OneVsRestClassifier#
- class sklearn.multiclass.OneVsRestClassifier(estimator, *, n_jobs=None, verbose=0)[Quelle]#
One-vs-the-rest (OvR) Multiklassenstrategie.
Auch als One-vs-All bekannt, besteht diese Strategie darin, einen Klassifikator pro Klasse anzupassen. Für jeden Klassifikator wird die Klasse gegen alle anderen Klassen angepasst. Neben seiner rechnerischen Effizienz (nur
n_classesKlassifikatoren werden benötigt) ist ein Vorteil dieses Ansatzes seine Interpretierbarkeit. Da jede Klasse nur durch einen Klassifikator repräsentiert wird, ist es möglich, Kenntnisse über die Klasse zu gewinnen, indem ihr entsprechender Klassifikator untersucht wird. Dies ist die am häufigsten verwendete Strategie für die Mehrklassenklassifizierung und eine faire Standardwahl.OneVsRestClassifier kann auch für die Mehrfachlabel-Klassifizierung verwendet werden. Um diese Funktion zu nutzen, stellen Sie bei der Übergabe von
.fiteine Indikatormatrix für das Zielybereit. Mit anderen Worten, die Ziel-Labels sollten als binäre (0/1) Matrix im 2D-Format vorliegen, wobei [i, j] == 1 die Anwesenheit von Label j in Stichprobe i anzeigt. Dieser Estimator verwendet die binäre Relevanzmethode zur Durchführung der Mehrfachlabel-Klassifizierung, was das unabhängige Training eines binären Klassifikators für jedes Label beinhaltet.Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- estimatorEstimator-Objekt
Ein Regressor oder ein Klassifikator, der fit implementiert. Wenn ein Klassifikator übergeben wird, wird decision_function bevorzugt verwendet und auf predict_proba zurückgefallen, falls es nicht verfügbar ist. Wenn ein Regressor übergeben wird, wird predict verwendet.
- n_jobsint, default=None
Die Anzahl der Jobs, die für die Berechnung verwendet werden: die
n_classesOne-vs-rest-Probleme werden parallel berechnet.Nonebedeutet 1, außer in einemjoblib.parallel_backendKontext.-1bedeutet die Verwendung aller Prozessoren. Siehe Glossar für weitere Details.Geändert in Version 0.20:
n_jobsStandard von 1 auf None geändert- verboseint, default=0
Die Ausführlichkeitsstufe. Wenn sie ungleich Null ist, werden Fortschrittsnachrichten ausgegeben. Unter 50 werden die Ausgaben an stderr gesendet. Andernfalls werden die Ausgaben an stdout gesendet. Die Häufigkeit der Meldungen steigt mit der Ausführlichkeitsstufe, wobei bei 10 alle Iterationen gemeldet werden. Weitere Details finden Sie unter
joblib.Parallel.Hinzugefügt in Version 1.1.
- Attribute:
- estimators_Liste von
n_classesEstimators Estimators, die für Vorhersagen verwendet werden.
- classes_Array, Form = [
n_classes] Klassenbezeichnungen.
n_classes_intAnzahl der Klassen.
- label_binarizer_LabelBinarizer-Objekt
Objekt, das verwendet wird, um Mehrklassen-Labels in binäre Labels und umgekehrt zu transformieren.
multilabel_booleanOb dies ein Mehrfachlabel-Klassifikator ist.
- n_features_in_int
Anzahl der während fit gesehenen Merkmale. Nur definiert, wenn der zugrunde liegende Schätzer ein solches Attribut nach dem Training bereitstellt.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen von Features, die während fit gesehen wurden. Nur definiert, wenn der zugrunde liegende Estimator ein solches Attribut nach dem Anpassen exponiert.
Hinzugefügt in Version 1.0.
- estimators_Liste von
Siehe auch
OneVsOneClassifierOne-vs-one Multiklassenstrategie.
OutputCodeClassifier(Fehlerkorrigierende) Output-Code-Multiklassenstrategie.
sklearn.multioutput.MultiOutputClassifierAlternative Möglichkeit, einen Estimator für die Mehrfachlabel-Klassifizierung zu erweitern.
sklearn.preprocessing.MultiLabelBinarizerIterierbare von Iterierbaren in eine binäre Indikatormatrix transformieren.
Beispiele
>>> import numpy as np >>> from sklearn.multiclass import OneVsRestClassifier >>> from sklearn.svm import SVC >>> X = np.array([ ... [10, 10], ... [8, 10], ... [-5, 5.5], ... [-5.4, 5.5], ... [-20, -20], ... [-15, -20] ... ]) >>> y = np.array([0, 0, 1, 1, 2, 2]) >>> clf = OneVsRestClassifier(SVC()).fit(X, y) >>> clf.predict([[-19, -20], [9, 9], [-5, 5]]) array([2, 0, 1])
- decision_function(X)[Quelle]#
Entscheidungsfunktion für den OneVsRestClassifier.
Gibt den Abstand jeder Stichprobe vom Entscheidungsgrenzwert für jede Klasse zurück. Dies kann nur mit Estimators verwendet werden, die die Methode
decision_functionimplementieren.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Eingabedaten.
- Gibt zurück:
- Tarray-ähnlich der Form (n_samples, n_classes) oder (n_samples,) für binäre Klassifizierung.
Ergebnis des Aufrufs von
decision_functionauf dem abschließenden Estimator.Geändert in Version 0.19: Form der Ausgabe geändert auf
(n_samples,), um den Konventionen von scikit-learn für die binäre Klassifizierung zu entsprechen.
- fit(X, y, **fit_params)[Quelle]#
Passen Sie zugrunde liegende Estimators an.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Daten.
- y{array-ähnlich, sparse matrix} der Form (n_samples,) oder (n_samples, n_classes)
Mehrklassen-Ziele. Eine Indikatormatrix aktiviert die Mehrfachlabel-Klassifizierung.
- **fit_paramsdict
Parameter, die an die
estimator.fitMethode jedes Unter-Estimators übergeben werden.Hinzugefügt in Version 1.4: Nur verfügbar, wenn
enable_metadata_routing=True. Siehe Benutzerhandbuch zur Metadaten-Weiterleitung für weitere Details.
- Gibt zurück:
- selfobject
Instanz des angepassten Estimators.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
Hinzugefügt in Version 1.4.
- Gibt zurück:
- routingMetadataRouter
Ein
MetadataRouter, der die Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- partial_fit(X, y, classes=None, **partial_fit_params)[Quelle]#
Teilweises Anpassen der zugrundeliegenden Estimators.
Sollte verwendet werden, wenn der Speicher für das Training aller Daten nicht ausreicht. Daten können in mehreren Iterationen in Blöcken übergeben werden.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Daten.
- y{array-ähnlich, sparse matrix} der Form (n_samples,) oder (n_samples, n_classes)
Mehrklassen-Ziele. Eine Indikatormatrix aktiviert die Mehrfachlabel-Klassifizierung.
- classesArray, Form (n_classes, )
Klassen über alle Aufrufe von partial_fit. Kann über
np.unique(y_all)erhalten werden, wobei y_all der Zielvektor des gesamten Datensatzes ist. Dieses Argument ist nur beim ersten Aufruf von partial_fit erforderlich und kann bei nachfolgenden Aufrufen weggelassen werden.- **partial_fit_paramsdict
An die Methode
estimator.partial_fitjedes Unterestimators übergebene Parameter.Hinzugefügt in Version 1.4: Nur verfügbar, wenn
enable_metadata_routing=True. Siehe Benutzerhandbuch zur Metadaten-Weiterleitung für weitere Details.
- Gibt zurück:
- selfobject
Instanz eines teilweise angepassten Estimators.
- predict(X)[Quelle]#
Vorhersage von Mehrklassen-Zielen mit zugrundeliegenden Estimators.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Daten.
- Gibt zurück:
- y{array-ähnlich, sparse matrix} der Form (n_samples,) oder (n_samples, n_classes)
Vorhergesagte Multi-Klassen-Zielwerte.
- predict_proba(X)[Quelle]#
Wahrscheinlichkeitsschätzungen.
Die zurückgegebenen Schätzungen für alle Klassen sind nach dem Label der Klassen geordnet.
Beachten Sie, dass im Mehrfachlabel-Fall jede Stichprobe eine beliebige Anzahl von Labels haben kann. Dies gibt die marginale Wahrscheinlichkeit zurück, dass die gegebene Stichprobe das betreffende Label hat. Es ist beispielsweise völlig konsistent, dass zwei Labels beide eine Wahrscheinlichkeit von 90 % haben, auf eine gegebene Stichprobe zuzutreffen.
Im Fall der Einzel-Label-Mehrklassenklassifizierung summieren sich die Zeilen der zurückgegebenen Matrix zu 1.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Eingabedaten.
- Gibt zurück:
- TArray-ähnlich der Form (n_samples, n_classes)
Gibt die Wahrscheinlichkeit der Stichprobe für jede Klasse im Modell zurück, wobei die Klassen in der Reihenfolge von
self.classes_geordnet sind.
- score(X, y, sample_weight=None)[Quelle]#
Gibt die Genauigkeit für die bereitgestellten Daten und Bezeichnungen zurück.
Bei der Multi-Label-Klassifizierung ist dies die Subset-Genauigkeit, eine strenge Metrik, da für jede Stichprobe verlangt wird, dass jede Label-Menge korrekt vorhergesagt wird.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben.
- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Bezeichnungen für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
Mittlere Genauigkeit von
self.predict(X)in Bezug aufy.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_partial_fit_request(*, classes: bool | None | str = '$UNCHANGED$') OneVsRestClassifier[Quelle]#
Konfiguriert, ob Metadaten für die
partial_fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und anpartial_fitübergeben, wenn sie bereitgestellt werden. Die Anforderung wird ignoriert, wenn keine Metadaten bereitgestellt werden.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anpartial_fit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- klassenstr, True, False, oder None, Standard=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
klasseninpartial_fit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') OneVsRestClassifier[Quelle]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
Galeriebeispiele#

Entscheidungsgrenzen von multinomialer und One-vs-Rest Logistischer Regression
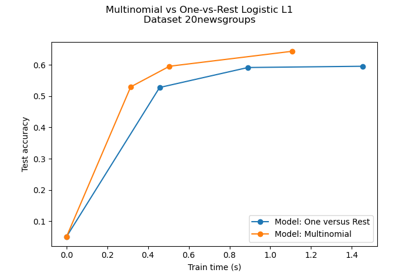
Multiklassen-Sparse-Logistische-Regression auf 20newgroups

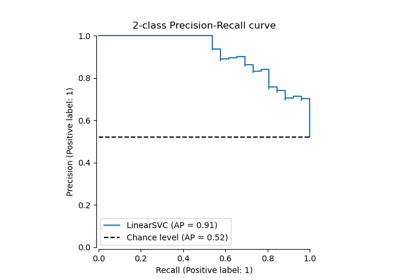

Multiklassen-Receiver Operating Characteristic (ROC)

Übersicht über Multiklassen-Training Meta-Estimator
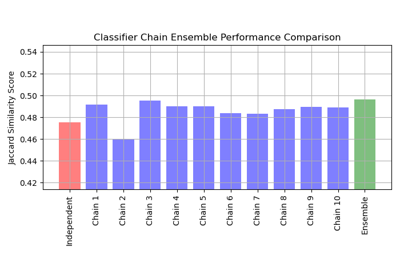
Multilabel-Klassifikation mit einem Klassifikator-Ketten