LogisticRegressionCV#
- class sklearn.linear_model.LogisticRegressionCV(*, Cs=10, l1_ratios='warn', fit_intercept=True, cv=None, dual=False, penalty='deprecated', scoring=None, solver='lbfgs', tol=0.0001, max_iter=100, class_weight=None, n_jobs=None, verbose=0, refit=True, intercept_scaling=1.0, random_state=None, use_legacy_attributes='warn')[source]#
Logistische Regression CV (auch bekannt als Logit, MaxEnt) Klassifikator.
Siehe Glossareintrag für Cross-validation-Schätzer.
Diese Klasse implementiert regulierte logistische Regression mit impliziter Kreuzvalidierung für die Parameter
Cundl1_ratio, sieheLogisticRegression, unter Verwendung einer Reihe von verfügbaren Lösern.Die Löser ‘lbfgs’, ‘newton-cg’, ‘newton-cholesky’ und ‘sag’ unterstützen nur L2-Regularisierung mit primaler Formulierung. Der Löser ‘liblinear’ unterstützt sowohl L1- als auch L2-Regularisierung (aber nicht beides, d. h. Elastic-Net) mit einer dualen Formulierung nur für die L2-Strafe. Die Elastic-Net (Kombination aus L1 und L2) Regularisierung wird nur vom ‘saga’-Löser unterstützt.
Für das Gitter von
Cs-Werten undl1_ratios-Werten wird der beste Hyperparameter durch den KreuzvalidiererStratifiedKFoldausgewählt, kann aber über den cv-Parameter geändert werden. Alle Löser außer ‘liblinear’ können die Koeffizienten warm starten (siehe Glossar).Mehr dazu im Benutzerhandbuch.
- Parameter:
- Csint oder Liste von Floats, Standard=10
Jeder der Werte in Cs beschreibt den Kehrwert der Regularisierungsstärke. Wenn Cs eine Ganzzahl ist, wird ein Gitter von Cs-Werten in logarithmischer Skala zwischen 1e-4 und 1e4 gewählt. Wie bei Support Vector Machines spezifizieren kleinere Werte eine stärkere Regularisierung.
- l1_ratiosArray-ähnlich der Form (n_l1_ratios), Standard=None
Floats zwischen 0 und 1, die als Elastic-Net-Mischparameter (Skalierung zwischen L1- und L2-Strafen) übergeben werden. Für
l1_ratio = 0ist die Strafe eine L2-Strafe. Fürl1_ratio = 1ist es eine L1-Strafe. Für0 < l1_ratio < 1ist die Strafe eine Kombination aus L1 und L2. Alle Werte des gegebenen Array-ähnlichen Objekts werden per Kreuzvalidierung getestet und derjenige, der den besten Vorhersage-Score liefert, wird verwendet.Warnung
Bestimmte Werte von
l1_ratios, d. h. einige Strafen, funktionieren möglicherweise nicht mit einigen Lösern. Siehe den Parametersolverunten, um die Kompatibilität zwischen Strafe und Löser zu erfahren.Veraltet seit Version 1.8:
l1_ratios=Noneist in Version 1.8 veraltet und wird in Version 1.10 einen Fehler auslösen. Der Standardwert wird sich vonNonezu(0.0,)in Version 1.10 ändern.- fit_interceptbool, Standardwert=True
Gibt an, ob eine Konstante (auch Bias oder Achsenabschnitt genannt) zur Entscheidungsfunktion hinzugefügt werden soll.
- cvint oder Kreuzvalidierungsgenerator, Standard=None
Der standardmäßige Kreuzvalidierungsgenerator ist Stratified K-Folds. Wenn eine Ganzzahl angegeben wird, gibt sie die Anzahl der verwendeten Folds,
n_folds, an. Siehe das Modulsklearn.model_selectionfür die Liste der möglichen Kreuzvalidierungsobjekte.Geändert in Version 0.22: Der Standardwert von
cv, wenn None, hat sich von 3-Fold auf 5-Fold geändert.- dualbool, Standard=False
Duale (beschränkte) oder primäre (regulierte, siehe auch diese Gleichung) Formulierung. Die duale Formulierung ist nur für die l2-Strafe mit dem liblinear-Löser implementiert. Bevorzugen Sie dual=False, wenn n_samples > n_features.
- penalty{‘l1’, ‘l2’, ‘elasticnet’}, Standard=’l2’
Geben Sie die Norm der Strafe an
'l2': fügt einen L2-Strafenterm hinzu (wird standardmäßig verwendet);'l1': fügt einen L1-Strafenterm hinzu;'elasticnet': beide L1- und L2-Strafenterme werden hinzugefügt.
Warnung
Einige Strafen funktionieren möglicherweise nicht mit einigen Lösern. Siehe den Parameter
solverunten, um die Kompatibilität zwischen Strafe und Löser zu erfahren.Veraltet seit Version 1.8:
penaltywar in Version 1.8 veraltet und wird in Version 1.10 entfernt. Verwenden Sie stattdessenl1_ratio.l1_ratio=0fürpenalty='l2',l1_ratio=1fürpenalty='l1'undl1_ratioauf einen beliebigen Float-Wert zwischen 0 und 1 gesetzt für'penalty='elasticnet'.- scoringstr oder callable, Standardwert=None
Die verwendete Scoring-Methode für die Kreuzvalidierung. Optionen
str: siehe Zeichenkettennamen für Bewerter für Optionen.
callable: Ein Scorer-Callable-Objekt (z. B. Funktion) mit der Signatur
scorer(estimator, X, y). Siehe Callable Scorer für Details.None: Genauigkeit wird verwendet.
- solver{‘lbfgs’, ‘liblinear’, ‘newton-cg’, ‘newton-cholesky’, ‘sag’, ‘saga’}, Standard=’lbfgs’
Algorithmus, der im Optimierungsproblem verwendet werden soll. Standard ist ‘lbfgs’. Um einen Löser auszuwählen, sollten Sie die folgenden Aspekte berücksichtigen
‘lbfgs’ ist ein guter Standardlöser, da er für eine breite Klasse von Problemen einigermaßen gut funktioniert.
Für Multiklassenprobleme (
n_classes >= 3) minimieren alle Löser außer ‘liblinear’ die gesamte multinominale Verlustfunktion, ‘liblinear’ löst einen Fehler aus.‘newton-cholesky’ ist eine gute Wahl für
n_samples>>n_features * n_classes, insbesondere bei One-Hot-kodierten kategorialen Merkmalen mit seltenen Kategorien. Beachten Sie, dass der Speicherbedarf dieses Lösers quadratisch vonn_features * n_classesabhängt, da er explizit die vollständige Hesse-Matrix berechnet.Für kleine Datensätze ist ‘liblinear’ eine gute Wahl, während ‘sag’ und ‘saga’ für große schneller sind;
‘liblinear’ kann in
LogisticRegressionCVlangsamer sein, da er kein Warm-Starting unterstützt.‘liblinear’ kann standardmäßig nur binäre Klassifizierung behandeln. Um ein One-versus-Rest-Schema für das Multiklassenproblem anzuwenden, kann es mit
OneVsRestClassifiergekapselt werden.
Warnung
Die Wahl des Algorithmus hängt von der gewählten Strafe (
l1_ratio=0für L2-Strafe,l1_ratio=1für L1-Strafe und0 < l1_ratio < 1für Elastic-Net) und von der (multinomialen) Multiklassenunterstützung ab.solver
l1_ratio
multinomial multiclass
‘lbfgs’
l1_ratio=0
yes
‘liblinear’
l1_ratio=1 or l1_ratio=0
no
‘newton-cg’
l1_ratio=0
yes
‘newton-cholesky’
l1_ratio=0
yes
‘sag’
l1_ratio=0
yes
‘saga’
0<=l1_ratio<=1
yes
Hinweis
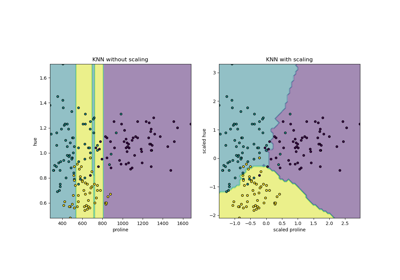
Die schnelle Konvergenz von ‘sag’ und ‘saga’ ist nur bei Merkmalen mit ungefähr gleicher Skala garantiert. Sie können die Daten mit einem Scaler aus
sklearn.preprocessingvorverarbeiten.Hinzugefügt in Version 0.17: Stochastischer Gradienten-Abstiegs-Löser (SAG). Multiklassenunterstützung in Version 0.18.
Hinzugefügt in Version 0.19: SAGA-Löser.
Hinzugefügt in Version 1.2: newton-cholesky-Löser. Multiklassenunterstützung in Version 1.6.
- tolfloat, Standard=1e-4
Toleranz für die Abbruchkriterien.
- max_iterint, default=100
Maximale Anzahl von Iterationen des Optimierungsalgorithmus.
- class_weightdict oder ‘balanced’, Standard=None
Gewichte, die den Klassen zugeordnet sind, in der Form
{Klassenbezeichnung: Gewicht}. Wenn nicht angegeben, wird angenommen, dass alle Klassen das Gewicht eins haben.Der Modus „balanced“ verwendet die Werte von y, um Gewichte automatisch invers proportional zur Klassenhäufigkeit in den Eingabedaten anzupassen, als
n_samples / (n_classes * np.bincount(y)).Beachten Sie, dass diese Gewichte mit sample_weight (das über die fit-Methode übergeben wird) multipliziert werden, wenn sample_weight angegeben ist.
Hinzugefügt in Version 0.17: class_weight == ‘balanced’
- n_jobsint, default=None
Anzahl der CPU-Kerne, die während der Kreuzvalidierungsschleife verwendet werden.
Nonebedeutet 1, es sei denn, Sie befinden sich in einemjoblib.parallel_backend-Kontext.-1bedeutet, alle Prozessoren zu verwenden. Siehe Glossar für weitere Details.- verboseint, default=0
Für die Löser ‘liblinear’, ‘sag’ und ‘lbfgs’ setzen Sie verbose auf eine beliebige positive Zahl für die Ausführlichkeit.
- refitbool, Standard=True
Wenn auf True gesetzt, werden die Scores über alle Folds gemittelt und die Koeffizienten und das C, die dem besten Score entsprechen, genommen und ein abschließendes Refitting mit diesen Parametern durchgeführt. Andernfalls werden die Koeffizienten, Achsenabschnitte und C, die den besten Scores über die Folds entsprechen, gemittelt.
- intercept_scalingfloat, Standard=1
Nur nützlich, wenn der Löser
liblinearverwendet wird undself.fit_interceptaufTruegesetzt ist. In diesem Fall wirdxzu[x, self.intercept_scaling], d. h. ein „synthetisches“ Merkmal mit einem konstanten Wert gleichintercept_scalingwird an den Instanzvektor angehängt. Der Achsenabschnitt wird zuintercept_scaling * synthetic_feature_weight.Hinweis
Das Gewicht des synthetischen Merkmals unterliegt wie alle anderen Merkmale L1- oder L2-Regularisierung. Um die Auswirkung der Regularisierung auf das Gewicht des synthetischen Merkmals (und damit auf den Achsenabschnitt) zu verringern, muss
intercept_scalingerhöht werden.- random_stateint, RandomState instance, default=None
Verwendet, wenn
solver='sag', ‘saga’ oder ‘liblinear’ verwendet wird, um die Daten zu mischen. Beachten Sie, dass dies nur für den Löser gilt und nicht für den Kreuzvalidierungsgenerator. Siehe Glossar für Details.- use_legacy_attributesbool, Standard=True
Wenn True, werden Legacy-Werte für Attribute verwendet
C_ist ein ndarray der Form (n_classes,) mit demselben wiederholten Wertl1_ratio_ist ein ndarray der Form (n_classes,) mit demselben wiederholten Wertcoefs_paths_ist ein dict mit Klassenbezeichnungen als Schlüssel und ndarrays als Wertescores_ist ein dict mit Klassenbezeichnungen als Schlüssel und ndarrays als Werten_iter_ist ein ndarray der Form (1, n_folds, n_cs) oder ähnlich
Wenn False, werden neue Werte für Attribute verwendet
C_ist ein floatl1_ratio_ist ein floatcoefs_paths_ist ein ndarray der Form (n_folds, n_l1_ratios, n_cs, n_classes, n_features). Für binäre Probleme (n_classes=2) ist die 2. letzte Dimension 1.scores_ist ein ndarray der Form (n_folds, n_l1_ratios, n_cs)n_iter_ist ein ndarray der Form (n_folds, n_l1_ratios, n_cs)
Geändert in Version 1.10: Der Standardwert wird sich von True auf False in Version 1.10 ändern.
Veraltet seit Version 1.10:
use_legacy_attributeswird in Version 1.10 veraltet sein und in 1.12 entfernt werden.
- Attribute:
- classes_ndarray der Form (n_classes,)
Eine Liste von Klassenbezeichnungen, die dem Klassifikator bekannt sind.
- coef_ndarray der Form (1, n_features) oder (n_classes, n_features)
Koeffizienten der Merkmale in der Entscheidungsfunktion.
coef_hat die Form (1, n_features), wenn das gegebene Problem binär ist.- intercept_ndarray der Form (1,) oder (n_classes,)
Achsenabschnitt (auch Bias genannt), der zur Entscheidungsfunktion hinzugefügt wird.
Wenn
fit_interceptauf False gesetzt ist, wird der Achsenabschnitt auf Null gesetzt.intercept_hat die Form (1,), wenn das Problem binär ist.- Cs_ndarray der Form (n_cs)
Array von C, d. h. Werte des inversen Regularisierungsparameters, die für die Kreuzvalidierung verwendet wurden.
- l1_ratios_ndarray der Form (n_l1_ratios)
Array von l1_ratios, die für die Kreuzvalidierung verwendet wurden. Wenn l1_ratios=None verwendet wird (d. h. penalty ist nicht ‘elasticnet’), wird dies auf
[None]gesetzt.- coefs_paths_dict von ndarray der Form (n_folds, n_cs, n_dof) oder (n_folds, n_cs, n_l1_ratios, n_dof)
Ein Dictionary mit Klassen als Schlüssel und dem Pfad der Koeffizienten, der während der Kreuzvalidierung über jeden Fold (
n_folds) und dann über jeden Cs (n_cs) erhalten wurde. Die Größe der Koeffizienten ist die Anzahl der Freiheitsgrade (n_dof), d. h. ohne Achsenabschnittn_dof=n_featuresund mit Achsenabschnittn_dof=n_features+1. Wennpenalty='elasticnet', gibt es eine zusätzliche Dimension für die Anzahl der l1_ratio-Werte (n_l1_ratios), was eine Form von(n_folds, n_cs, n_l1_ratios_, n_dof)ergibt. Siehe auch den Parameteruse_legacy_attributes.- scores_dict
Ein Dictionary mit Klassen als Schlüssel und den Werten als Gitter von Scores, die während der Kreuzvalidierung jedes Folds erhalten wurden. Derselbe Score wird über alle Klassen wiederholt. Jeder Dictionary-Wert hat die Form
(n_folds, n_cs)oder(n_folds, n_cs, n_l1_ratios), wennpenalty='elasticnet'. Siehe auch den Parameteruse_legacy_attributes.- C_ndarray der Form (n_classes,) oder (1,)
Der Wert von C, der dem besten Score zugeordnet ist, n_classes Mal wiederholt. Wenn refit auf False gesetzt ist, ist das beste C der Durchschnitt der C-Werte, die dem besten Score für jeden Fold entsprechen.
C_hat die Form (1,), wenn das Problem binär ist. Siehe auch den Parameteruse_legacy_attributes.- l1_ratio_ndarray der Form (n_classes,) oder (n_classes - 1,)
Der Wert von l1_ratio, der dem besten Score zugeordnet ist, n_classes Mal wiederholt. Wenn refit auf False gesetzt ist, ist das beste l1_ratio der Durchschnitt der l1_ratio-Werte, die dem besten Score für jeden Fold entsprechen.
l1_ratio_hat die Form (1,), wenn das Problem binär ist. Siehe auch den Parameteruse_legacy_attributes.- n_iter_ndarray der Form (1, n_folds, n_cs) oder (1, n_folds, n_cs, n_l1_ratios)
Tatsächliche Anzahl von Iterationen für alle Klassen, Folds und Cs. Wenn
penalty='elasticnet', hat die Form(1, n_folds, n_cs, n_l1_ratios). Siehe auch den Parameteruse_legacy_attributes.- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
Siehe auch
LogisticRegressionLogistische Regression ohne Abstimmung des Hyperparameters
C.
Beispiele
>>> from sklearn.datasets import load_iris >>> from sklearn.linear_model import LogisticRegressionCV >>> X, y = load_iris(return_X_y=True) >>> clf = LogisticRegressionCV( ... cv=5, random_state=0, use_legacy_attributes=False, l1_ratios=(0,) ... ).fit(X, y) >>> clf.predict(X[:2, :]) array([0, 0]) >>> clf.predict_proba(X[:2, :]).shape (2, 3) >>> clf.score(X, y) 0.98...
- decision_function(X)[source]#
Konfidenz-Scores für Stichproben vorhersagen.
Der Konfidenz-Score für eine Stichprobe ist proportional zum vorzeichenbehafteten Abstand dieser Stichprobe zur Hyperebene.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Datenmatrix, für die wir die Konfidenz-Scores erhalten möchten.
- Gibt zurück:
- scoresndarray der Form (n_samples,) oder (n_samples, n_classes)
Konfidenz-Scores pro
(n_samples, n_classes)-Kombination. Im binären Fall, Konfidenz-Score fürself.classes_[1], wobei >0 bedeutet, dass diese Klasse vorhergesagt würde.
- densify()[source]#
Konvertiert die Koeffizientenmatrix in ein dichtes Array-Format.
Konvertiert das Mitglied
coef_(zurück) in ein numpy.ndarray. Dies ist das Standardformat voncoef_und wird für das Training benötigt, daher muss diese Methode nur auf Modellen aufgerufen werden, die zuvor verknappt wurden; andernfalls ist sie eine No-Op.- Gibt zurück:
- self
Angepasster Schätzer.
- fit(X, y, sample_weight=None, **params)[source]#
Trainiert das Modell anhand der gegebenen Trainingsdaten.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Trainingsvektor, wobei
n_samplesdie Anzahl der Stichproben undn_featuresdie Anzahl der Merkmale ist.- yarray-like von Form (n_samples,)
Zielvektor relativ zu X.
- sample_weightArray-ähnlich der Form (n_samples,) Standard=None
Array von Gewichten, die einzelnen Stichproben zugeordnet sind. Wenn nicht bereitgestellt, erhält jede Stichprobe das Einheitsgewicht.
- **paramsdict
Parameter, die an den zugrunde liegenden Splitter und Scorer übergeben werden.
Hinzugefügt in Version 1.4.
- Gibt zurück:
- selfobject
Trainierter LogisticRegressionCV-Schätzer.
- get_metadata_routing()[source]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
Hinzugefügt in Version 1.4.
- Gibt zurück:
- routingMetadataRouter
Ein
MetadataRouter, der die Routing-Informationen kapselt.
- get_params(deep=True)[source]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X)[source]#
Vorhersagen von Klassenbezeichnungen für Stichproben in X.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Datenmatrix, für die wir die Vorhersagen erhalten möchten.
- Gibt zurück:
- y_predndarray von Form (n_samples,)
Vektor, der die Klassenbezeichnungen für jede Stichprobe enthält.
- predict_log_proba(X)[source]#
Vorhersage des Logarithmus von Wahrscheinlichkeitsschätzungen.
Die zurückgegebenen Schätzungen für alle Klassen sind nach der Bezeichnung der Klassen geordnet.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Vektor, der bewertet werden soll, wobei
n_samplesdie Anzahl der Stichproben undn_featuresdie Anzahl der Merkmale ist.
- Gibt zurück:
- TArray-ähnlich der Form (n_samples, n_classes)
Gibt die Log-Wahrscheinlichkeit der Stichprobe für jede Klasse im Modell zurück, wobei die Klassen in der Reihenfolge von
self.classes_geordnet sind.
- predict_proba(X)[source]#
Wahrscheinlichkeitsschätzungen.
Die zurückgegebenen Schätzungen für alle Klassen sind nach der Bezeichnung der Klassen geordnet.
Für ein Multiklassen- / Multinomialproblem wird die Softmax-Funktion verwendet, um die vorhergesagte Wahrscheinlichkeit jeder Klasse zu ermitteln.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Vektor, der bewertet werden soll, wobei
n_samplesdie Anzahl der Stichproben undn_featuresdie Anzahl der Merkmale ist.
- Gibt zurück:
- TArray-ähnlich der Form (n_samples, n_classes)
Gibt die Wahrscheinlichkeit der Stichprobe für jede Klasse im Modell zurück, wobei die Klassen in der Reihenfolge von
self.classes_geordnet sind.
- score(X, y, sample_weight=None, **score_params)[source]#
Bewertet mit der Option
scoringanhand der gegebenen Testdaten und Labels.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben.
- yarray-like von Form (n_samples,)
Wahre Labels für X.
- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- **score_paramsdict
Parameter, die an die
score-Methode des zugrunde liegenden Scorers übergeben werden.Hinzugefügt in Version 1.4.
- Gibt zurück:
- scorefloat
Score von self.predict(X) relativ zu y.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') LogisticRegressionCV[source]#
Konfiguriert, ob Metadaten für die
fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anfitübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anfit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinfit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_params(**params)[source]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') LogisticRegressionCV[source]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- sparsify()[source]#
Koeffizientenmatrix in Sparse-Format konvertieren.
Konvertiert das
coef_-Mitglied in eine scipy.sparse-Matrix, die für Modelle mit L1-Regularisierung speicher- und speichereffizienter sein kann als die übliche numpy.ndarray-Darstellung.Das
intercept_-Mitglied wird nicht konvertiert.- Gibt zurück:
- self
Angepasster Schätzer.
Anmerkungen
Für nicht-sparse Modelle, d.h. wenn nicht viele Nullen in
coef_vorhanden sind, kann dies tatsächlich den Speicherverbrauch *erhöhen*, also verwenden Sie diese Methode mit Vorsicht. Eine Faustregel besagt, dass die Anzahl der Nullelemente, die mit(coef_ == 0).sum()berechnet werden kann, mehr als 50 % betragen muss, damit dies signifikante Vorteile bringt.Nach dem Aufruf dieser Methode funktioniert die weitere Anpassung mit der Methode
partial_fit(falls vorhanden) nicht mehr, bis Siedensifyaufrufen.