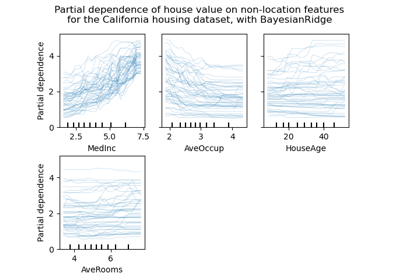
fetch_california_housing#
- sklearn.datasets.fetch_california_housing(*, data_home=None, download_if_missing=True, return_X_y=False, as_frame=False, n_retries=3, delay=1.0)[Quelle]#
Lädt den California Housing Datensatz (Regression).
Gesamtanzahl Samples
20640
Dimensionalität
8
Merkmale
real
Zielwert
real 0.15 - 5.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- data_homestr oder path-like, Standard=None
Geben Sie einen anderen Download- und Cache-Ordner für die Datensätze an. Standardmäßig werden alle scikit-learn-Daten in Unterordnern unter „~/scikit_learn_data“ gespeichert.
- download_if_missingbool, Standard=True
Wenn False, wird eine OSError ausgelöst, wenn die Daten nicht lokal verfügbar sind, anstatt zu versuchen, die Daten von der Quell-Website herunterzuladen.
- return_X_ybool, Standard=False
Wenn True, wird
(data.data, data.target)anstelle eines Bunch-Objekts zurückgegeben.Hinzugefügt in Version 0.20.
- as_framebool, default=False
Wenn True, sind die Daten ein pandas DataFrame, einschließlich Spalten mit geeigneten Datentypen (numerisch, Zeichenkette oder kategorisch). Der Zielwert ist ein pandas DataFrame oder eine Series, abhängig von der Anzahl der Zielspalten.
Hinzugefügt in Version 0.23.
- n_retriesint, Standard=3
Anzahl der Wiederholungsversuche bei HTTP-Fehlern.
Hinzugefügt in Version 1.5.
- delayfloat, Standard=1.0
Anzahl der Sekunden zwischen den Wiederholungsversuchen.
Hinzugefügt in Version 1.5.
- Gibt zurück:
- dataset
Bunch Dictionary-ähnliches Objekt mit den folgenden Attributen.
- datandarray, Form (20640, 8)
Jede Zeile entspricht den 8 Merkmalwerten in Reihenfolge. Wenn
as_frameTrue ist, istdataein pandas Objekt.- targetnumpy array der Form (20640,)
Jeder Wert entspricht dem Median des Hauswerts in Einheiten von 100.000. Wenn
as_frameTrue ist, isttargetein pandas Objekt.- feature_namesListe der Länge 8
Array von geordneten Merkmalnamen, die im Datensatz verwendet werden.
- DESCRstr
Beschreibung des kalifornischen Hausdatensatzes.
- framepandas DataFrame
Nur vorhanden, wenn
as_frame=True. DataFrame mitdataundtarget.Hinzugefügt in Version 0.23.
- (data, target)tuple, wenn
return_X_yTrue ist Ein Tupel aus zwei ndarrays. Das erste enthält ein 2D-Array der Form (n_samples, n_features), wobei jede Zeile eine Stichprobe und jede Spalte die Merkmale darstellt. Das zweite ndarray der Form (n_samples,) enthält die Zielstichproben.
Hinzugefügt in Version 0.20.
- dataset
Anmerkungen
Dieser Datensatz besteht aus 20.640 Stichproben und 9 Merkmalen.
Beispiele
>>> from sklearn.datasets import fetch_california_housing >>> housing = fetch_california_housing() >>> print(housing.data.shape, housing.target.shape) (20640, 8) (20640,) >>> print(housing.feature_names[0:6]) ['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup']
Galeriebeispiele#

Vergleich von Random Forests und Histogram Gradient Boosting Modellen


Fehlende Werte mit Varianten von IterativeImputer imputieren

Fehlende Werte imputieren, bevor ein Schätzer erstellt wird
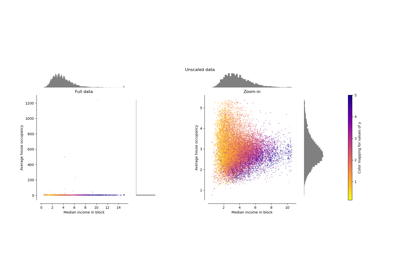
Vergleich der Auswirkungen verschiedener Skalierer auf Daten mit Ausreißern