minmax_scale#
- sklearn.preprocessing.minmax_scale(X, feature_range=(0, 1), *, axis=0, copy=True)[Quelle]#
Transformiert Merkmale durch Skalierung jedes Merkmals auf einen gegebenen Bereich.
Dieser Schätzer skaliert und verschiebt jedes Merkmal individuell so, dass es im angegebenen Bereich auf dem Trainingsdatensatz liegt, d. h. zwischen Null und Eins.
Die Transformation ist gegeben durch (wenn
axis=0)X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0)) X_scaled = X_std * (max - min) + min
wobei min, max = feature_range.
Die Transformation wird berechnet als (wenn
axis=0)X_scaled = scale * X + min - X.min(axis=0) * scale where scale = (max - min) / (X.max(axis=0) - X.min(axis=0))
Diese Transformation wird oft als Alternative zur Skalierung mit Mittelwert Null und Einheitsvarianz verwendet.
Lesen Sie mehr im Benutzerhandbuch.
Hinzugefügt in Version 0.17: minmax_scale Funktionsschnittstelle zu
MinMaxScaler.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Die Daten.
- feature_rangeTupel (min, max), Standardwert=(0, 1)
Gewünschter Bereich der transformierten Daten.
- axis{0, 1}, Standardwert=0
Achse, entlang derer skaliert werden soll. Wenn 0, werden die einzelnen Merkmale unabhängig skaliert, andernfalls (wenn 1) wird jede Stichprobe skaliert.
- copybool, Standard=True
Wenn False, versuchen Sie, eine Kopie zu vermeiden und die Skalierung direkt vorzunehmen. Dies ist nicht garantiert immer direkt möglich; z. B. wenn die Daten ein NumPy-Array mit einem Integer-Datentyp sind, wird auch bei copy=False eine Kopie zurückgegeben.
- Gibt zurück:
- X_trndarray der Form (n_samples, n_features)
Die transformierten Daten.
Warnung
Risiko von Datenlecks Verwenden Sie
minmax_scalenicht, es sei denn, Sie wissen, was Sie tun. Ein häufiger Fehler ist, es auf die gesamten Daten anzuwenden, *bevor* diese in Trainings- und Testdatensätze aufgeteilt werden. Dies führt zu einer verzerrten Modellauswertung, da Informationen vom Testdatensatz in den Trainingsdatensatz übergegangen wären. Im Allgemeinen empfehlen wir die Verwendung vonMinMaxScalerinnerhalb einer Pipeline, um die meisten Risiken von Datenlecks zu verhindern:pipe = make_pipeline(MinMaxScaler(), LogisticRegression()).
Siehe auch
MinMaxScalerFührt die Skalierung auf einen gegebenen Bereich mithilfe der Transformer-API durch (z. B. als Teil einer Vorverarbeitungs-
Pipeline).
Anmerkungen
Für einen Vergleich der verschiedenen Skalierer, Transformer und Normalisierer siehe: Vergleichen Sie die Auswirkung verschiedener Skalierer auf Daten mit Ausreißern.
Beispiele
>>> from sklearn.preprocessing import minmax_scale >>> X = [[-2, 1, 2], [-1, 0, 1]] >>> minmax_scale(X, axis=0) # scale each column independently array([[0., 1., 1.], [1., 0., 0.]]) >>> minmax_scale(X, axis=1) # scale each row independently array([[0. , 0.75, 1. ], [0. , 0.5 , 1. ]])
Galeriebeispiele#

Restricted Boltzmann Machine Merkmale für Ziffernklassifikation
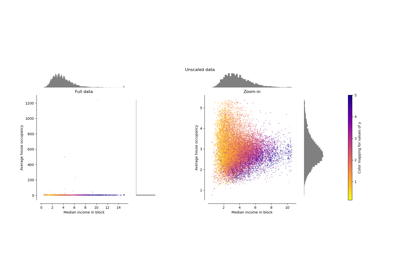
Vergleich der Auswirkungen verschiedener Skalierer auf Daten mit Ausreißern