RidgeCV#
- class sklearn.linear_model.RidgeCV(alphas=(0.1, 1.0, 10.0), *, fit_intercept=True, scoring=None, cv=None, gcv_mode=None, store_cv_results=False, alpha_per_target=False)[Quelle]#
Ridge-Regression mit integrierter Kreuzvalidierung.
Siehe Glossareintrag für Cross-validation-Schätzer.
Standardmäßig führt es eine effiziente Leave-One-Out-Kreuzvalidierung durch.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- alphasarray-like von shape (n_alphas,), default=(0.1, 1.0, 10.0)
Array von zu versuchenden Alpha-Werten. Regularisierungsstärke; muss eine positive Gleitkommazahl sein. Regularisierung verbessert die Konditionierung des Problems und reduziert die Varianz der Schätzungen. Größere Werte spezifizieren stärkere Regularisierung. Alpha entspricht
1 / (2C)in anderen linearen Modellen wieLogisticRegressionoderLinearSVC. Bei Verwendung der Leave-One-Out-Kreuzvalidierung müssen alphas strikt positiv sein.- fit_interceptbool, Standardwert=True
Ob für dieses Modell ein Achsenabschnitt berechnet werden soll. Wenn auf False gesetzt, wird kein Achsenabschnitt in Berechnungen verwendet (d.h. die Daten werden als zentriert erwartet).
- scoringstr, callable, default=None
Die verwendete Scoring-Methode für die Kreuzvalidierung. Optionen
str: siehe Zeichenkettennamen für Bewerter für Optionen.
callable: Ein Scorer-Callable-Objekt (z. B. Funktion) mit der Signatur
scorer(estimator, X, y). Siehe Callable Scorer für Details.None: negativer mittlerer quadratischer Fehler, wenn cv None ist (d.h. wenn Leave-One-Out-Kreuzvalidierung verwendet wird), oder Bestimmtheitsmaß (\(R^2\)) andernfalls.
- cvint, Kreuzvalidierungsgenerator oder iterierbar, Standardwert=None
Bestimmt die Strategie der Kreuzvalidierungsaufteilung. Mögliche Eingaben für cv sind
None, um die effiziente Leave-One-Out-Kreuzvalidierung zu verwenden
Ganzzahl, um die Anzahl der Folds anzugeben.
Eine iterierbare Liste, die (Trainings-, Test-) Splits als Indizes-Arrays liefert.
Für Ganzzahl-/None-Eingaben wird, wenn
ybinär oder multiklass ist,StratifiedKFoldverwendet, andernfallsKFoldverwendet.Siehe Benutzerhandbuch für die verschiedenen Kreuzvalidierungsstrategien, die hier verwendet werden können.
- gcv_mode{‘auto’, ‘svd’, ‘eigen’}, default=’auto’
Flag, das angibt, welche Strategie bei der Durchführung der Leave-One-Out-Kreuzvalidierung verwendet werden soll. Optionen sind
'auto' : use 'svd' if n_samples > n_features, otherwise use 'eigen' 'svd' : force use of singular value decomposition of X when X is dense, eigenvalue decomposition of X^T.X when X is sparse. 'eigen' : force computation via eigendecomposition of X.X^T
Der 'auto'-Modus ist der Standard und soll die günstigere der beiden Optionen je nach Form der Trainingsdaten auswählen.
- store_cv_resultsbool, default=False
Flag, das angibt, ob die Kreuzvalidierungswerte, die jedem Alpha entsprechen, im Attribut
cv_results_(siehe unten) gespeichert werden sollen. Dieses Flag ist nur mitcv=None(d.h. Verwendung der Leave-One-Out-Kreuzvalidierung) kompatibel.Geändert in Version 1.5: Parametername von
store_cv_valueszustore_cv_resultsgeändert.- alpha_per_targetbool, default=False
Flag, das angibt, ob der Alpha-Wert (aus der Parameterliste
alphasausgewählt) für jedes Ziel separat optimiert werden soll (bei Multi-Output-Einstellungen: mehrere Vorhersageziele). Wenn aufTruegesetzt, enthält das Attributalpha_nach dem Fitting einen Wert für jedes Ziel. Wenn aufFalsegesetzt, wird ein einzelnes Alpha für alle Ziele verwendet.Hinzugefügt in Version 0.24.
- Attribute:
- cv_results_ndarray von shape (n_samples, n_alphas) oder shape (n_samples, n_targets, n_alphas), optional
Kreuzvalidierungswerte für jedes Alpha (nur verfügbar, wenn
store_cv_results=Trueundcv=None). Nach Aufruf vonfit()enthält dieses Attribut die mittleren quadratischen Fehler, wennscoring is None, andernfalls enthält es standardisierte Vorhersagewerte pro Punkt.Geändert in Version 1.5:
cv_values_wurde zucv_results_geändert.- coef_ndarray von shape (n_features) oder (n_targets, n_features)
Gewichtsvektor(en).
- intercept_float oder ndarray der Form (n_targets,)
Unabhängiger Term in der Entscheidungsfunktion. Auf 0.0 gesetzt, wenn
fit_intercept = False.- alpha_float oder ndarray von shape (n_targets,)
Geschätzter Regularisierungsparameter oder, wenn
alpha_per_target=True, der geschätzte Regularisierungsparameter für jedes Ziel.- best_score_float oder ndarray von shape (n_targets,)
Punktzahl des Basis-Estimators mit dem besten Alpha oder, wenn
alpha_per_target=True, eine Punktzahl für jedes Ziel.Hinzugefügt in Version 0.23.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
Siehe auch
RidgeRidge-Regression.
RidgeClassifierKlassifikator basierend auf Ridge-Regression auf {-1, 1} Labels.
RidgeClassifierCVRidge-Klassifikator mit integrierter Kreuzvalidierung.
Beispiele
>>> from sklearn.datasets import load_diabetes >>> from sklearn.linear_model import RidgeCV >>> X, y = load_diabetes(return_X_y=True) >>> clf = RidgeCV(alphas=[1e-3, 1e-2, 1e-1, 1]).fit(X, y) >>> clf.score(X, y) 0.5166...
- fit(X, y, sample_weight=None, **params)[Quelle]#
Ridge-Regressionsmodell mit cv anpassen.
- Parameter:
- Xndarray der Form (n_samples, n_features)
Trainingsdaten. Wenn GCV verwendet wird, wird es bei Bedarf in float64 umgewandelt.
- yndarray der Form (n_samples,) oder (n_samples, n_targets)
Zielwerte. Wird bei Bedarf in den Datentyp von X umgewandelt.
- sample_weightfloat oder ndarray der Form (n_samples,), default=None
Einzelne Gewichte für jede Stichprobe. Wenn eine Gleitkommazahl angegeben wird, hat jede Stichprobe das gleiche Gewicht.
- **paramsdict, default=None
An den zugrundeliegenden Scorings übergebene Parameter.
Hinzugefügt in Version 1.5: Nur verfügbar, wenn
enable_metadata_routing=Truegesetzt ist, was durch Verwendung vonsklearn.set_config(enable_metadata_routing=True)erfolgen kann. Weitere Details finden Sie in der Benutzerhandbuch für Metadaten-Routing.
- Gibt zurück:
- selfobject
Angepasster Schätzer.
Anmerkungen
Wenn sample_weight bereitgestellt wird, kann der ausgewählte Hyperparameter davon abhängen, ob wir Leave-One-Out-Kreuzvalidierung (cv=None) oder eine andere Form der Kreuzvalidierung verwenden, da nur die Leave-One-Out-Kreuzvalidierung die Stichprobengewichte bei der Berechnung des Validierungs-Scores berücksichtigt.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
Hinzugefügt in Version 1.5.
- Gibt zurück:
- routingMetadataRouter
Ein
MetadataRouter, der die Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X)[Quelle]#
Vorhersage mit dem linearen Modell.
- Parameter:
- Xarray-like oder sparse matrix, Form (n_samples, n_features)
Stichproben.
- Gibt zurück:
- Carray, Form (n_samples,)
Gibt vorhergesagte Werte zurück.
- score(X, y, sample_weight=None)[Quelle]#
Gibt den Bestimmtheitskoeffizienten auf Testdaten zurück.
Der Bestimmtheitskoeffizient, \(R^2\), ist definiert als \((1 - \frac{u}{v})\), wobei \(u\) die Summe der quadrierten Residuen ist
((y_true - y_pred)** 2).sum()und \(v\) die Summe der quadrierten Abweichungen vom Mittelwert ist((y_true - y_true.mean()) ** 2).sum(). Der bestmögliche Score ist 1.0 und er kann negativ sein (da das Modell beliebig schlechter sein kann). Ein konstantes Modell, das immer den Erwartungswert vonyvorhersagt, ohne die Eingabemerkmale zu berücksichtigen, würde einen \(R^2\)-Score von 0.0 erzielen.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben. Für einige Schätzer kann dies eine vorab berechnete Kernelmatrix oder eine Liste von generischen Objekten sein, stattdessen mit der Form
(n_samples, n_samples_fitted), wobein_samples_fitteddie Anzahl der für die Anpassung des Schätzers verwendeten Stichproben ist.- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Werte für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
\(R^2\) von
self.predict(X)bezogen aufy.
Anmerkungen
Der \(R^2\)-Score, der beim Aufruf von
scoreauf einem Regressor verwendet wird, nutzt von Version 0.23 anmultioutput='uniform_average', um konsistent mit dem Standardwert vonr2_scorezu sein. Dies beeinflusst diescore-Methode aller Multi-Output-Regressoren (mit Ausnahme vonMultiOutputRegressor).
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') RidgeCV[Quelle]#
Konfiguriert, ob Metadaten für die
fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anfitübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anfit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinfit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') RidgeCV[Quelle]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
Galeriebeispiele#

Auswirkung der Transformation der Ziele in einem Regressionsmodell
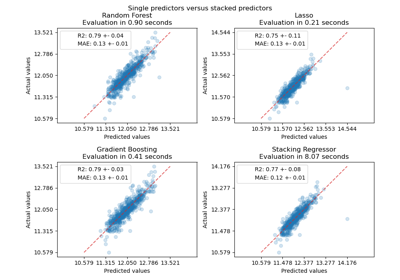
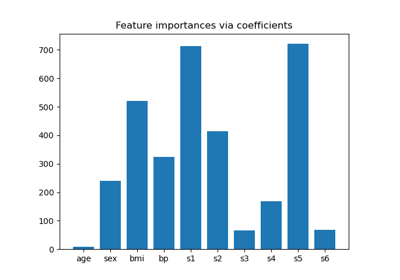

Häufige Fallstricke bei der Interpretation von Koeffizienten linearer Modelle

Gesichtsvervollständigung mit Multi-Output-Schätzern