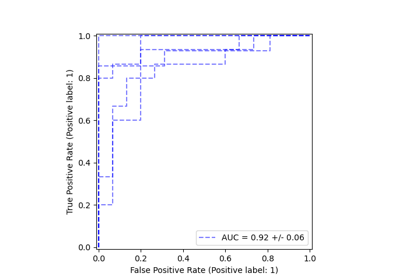
HistGradientBoostingClassifier#
- class sklearn.ensemble.HistGradientBoostingClassifier(loss='log_loss', *, learning_rate=0.1, max_iter=100, max_leaf_nodes=31, max_depth=None, min_samples_leaf=20, l2_regularization=0.0, max_features=1.0, max_bins=255, categorical_features='from_dtype', monotonic_cst=None, interaction_cst=None, warm_start=False, early_stopping='auto', scoring='loss', validation_fraction=0.1, n_iter_no_change=10, tol=1e-07, verbose=0, random_state=None, class_weight=None)[Quelle]#
Histogramm-basierter Gradient Boosting Klassifikationsbaum.
Dieser Estimator ist für große Datensätze (n_samples >= 10.000) deutlich schneller als
GradientBoostingClassifier.Dieser Estimator unterstützt nativ fehlende Werte (NaNs). Während des Trainings lernt der Baumgenerator an jedem Splitpunkt, ob Samples mit fehlenden Werten basierend auf dem potenziellen Gewinn zum linken oder rechten Kind gehen sollen. Bei der Vorhersage werden Samples mit fehlenden Werten folgerichtig dem linken oder rechten Kind zugeordnet. Wenn während des Trainings keine fehlenden Werte für ein bestimmtes Merkmal angetroffen wurden, werden Samples mit fehlenden Werten dem Kind mit den meisten Samples zugeordnet.
Diese Implementierung ist inspiriert von LightGBM.
Lesen Sie mehr im Benutzerhandbuch.
Hinzugefügt in Version 0.21.
- Parameter:
- loss{‘log_loss’}, Standard=‘log_loss’
Die zu verwendende Verlustfunktion im Boosting-Prozess.
Für binäre Klassifikationsprobleme ist ‘log_loss’ auch bekannt als logistischer Verlust, binomiale Abweichung oder binäre Kreuzentropie. Intern passt das Modell einen Baum pro Boosting-Iteration an und verwendet die logistische Sigmoidfunktion (expit) als inverse Linkfunktion, um die vorhergesagte Wahrscheinlichkeit der positiven Klasse zu berechnen.
Für Multiklassen-Klassifikationsprobleme ist ‘log_loss’ auch bekannt als multinomiale Abweichung oder kategorische Kreuzentropie. Intern passt das Modell einen Baum pro Boosting-Iteration und pro Klasse an und verwendet die Softmaxfunktion als inverse Linkfunktion, um die vorhergesagten Wahrscheinlichkeiten der Klassen zu berechnen.
- learning_ratefloat, Standard=0.1
Die Lernrate, auch bekannt als Shrinkage. Dies wird als Multiplikator für die Werte der Blätter verwendet. Verwenden Sie
1für kein Shrinkage.- max_iterint, default=100
Die maximale Anzahl von Iterationen des Boosting-Prozesses, d.h. die maximale Anzahl von Bäumen für die binäre Klassifikation. Für die Multiklassen-Klassifikation werden pro Iteration
n_classesBäume aufgebaut.- max_leaf_nodesint oder None, Standard=31
Die maximale Anzahl von Blättern pro Baum. Muss größer als 1 sein. Wenn None, gibt es keine maximale Begrenzung.
- max_depthint oder None, Standard=None
Die maximale Tiefe jedes Baumes. Die Tiefe eines Baumes ist die Anzahl der Kanten vom Wurzelknoten zum tiefsten Blatt. Die Tiefe ist standardmäßig nicht begrenzt.
- min_samples_leafint, Standard=20
Die minimale Anzahl von Samples pro Blatt. Für kleine Datensätze mit weniger als einigen hundert Samples wird empfohlen, diesen Wert zu senken, da nur sehr flache Bäume erstellt würden.
- l2_regularizationfloat, Standard=0
Der L2-Regularisierungsparameter, der Blätter mit kleinen Hessians bestraft. Verwenden Sie
0für keine Regularisierung (Standard).- max_featuresfloat, Standard=1.0
Anteil zufällig ausgewählter Merkmale bei jeder und jeder Knotenaufteilung. Dies ist eine Form der Regularisierung, kleinere Werte machen die Bäume zu schwächeren Lernenden und können Überanpassung verhindern. Wenn Interaktionsbeschränkungen aus
interaction_cstvorhanden sind, werden nur zulässige Merkmale für die Teilstichprobenziehung berücksichtigt.Hinzugefügt in Version 1.4.
- max_binsint, Standard=255
Die maximale Anzahl von Bins für nicht fehlende Werte. Vor dem Training wird jedes Merkmal des Eingabearrays
Xin ganzzahlige Bins eingeteilt, was eine deutlich schnellere Trainingsphase ermöglicht. Merkmale mit einer kleinen Anzahl eindeutiger Werte verwenden möglicherweise weniger alsmax_binsBins. Zusätzlich zu denmax_binsBins wird immer ein weiterer Bin für fehlende Werte reserviert. Darf nicht größer als 255 sein.- categorical_featuresarray-like von {bool, int, str} der Form (n_features) oder (n_categorical_features,), Standard=‘from_dtype’
Zeigt die kategorialen Merkmale an.
None : kein Merkmal wird als kategorial betrachtet.
boolesches Array-ähnliches Objekt : boolesche Maske, die kategoriale Merkmale angibt.
Integer-Array-ähnliches Objekt : Integer-Indizes, die kategoriale Merkmale angeben.
str Array-ähnliches Objekt: Namen von kategorialen Merkmalen (vorausgesetzt, die Trainingsdaten haben Merkmalsnamen).
"from_dtype": DataFrame-Spalten mit dtype „category“ werden als kategoriale Merkmale betrachtet. Die Eingabe muss ein Objekt sein, das eine__dataframe__Methode exponiert, wie z. B. Pandas- oder Polars-DataFrames, um diese Funktion zu nutzen.
Für jedes kategoriale Merkmal darf es höchstens
max_binseindeutige Kategorien geben. Negative Werte für kategoriale Merkmale, die als numerische dtypes kodiert sind, werden als fehlende Werte behandelt. Alle kategorialen Werte werden in Gleitkommazahlen konvertiert. Das bedeutet, dass kategoriale Werte von 1.0 und 1 als dieselbe Kategorie behandelt werden.Lesen Sie mehr im Benutzerhandbuch.
Hinzugefügt in Version 0.24.
Geändert in Version 1.2: Unterstützung für Merkmalsnamen hinzugefügt.
Geändert in Version 1.4: Option
"from_dtype"hinzugefügt.Geändert in Version 1.6: Der Standardwert änderte sich von
Nonezu"from_dtype".- monotonic_cstarray-like von int der Form (n_features) oder dict, Standard=None
Monotonie-Beschränkungen für jedes Merkmal werden mit den folgenden Integer-Werten angegeben
1: monoton steigend
0: keine Beschränkung
-1: monoton fallend
Wenn ein Dict mit str-Schlüsseln, werden Merkmale nach Namen auf Monotonie-Beschränkungen abgebildet. Wenn ein Array, werden die Merkmale positionsweise auf Beschränkungen abgebildet. Ein Anwendungsbeispiel finden Sie unter Verwendung von Merkmalnamen zur Angabe von Monotonie-Beschränkungen.
Die Beschränkungen sind nur für binäre Klassifikationen gültig und gelten für die Wahrscheinlichkeit der positiven Klasse. Lesen Sie mehr im Benutzerhandbuch.
Hinzugefügt in Version 0.23.
Geändert in Version 1.2: Akzeptiert Dict von Beschränkungen mit Merkmalnamen als Schlüssel.
- interaction_cst{“pairwise”, “no_interactions”} oder Sequenz von Listen/Tupeln/Sets von int, Standard=None
Gibt Interaktionsbeschränkungen an, d. h. die Mengen von Merkmalen, die in Kindknoten-Splits miteinander interagieren dürfen.
Jedes Element gibt die Menge der Merkmalsindizes an, die miteinander interagieren dürfen. Wenn mehr Merkmale vorhanden sind als in diesen Beschränkungen angegeben, werden sie so behandelt, als wären sie als zusätzliche Menge angegeben worden.
Die Zeichenfolgen „pairwise“ und „no_interactions“ sind Abkürzungen für die Zulassung von nur paarweisen oder gar keinen Interaktionen.
Zum Beispiel ist bei insgesamt 5 Merkmalen
interaction_cst=[{0, 1}]äquivalent zuinteraction_cst=[{0, 1}, {2, 3, 4}]und gibt an, dass jeder Zweig eines Baumes entweder nur auf den Merkmalen 0 und 1 oder nur auf den Merkmalen 2, 3 und 4 aufteilt.Sehen Sie sich dieses Beispiel an, wie
interaction_cstverwendet wird.Hinzugefügt in Version 1.2.
- warm_startbool, Standard=False
Wenn auf
Truegesetzt, wird die Lösung des vorherigen Aufrufs von fit wiederverwendet und weitere Estimators zum Ensemble hinzugefügt. Für gültige Ergebnisse sollte der Estimator nur auf denselben Daten neu trainiert werden. Siehe Glossar.- early_stopping‘auto’ oder bool, Standard=‘auto’
Wenn ‚auto‘, wird Early Stopping aktiviert, wenn die Stichprobengröße größer als 10000 ist oder wenn
X_valundy_valanfitübergeben werden. Wenn True, wird Early Stopping aktiviert, andernfalls ist Early Stopping deaktiviert.Hinzugefügt in Version 0.23.
- scoringstr oder callable oder None, Standard=‘loss’
Scoring-Methode für Early Stopping. Nur verwendet, wenn
early_stoppingaktiviert ist. Optionenstr: siehe Zeichenkettennamen für Bewerter für Optionen.
callable: Ein Scorer-Callable-Objekt (z. B. Funktion) mit der Signatur
scorer(estimator, X, y). Siehe Callable Scorer für Details.None: Genauigkeit wird verwendet.„loss“: Early Stopping wird im Hinblick auf den Verlustwert geprüft.
- validation_fractionint oder float oder None, Standard=0.1
Anteil (oder absolute Größe) der Trainingsdaten, die für Early Stopping als Validierungsdaten zurückgestellt werden. Wenn None, erfolgt Early Stopping auf den Trainingsdaten. Der Wert wird ignoriert, wenn entweder kein Early Stopping durchgeführt wird (z. B.
early_stopping=False) oder wennX_valundy_valan fit übergeben werden.- n_iter_no_changeint, Standard=10
Wird verwendet, um zu bestimmen, wann „early stop“ erreicht ist. Der Fitting-Prozess wird gestoppt, wenn keiner der letzten
n_iter_no_changeScores besser ist als dern_iter_no_change - 1-te-letzte Score, bis zu einer gewissen Toleranz. Nur verwendet, wenn Early Stopping durchgeführt wird.- tolfloat, Standard=1e-7
Die absolute Toleranz, die beim Vergleich von Scores verwendet wird. Je höher die Toleranz, desto wahrscheinlicher ist es, dass frühzeitig gestoppt wird: Eine höhere Toleranz bedeutet, dass es für nachfolgende Iterationen schwieriger ist, als Verbesserung gegenüber dem Referenzwert betrachtet zu werden.
- verboseint, default=0
Die Ausführlichkeitsebene. Wenn nicht null, werden einige Informationen über den Fitting-Prozess ausgegeben.
1gibt nur Zusammenfassungsinformationen aus,2gibt Informationen pro Iteration aus.- random_stateint, RandomState-Instanz oder None, default=None
Pseudozufallszahlengenerator zur Steuerung der Teilstichprobenziehung im Binning-Prozess und der Aufteilung von Trainings-/Validierungsdaten, wenn Early Stopping aktiviert ist. Übergeben Sie eine Ganzzahl für reproduzierbare Ausgaben über mehrere Funktionsaufrufe hinweg. Siehe Glossar.
- class_weightdict oder ‘balanced’, Standard=None
Gewichte, die Klassen zugeordnet sind, in der Form
{class_label: weight}. Wenn nicht gegeben, werden alle Klassen als Gewicht eins angenommen. Der Modus „balanced“ verwendet die Werte von y, um die Gewichte automatisch invers proportional zu den Klassenfrequenzen in den Eingabedaten einzustellen, alsn_samples / (n_classes * np.bincount(y)). Beachten Sie, dass diese Gewichte mit sample_weight (über die fit-Methode übergeben) multipliziert werden, wennsample_weightangegeben ist.Hinzugefügt in Version 1.2.
- Attribute:
- classes_array, Form = (n_classes,)
Klassenbezeichnungen.
- do_early_stopping_bool
Gibt an, ob während des Trainings Early Stopping verwendet wird.
n_iter_intAnzahl der Iterationen des Boosting-Prozesses.
- n_trees_per_iteration_int
Die Anzahl der Bäume, die in jeder Iteration aufgebaut werden. Dies ist 1 für binäre Klassifikation und
n_classesfür Multiklassen-Klassifikation.- train_score_ndarray, Form = (n_iter_+1,)
Die Scores in jeder Iteration auf den Trainingsdaten. Der erste Eintrag ist der Score des Ensembles vor der ersten Iteration. Scores werden gemäß dem Parameter
scoringberechnet. Wennscoringnicht „loss“ ist, werden Scores auf einer Stichprobe von höchstens 10.000 Samples berechnet. Leer, wenn kein Early Stopping stattfindet.- validation_score_ndarray, Form = (n_iter_+1,)
Die Scores in jeder Iteration auf den zurückgestellten Validierungsdaten. Der erste Eintrag ist der Score des Ensembles vor der ersten Iteration. Scores werden gemäß dem Parameter
scoringberechnet. Leer, wenn kein Early Stopping stattfindet oder wennvalidation_fractionNone ist.- is_categorical_ndarray, Form = (n_features,) oder None
Boolesche Maske für die kategorialen Merkmale.
None, wenn keine kategorialen Merkmale vorhanden sind.- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
Siehe auch
GradientBoostingClassifierExakte Gradienten-Boosting-Methode, die bei Datensätzen mit vielen Samples nicht so gut skaliert.
sklearn.tree.DecisionTreeClassifierEin Entscheidungsbaum-Klassifikator.
RandomForestClassifierEin Meta-Estimator, der eine Anzahl von Entscheidungsbaum-Klassifikatoren auf verschiedenen Teilstichproben des Datensatzes anpasst und durch Mittelung die Vorhersagegenauigkeit verbessert und Überanpassung kontrolliert.
AdaBoostClassifierEin Meta-Estimator, der damit beginnt, einen Klassifikator auf dem ursprünglichen Datensatz anzupassen, und dann zusätzliche Kopien des Klassifikators auf demselben Datensatz anpasst, bei denen die Gewichte falsch klassifizierter Instanzen so angepasst werden, dass sich nachfolgende Klassifikatoren stärker auf schwierige Fälle konzentrieren.
Beispiele
>>> from sklearn.ensemble import HistGradientBoostingClassifier >>> from sklearn.datasets import load_iris >>> X, y = load_iris(return_X_y=True) >>> clf = HistGradientBoostingClassifier().fit(X, y) >>> clf.score(X, y) 1.0
- decision_function(X)[Quelle]#
Berechnet die Entscheidungsfunktion von
X.- Parameter:
- Xarray-ähnlich, Form (n_samples, n_features)
Die Eingabestichproben.
- Gibt zurück:
- decisionndarray, Form = (n_samples,) oder (n_samples, n_trees_per_iteration)
Die rohen vorhergesagten Werte (d. h. die Summe der Blattwerte der Bäume) für jeden Sample. n_trees_per_iteration ist gleich der Anzahl der Klassen bei der Multiklassen-Klassifikation.
- fit(X, y, sample_weight=None, *, X_val=None, y_val=None, sample_weight_val=None)[Quelle]#
Anpassen des Gradient Boosting-Modells.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Die Eingabestichproben.
- yarray-like von Form (n_samples,)
Zielwerte.
- sample_weightArray-ähnlich der Form (n_samples,) Standard=None
Gewichte der Trainingsdaten.
Hinzugefügt in Version 0.23.
- X_valarray-like der Form (n_val, n_features)
Zusätzliche Stichprobe von Merkmalen zur Validierung, die für Early Stopping verwendet wird. In einer
PipelinekannX_valauf dieselbe Weise wieXmitPipeline(..., transform_input=["X_val"])transformiert werden.Hinzugefügt in Version 1.7.
- y_valarray-like der Form (n_samples,)
Zusätzliche Stichprobe von Zielwerten zur Validierung, die für Early Stopping verwendet wird.
Hinzugefügt in Version 1.7.
- sample_weight_valarray-like der Form (n_samples,) Standard=None
Zusätzliche Gewichte für die Validierung, die für Early Stopping verwendet werden.
Hinzugefügt in Version 1.7.
- Gibt zurück:
- selfobject
Angepasster Schätzer.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X)[Quelle]#
Vorhersage von Klassen für X.
- Parameter:
- Xarray-ähnlich, Form (n_samples, n_features)
Die Eingabestichproben.
- Gibt zurück:
- yndarray, Form = (n_samples,)
Die vorhergesagten Klassen.
- predict_proba(X)[Quelle]#
Sagt die Klassenwahrscheinlichkeiten für X voraus.
- Parameter:
- Xarray-ähnlich, Form (n_samples, n_features)
Die Eingabestichproben.
- Gibt zurück:
- pndarray, Form = (n_samples, n_classes)
Die Klassenwahrscheinlichkeiten der Eingabemuster.
- score(X, y, sample_weight=None)[Quelle]#
Gibt die Genauigkeit für die bereitgestellten Daten und Bezeichnungen zurück.
Bei der Multi-Label-Klassifizierung ist dies die Subset-Genauigkeit, eine strenge Metrik, da für jede Stichprobe verlangt wird, dass jede Label-Menge korrekt vorhergesagt wird.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben.
- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Bezeichnungen für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
Mittlere Genauigkeit von
self.predict(X)in Bezug aufy.
- set_fit_request(*, X_val: bool | None | str = '$UNCHANGED$', sample_weight: bool | None | str = '$UNCHANGED$', sample_weight_val: bool | None | str = '$UNCHANGED$', y_val: bool | None | str = '$UNCHANGED$') HistGradientBoostingClassifier[Quelle]#
Konfiguriert, ob Metadaten für die
fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anfitübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anfit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- X_valstr, True, False, oder None, Standard=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
X_valinfit.- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinfit.- sample_weight_valstr, True, False, oder None, Standard=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weight_valinfit.- y_valstr, True, False, oder None, Standard=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
y_valinfit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') HistGradientBoostingClassifier[Quelle]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- staged_decision_function(X)[Quelle]#
Berechnet die Entscheidungsfunktion von
Xfür jede Iteration.Diese Methode ermöglicht die Überwachung (d.h. Bestimmung von Fehlern auf dem Testdatensatz) nach jeder Stufe.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Die Eingabestichproben.
- Gibt:
- decisionGenerator von ndarray der Form (n_samples,) oder (n_samples, n_trees_per_iteration)
Die Entscheidungsfunktion der Eingabemuster, die den rohen Werten entspricht, die von den Bäumen des Ensembles vorhergesagt werden. Die Klassen entsprechen denen im Attribut classes_.
- staged_predict(X)[Quelle]#
Vorhersage der Klassen in jeder Iteration.
Diese Methode ermöglicht die Überwachung (d.h. Bestimmung von Fehlern auf dem Testdatensatz) nach jeder Stufe.
Hinzugefügt in Version 0.24.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Die Eingabestichproben.
- Gibt:
- yGenerator von ndarray der Form (n_samples,)
Die vorhergesagten Klassen der Eingabemuster für jede Iteration.
- staged_predict_proba(X)[Quelle]#
Klassenzugehörigkeitswahrscheinlichkeiten bei jeder Iteration vorhersagen.
Diese Methode ermöglicht die Überwachung (d.h. Bestimmung von Fehlern auf dem Testdatensatz) nach jeder Stufe.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Die Eingabestichproben.
- Gibt:
- yGenerator von ndarray der Form (n_samples,)
Die vorhergesagten Klassenzugehörigkeitswahrscheinlichkeiten der Eingabestichproben für jede Iteration.
Galeriebeispiele#

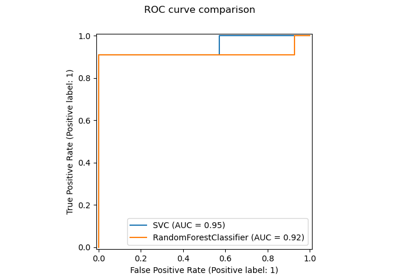
Vergleich von Random Forests und Histogram Gradient Boosting Modellen

Post-Hoc-Anpassung des Entscheidungsschwellenwerts für kostenempfindliches Lernen