Hinweis
Gehen Sie zum Ende, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Kombinieren von Prädiktoren mit Stacking#
Stacking bezieht sich auf eine Methode, um Estimators zu vermischen. Bei dieser Strategie werden einige Estimators individuell auf Trainingsdaten angepasst, während ein endgültiger Estimator mithilfe der gestackten Vorhersagen dieser Basis-Estimators trainiert wird.
In diesem Beispiel veranschaulichen wir den Anwendungsfall, bei dem verschiedene Regressoren zusammen gestapelt werden und ein endgültiger linearer, bestrafter Regressor zur Ausgabe der Vorhersage verwendet wird. Wir vergleichen die Leistung jedes einzelnen Regressors mit der Stacking-Strategie. Stacking verbessert die Gesamtleistung geringfügig.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Datensatz herunterladen#
Wir verwenden den Ames Housing-Datensatz, der zuerst von Dean De Cock zusammengestellt und nach seiner Verwendung in einer Kaggle-Herausforderung bekannter wurde. Es handelt sich um eine Sammlung von 1460 Wohnhäusern in Ames, Iowa, die jeweils durch 80 Merkmale beschrieben werden. Wir werden ihn verwenden, um den endgültigen logarithmischen Preis der Häuser vorherzusagen. In diesem Beispiel werden nur die 20 interessantesten Merkmale verwendet, die mithilfe von GradientBoostingRegressor() ausgewählt wurden, und die Anzahl der Einträge begrenzt (hier gehen wir nicht ins Detail, wie die interessantesten Merkmale ausgewählt werden).
Der Ames Housing-Datensatz wird nicht mit scikit-learn mitgeliefert, daher werden wir ihn von OpenML abrufen.
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.utils import shuffle
def load_ames_housing():
df = fetch_openml(name="house_prices", as_frame=True)
X = df.data
y = df.target
features = [
"YrSold",
"HeatingQC",
"Street",
"YearRemodAdd",
"Heating",
"MasVnrType",
"BsmtUnfSF",
"Foundation",
"MasVnrArea",
"MSSubClass",
"ExterQual",
"Condition2",
"GarageCars",
"GarageType",
"OverallQual",
"TotalBsmtSF",
"BsmtFinSF1",
"HouseStyle",
"MiscFeature",
"MoSold",
]
X = X.loc[:, features]
X, y = shuffle(X, y, random_state=0)
X = X.iloc[:600]
y = y.iloc[:600]
return X, np.log(y)
X, y = load_ames_housing()
Pipeline zur Vorverarbeitung der Daten erstellen#
Bevor wir den Ames-Datensatz verwenden können, müssen wir noch einige Vorverarbeitungsschritte durchführen. Zuerst wählen wir die kategorialen und numerischen Spalten des Datensatzes aus, um den ersten Schritt der Pipeline zu konstruieren.
from sklearn.compose import make_column_selector
cat_selector = make_column_selector(dtype_include=[object, "string"])
num_selector = make_column_selector(dtype_include=np.number)
cat_selector(X)
['HeatingQC', 'Street', 'Heating', 'MasVnrType', 'Foundation', 'ExterQual', 'Condition2', 'GarageType', 'HouseStyle', 'MiscFeature']
num_selector(X)
['YrSold', 'YearRemodAdd', 'BsmtUnfSF', 'MasVnrArea', 'MSSubClass', 'GarageCars', 'OverallQual', 'TotalBsmtSF', 'BsmtFinSF1', 'MoSold']
Anschließend müssen wir Vorverarbeitungs-Pipelines entwerfen, die vom endgültigen Regressor abhängen. Wenn der endgültige Regressor ein lineares Modell ist, muss man die Kategorien per One-Hot-Encoding kodieren. Wenn der endgültige Regressor ein baumbasiertes Modell ist, reicht ein ordinaler Encoder aus. Außerdem müssen numerische Werte für ein lineares Modell standardisiert werden, während die rohen numerischen Daten von einem baumbasierten Modell unverändert behandelt werden können. Beide Modelle benötigen jedoch einen Imputer zur Behandlung fehlender Werte.
Wir entwerfen zunächst die Pipeline, die für baumbasierte Modelle erforderlich ist.
from sklearn.compose import make_column_transformer
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OrdinalEncoder
cat_tree_processor = OrdinalEncoder(
handle_unknown="use_encoded_value",
unknown_value=-1,
encoded_missing_value=-2,
)
num_tree_processor = SimpleImputer(strategy="mean", add_indicator=True)
tree_preprocessor = make_column_transformer(
(num_tree_processor, num_selector), (cat_tree_processor, cat_selector)
)
tree_preprocessor
ColumnTransformer(transformers=[('simpleimputer',
SimpleImputer(add_indicator=True),
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6d10>),
('ordinalencoder',
OrdinalEncoder(encoded_missing_value=-2,
handle_unknown='use_encoded_value',
unknown_value=-1),
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6010>)])In einer Jupyter-Umgebung führen Sie diese Zelle bitte erneut aus, um die HTML-Darstellung anzuzeigen, oder vertrauen Sie dem Notebook.Auf GitHub kann die HTML-Darstellung nicht gerendert werden. Versuchen Sie bitte, diese Seite mit nbviewer.org zu laden.
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6d10>
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6010>
Parameter
Dann definieren wir nun den Präprozessor, der verwendet wird, wenn der endgültige Regressor ein lineares Modell ist.
from sklearn.preprocessing import OneHotEncoder, StandardScaler
cat_linear_processor = OneHotEncoder(handle_unknown="ignore")
num_linear_processor = make_pipeline(
StandardScaler(), SimpleImputer(strategy="mean", add_indicator=True)
)
linear_preprocessor = make_column_transformer(
(num_linear_processor, num_selector), (cat_linear_processor, cat_selector)
)
linear_preprocessor
ColumnTransformer(transformers=[('pipeline',
Pipeline(steps=[('standardscaler',
StandardScaler()),
('simpleimputer',
SimpleImputer(add_indicator=True))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6d10>),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6010>)])In einer Jupyter-Umgebung führen Sie diese Zelle bitte erneut aus, um die HTML-Darstellung anzuzeigen, oder vertrauen Sie dem Notebook.Auf GitHub kann die HTML-Darstellung nicht gerendert werden. Versuchen Sie bitte, diese Seite mit nbviewer.org zu laden.
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6d10>
Parameter
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6010>
Parameter
Stack von Prädiktoren auf einem einzelnen Datensatz#
Es ist manchmal mühsam, das Modell zu finden, das auf einem gegebenen Datensatz am besten abschneidet. Stacking bietet eine Alternative, indem es die Ausgaben mehrerer Lerner kombiniert, ohne dass ein Modell speziell ausgewählt werden muss. Die Leistung des Stackings liegt normalerweise nahe am besten Modell und kann manchmal die Vorhersageleistung jedes einzelnen Modells übertreffen.
Hier kombinieren wir 3 Lerner (linear und nicht-linear) und verwenden einen Ridge-Regressor, um ihre Ausgaben zu kombinieren.
Hinweis
Obwohl wir neue Pipelines mit den Präprozessoren erstellen, die wir im vorherigen Abschnitt für die 3 Lerner geschrieben haben, benötigt der endgültige Estimator RidgeCV() keine Vorverarbeitung der Daten, da er mit der bereits vorverarbeiteten Ausgabe der 3 Lerner gespeist wird.
from sklearn.linear_model import LassoCV
lasso_pipeline = make_pipeline(linear_preprocessor, LassoCV())
lasso_pipeline
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('pipeline',
Pipeline(steps=[('standardscaler',
StandardScaler()),
('simpleimputer',
SimpleImputer(add_indicator=True))]),
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6d10>),
('onehotencoder',
OneHotEncoder(handle_unknown='ignore'),
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6010>)])),
('lassocv', LassoCV())])In einer Jupyter-Umgebung führen Sie diese Zelle bitte erneut aus, um die HTML-Darstellung anzuzeigen, oder vertrauen Sie dem Notebook.Auf GitHub kann die HTML-Darstellung nicht gerendert werden. Versuchen Sie bitte, diese Seite mit nbviewer.org zu laden.
Parameter
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6d10>
Parameter
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6010>
Parameter
Parameter
from sklearn.ensemble import RandomForestRegressor
rf_pipeline = make_pipeline(tree_preprocessor, RandomForestRegressor(random_state=42))
rf_pipeline
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('simpleimputer',
SimpleImputer(add_indicator=True),
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6d10>),
('ordinalencoder',
OrdinalEncoder(encoded_missing_value=-2,
handle_unknown='use_encoded_value',
unknown_value=-1),
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6010>)])),
('randomforestregressor',
RandomForestRegressor(random_state=42))])In einer Jupyter-Umgebung führen Sie diese Zelle bitte erneut aus, um die HTML-Darstellung anzuzeigen, oder vertrauen Sie dem Notebook.Auf GitHub kann die HTML-Darstellung nicht gerendert werden. Versuchen Sie bitte, diese Seite mit nbviewer.org zu laden.
Parameter
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6d10>
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6010>
Parameter
Parameter
from sklearn.ensemble import HistGradientBoostingRegressor
gbdt_pipeline = make_pipeline(
tree_preprocessor, HistGradientBoostingRegressor(random_state=0)
)
gbdt_pipeline
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('simpleimputer',
SimpleImputer(add_indicator=True),
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6d10>),
('ordinalencoder',
OrdinalEncoder(encoded_missing_value=-2,
handle_unknown='use_encoded_value',
unknown_value=-1),
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6010>)])),
('histgradientboostingregressor',
HistGradientBoostingRegressor(random_state=0))])In einer Jupyter-Umgebung führen Sie diese Zelle bitte erneut aus, um die HTML-Darstellung anzuzeigen, oder vertrauen Sie dem Notebook.Auf GitHub kann die HTML-Darstellung nicht gerendert werden. Versuchen Sie bitte, diese Seite mit nbviewer.org zu laden.
Parameter
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6d10>
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6010>
Parameter
Parameter
from sklearn.ensemble import StackingRegressor
from sklearn.linear_model import RidgeCV
estimators = [
("Random Forest", rf_pipeline),
("Lasso", lasso_pipeline),
("Gradient Boosting", gbdt_pipeline),
]
stacking_regressor = StackingRegressor(estimators=estimators, final_estimator=RidgeCV())
stacking_regressor
StackingRegressor(estimators=[('Random Forest',
Pipeline(steps=[('columntransformer',
ColumnTransformer(transformers=[('simpleimputer',
SimpleImputer(add_indicator=True),
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6d10>),
('ordinalencoder',
OrdinalEncoder(encoded_missing_value=-2,
handle_unknown='use_encoded_value',
unknown_v...
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6d10>),
('ordinalencoder',
OrdinalEncoder(encoded_missing_value=-2,
handle_unknown='use_encoded_value',
unknown_value=-1),
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6010>)])),
('histgradientboostingregressor',
HistGradientBoostingRegressor(random_state=0))]))],
final_estimator=RidgeCV())In einer Jupyter-Umgebung führen Sie diese Zelle bitte erneut aus, um die HTML-Darstellung anzuzeigen, oder vertrauen Sie dem Notebook.Auf GitHub kann die HTML-Darstellung nicht gerendert werden. Versuchen Sie bitte, diese Seite mit nbviewer.org zu laden.
Parameter
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6d10>
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6010>
Parameter
Parameter
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6d10>
Parameter
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6010>
Parameter
Parameter
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6d10>
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4868f6010>
Parameter
Parameter
Parameter
Ergebnisse messen und plotten#
Jetzt können wir den Ames Housing-Datensatz verwenden, um Vorhersagen zu treffen. Wir prüfen die Leistung jedes einzelnen Prädiktors sowie des Stacks der Regressoren.
import time
import matplotlib.pyplot as plt
from sklearn.metrics import PredictionErrorDisplay
from sklearn.model_selection import cross_val_predict, cross_validate
fig, axs = plt.subplots(2, 2, figsize=(9, 7))
axs = np.ravel(axs)
for ax, (name, est) in zip(
axs, estimators + [("Stacking Regressor", stacking_regressor)]
):
scorers = {"R2": "r2", "MAE": "neg_mean_absolute_error"}
start_time = time.time()
scores = cross_validate(
est, X, y, scoring=list(scorers.values()), n_jobs=-1, verbose=0
)
elapsed_time = time.time() - start_time
y_pred = cross_val_predict(est, X, y, n_jobs=-1, verbose=0)
scores = {
key: (
f"{np.abs(np.mean(scores[f'test_{value}'])):.2f} +- "
f"{np.std(scores[f'test_{value}']):.2f}"
)
for key, value in scorers.items()
}
display = PredictionErrorDisplay.from_predictions(
y_true=y,
y_pred=y_pred,
kind="actual_vs_predicted",
ax=ax,
scatter_kwargs={"alpha": 0.2, "color": "tab:blue"},
line_kwargs={"color": "tab:red"},
)
ax.set_title(f"{name}\nEvaluation in {elapsed_time:.2f} seconds")
for name, score in scores.items():
ax.plot([], [], " ", label=f"{name}: {score}")
ax.legend(loc="upper left")
plt.suptitle("Single predictors versus stacked predictors")
plt.tight_layout()
plt.subplots_adjust(top=0.9)
plt.show()
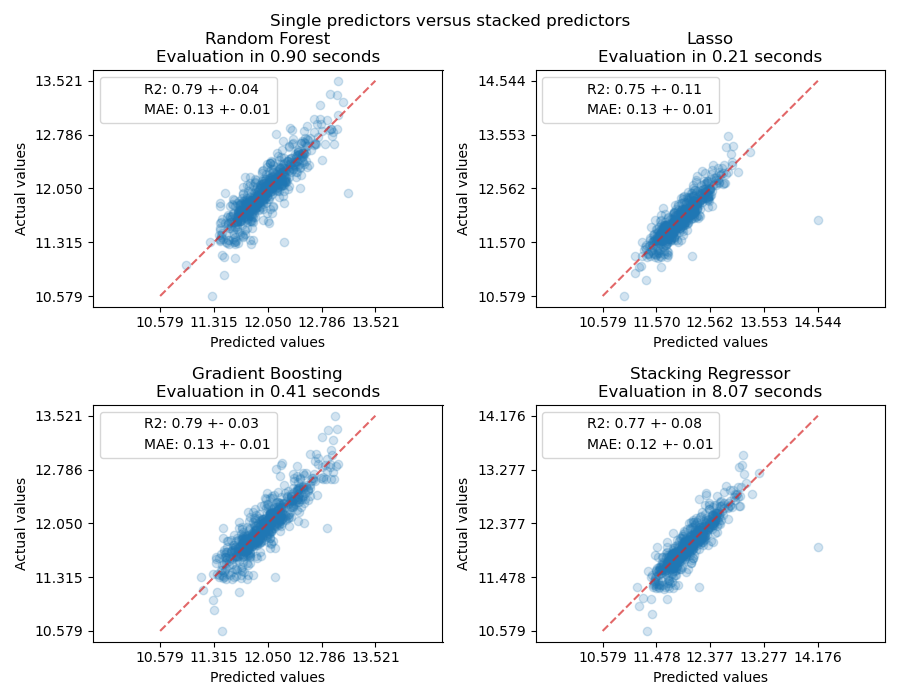
Der gestapelte Regressor kombiniert die Stärken der verschiedenen Regressoren. Wir sehen jedoch auch, dass das Trainieren des gestapelten Regressors wesentlich rechenintensiver ist.
Gesamtlaufzeit des Skripts: (0 Minuten 19,441 Sekunden)
Verwandte Beispiele
Vorhersagen von einzelnen und abstimmenden Regressionsmodellen plotten


Unterstützung für kategorische Merkmale in Gradient Boosting