Verfahren.
MultiLabelBinarizerTransformiert zwischen iterierbaren Objekten und einem Multilabel-Format, z. B. einer binären Matrix (Samples x Klassen), die das Vorhandensein eines Klassenlabels anzeigt.
Beispiele
Gegeben sei ein Datensatz mit zwei Merkmalen. Wir lassen den Encoder die eindeutigen Werte pro Merkmal finden und die Daten in eine binäre One-Hot-Kodierung transformieren.
>>> from sklearn.preprocessing import OneHotEncoder
Man kann Kategorien, die während
fitnicht gesehen wurden, verwerfen.>>> enc = OneHotEncoder(handle_unknown='ignore') >>> X = [['Male', 1], ['Female', 3], ['Female', 2]] >>> enc.fit(X) OneHotEncoder(handle_unknown='ignore') >>> enc.categories_ [array(['Female', 'Male'], dtype=object), array([1, 2, 3], dtype=object)] >>> enc.transform([['Female', 1], ['Male', 4]]).toarray() array([[1., 0., 1., 0., 0.], [0., 1., 0., 0., 0.]]) >>> enc.inverse_transform([[0, 1, 1, 0, 0], [0, 0, 0, 1, 0]]) array([['Male', 1], [None, 2]], dtype=object) >>> enc.get_feature_names_out(['gender', 'group']) array(['gender_Female', 'gender_Male', 'group_1', 'group_2', 'group_3'], ...)
Man kann immer die erste Spalte für jedes Merkmal entfernen.
>>> drop_enc = OneHotEncoder(drop='first').fit(X) >>> drop_enc.categories_ [array(['Female', 'Male'], dtype=object), array([1, 2, 3], dtype=object)] >>> drop_enc.transform([['Female', 1], ['Male', 2]]).toarray() array([[0., 0., 0.], [1., 1., 0.]])
Oder eine Spalte für Merkmale entfernen, die nur 2 Kategorien haben.
>>> drop_binary_enc = OneHotEncoder(drop='if_binary').fit(X) >>> drop_binary_enc.transform([['Female', 1], ['Male', 2]]).toarray() array([[0., 1., 0., 0.], [1., 0., 1., 0.]])
Man kann die Art und Weise ändern, wie Merkmalsnamen erstellt werden.
>>> def custom_combiner(feature, category): ... return str(feature) + "_" + type(category).__name__ + "_" + str(category) >>> custom_fnames_enc = OneHotEncoder(feature_name_combiner=custom_combiner).fit(X) >>> custom_fnames_enc.get_feature_names_out() array(['x0_str_Female', 'x0_str_Male', 'x1_int_1', 'x1_int_2', 'x1_int_3'], dtype=object)
Seltene Kategorien werden durch Setzen von
max_categoriesodermin_frequencyaktiviert.>>> import numpy as np >>> X = np.array([["a"] * 5 + ["b"] * 20 + ["c"] * 10 + ["d"] * 3], dtype=object).T >>> ohe = OneHotEncoder(max_categories=3, sparse_output=False).fit(X) >>> ohe.infrequent_categories_ [array(['a', 'd'], dtype=object)] >>> ohe.transform([["a"], ["b"]]) array([[0., 0., 1.], [1., 0., 0.]])
- fit(X, y=None)[Quelle]#
OneHotEncoder an X anpassen.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Die Daten zur Ermittlung der Kategorien jedes Merkmals.
- yNone
Ignoriert. Dieser Parameter existiert nur zur Kompatibilität mit
Pipeline.
- Gibt zurück:
- self
Angepasster Encoder.
- fit_transform(X, y=None, **fit_params)[Quelle]#
An Daten anpassen, dann transformieren.
Passt den Transformer an
Xundymit optionalen Parameternfit_paramsan und gibt eine transformierte Version vonXzurück.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Eingabestichproben.
- yarray-like der Form (n_samples,) oder (n_samples, n_outputs), Standardwert=None
Zielwerte (None für unüberwachte Transformationen).
- **fit_paramsdict
Zusätzliche Fit-Parameter. Nur übergeben, wenn der Estimator zusätzliche Parameter in seiner
fit-Methode akzeptiert.
- Gibt zurück:
- X_newndarray array der Form (n_samples, n_features_new)
Transformiertes Array.
- get_feature_names_out(input_features=None)[Quelle]#
Holt die Ausgabemerkmale für die Transformation.
- Parameter:
- input_featuresarray-like von str oder None, default=None
Eingabemerkmale.
Wenn
input_featuresNoneist, werdenfeature_names_in_als Merkmalnamen verwendet. Wennfeature_names_in_nicht definiert ist, werden die folgenden Eingabemerkmalsnamen generiert:["x0", "x1", ..., "x(n_features_in_ - 1)"].Wenn
input_featuresein Array-ähnliches Objekt ist, mussinput_featuresmitfeature_names_in_übereinstimmen, wennfeature_names_in_definiert ist.
- Gibt zurück:
- feature_names_outndarray von str-Objekten
Transformierte Merkmalnamen.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- inverse_transform(X)[Quelle]#
Wandelt die Daten in die ursprüngliche Darstellung zurück.
Wenn unbekannte Kategorien angetroffen werden (alle Nullen in der One-Hot-Kodierung), wird
Noneverwendet, um diese Kategorie darzustellen. Wenn das Merkmal mit der unbekannten Kategorie eine entfernte Kategorie hat, wird die entfernte Kategorie seine Inverse sein.Für ein gegebenes Eingabemerkmal wird, wenn eine seltene Kategorie vorhanden ist, ‚infrequent_sklearn‘ verwendet, um die seltene Kategorie darzustellen.
- Parameter:
- X{array-ähnlich, sparse matrix} der Form (n_samples, n_encoded_features)
Die transformierten Daten.
- Gibt zurück:
- X_originalndarray von der Form (n_samples, n_features)
Invers transformiertes Array.
- set_output(*, transform=None)[Quelle]#
Ausgabecontainer festlegen.
Siehe Einführung in die set_output API für ein Beispiel zur Verwendung der API.
- Parameter:
- transform{“default”, “pandas”, “polars”}, default=None
Konfiguriert die Ausgabe von
transformundfit_transform."default": Standardausgabeformat eines Transformers"pandas": DataFrame-Ausgabe"polars": Polars-AusgabeNone: Die Transformationskonfiguration bleibt unverändert
Hinzugefügt in Version 1.4: Die Option
"polars"wurde hinzugefügt.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- transform(X)[Quelle]#
X mit One-Hot-Kodierung transformieren.
Wenn
sparse_output=True(Standard), wird eine Instanz vonscipy.sparse._csr.csr_matrix(CSR-Format) zurückgegeben.Wenn es für ein Merkmal seltene Kategorien gibt, die durch Angabe von
max_categoriesodermin_frequencyfestgelegt wurden, werden die seltenen Kategorien zu einer einzigen Kategorie zusammengefasst.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Die zu kodierenden Daten.
- Gibt zurück:
- X_out{ndarray, sparse matrix} der Form (n_samples, n_encoded_features)
Transformierte Eingabe. Wenn
sparse_output=True, wird eine sparse Matrix zurückgegeben.
Galeriebeispiele#
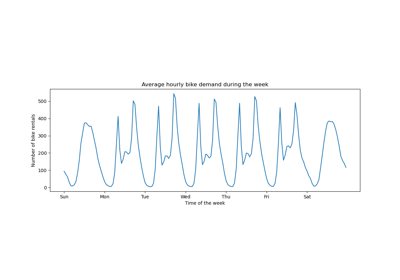

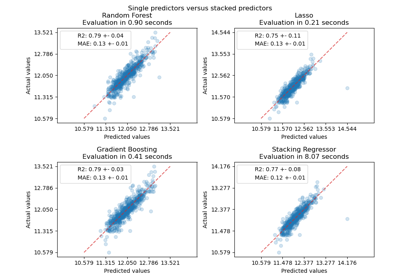
Unterstützung für kategorische Merkmale in Gradient Boosting
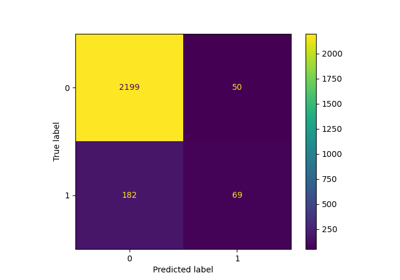
Häufige Fallstricke bei der Interpretation von Koeffizienten linearer Modelle

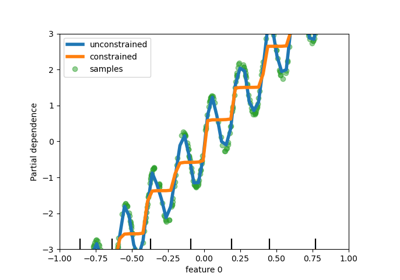
Partial Dependence und Individual Conditional Expectation Plots

Poisson-Regression und nicht-normale Verlustfunktion