make_pipeline#
- sklearn.pipeline.make_pipeline(*steps, memory=None, transform_input=None, verbose=False)[Quelle]#
Konstruiert eine
Pipelineaus den gegebenen Schätzern.Dies ist eine Kurzschreibweise für den
Pipeline-Konstruktor; sie erfordert und erlaubt nicht die Benennung der Schätzer. Stattdessen werden ihre Namen automatisch in die Kleinschreibung ihrer Typen umgewandelt.- Parameter:
- *stepsListe von Estimator-Objekten
Liste der scikit-learn-Schätzer, die miteinander verkettet sind.
- memoryString oder Objekt mit dem joblib.Memory-Interface, Standard=None
Wird zum Caching der angepassten Transformer der Pipeline verwendet. Der letzte Schritt wird niemals gecacht, auch wenn es sich um einen Transformer handelt. Standardmäßig erfolgt kein Caching. Wenn eine Zeichenkette angegeben wird, ist dies der Pfad zum Caching-Verzeichnis. Das Aktivieren des Cachings löst eine Klonung der Transformer vor dem Anpassen aus. Daher kann die Transformer-Instanz, die an die Pipeline übergeben wird, nicht direkt inspiziert werden. Verwenden Sie das Attribut
named_stepsodersteps, um Schätzer innerhalb der Pipeline zu inspizieren. Das Caching der Transformer ist vorteilhaft, wenn die Anpassung zeitaufwendig ist.- transform_inputListe von Zeichenketten, Standard=None
Dies ermöglicht die Transformation einiger Eingabeargumente für
fit(außerX) durch die Schritte der Pipeline bis zu dem Schritt, der sie benötigt. Die Anforderung wird über das Metadaten-Routing definiert. Dies kann beispielsweise verwendet werden, um einen Validierungssatz durch die Pipeline zu leiten.Sie können dies nur festlegen, wenn das Metadaten-Routing aktiviert ist, was Sie mit
sklearn.set_config(enable_metadata_routing=True)aktivieren können.Hinzugefügt in Version 1.6.
- verbosebool, default=False
Wenn True, wird die Zeit, die für das Anpassen jedes Schritts benötigt wird, beim Abschluss gedruckt.
- Gibt zurück:
- pPipeline
Gibt ein scikit-learn
Pipeline-Objekt zurück.
Siehe auch
PipelineKlasse zur Erstellung einer Pipeline von Transformationen mit einem finalen Schätzer.
Beispiele
>>> from sklearn.naive_bayes import GaussianNB >>> from sklearn.preprocessing import StandardScaler >>> from sklearn.pipeline import make_pipeline >>> make_pipeline(StandardScaler(), GaussianNB(priors=None)) Pipeline(steps=[('standardscaler', StandardScaler()), ('gaussiannb', GaussianNB())])
Galeriebeispiele#


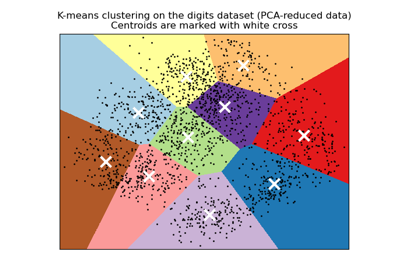
Eine Demo des K-Means Clusterings auf den handschriftlichen Zifferndaten
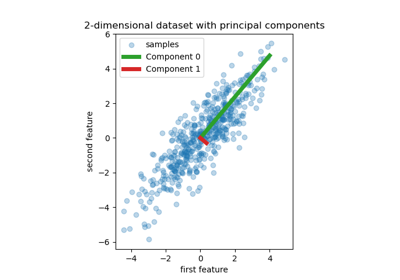
Principal Component Regression vs. Partial Least Squares Regression

Unterstützung für kategorische Merkmale in Gradient Boosting
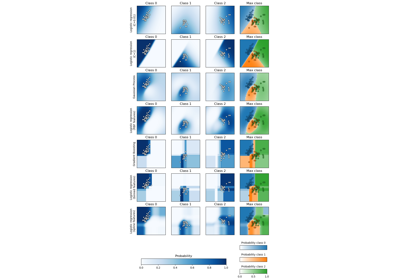
Visualisierung der probabilistischen Vorhersagen eines VotingClassifier



Fehlende Werte mit Varianten von IterativeImputer imputieren

Fehlende Werte imputieren, bevor ein Schätzer erstellt wird

Häufige Fallstricke bei der Interpretation von Koeffizienten linearer Modelle

Partial Dependence und Individual Conditional Expectation Plots

Skalierbares Lernen mit Polynom-Kernel-Approximation



Regularisierungspfad der L1-Logistischen Regression
Poisson-Regression und nicht-normale Verlustfunktion



One-Class SVM vs. One-Class SVM mittels Stochastic Gradient Descent

Manifold Learning auf handschriftlichen Ziffern: Locally Linear Embedding, Isomap…

Vergleich von Anomalieerkennungsalgorithmen zur Ausreißererkennung auf Toy-Datensätzen




Post-Hoc-Anpassung des Entscheidungsschwellenwerts für kostenempfindliches Lernen


Post-hoc-Anpassung des Cut-off-Punkts der Entscheidungskfunktion

Dimensionsreduktion mit Neighborhood Components Analysis

Variierende Regularisierung im Multi-Layer Perceptron