Sobald ein binärer Klassifikator trainiert ist, gibt die Methode predict Klassenvorhersagen aus, die einer Schwellenwertbildung entweder des decision_function oder des predict_proba-Outputs entsprechen. Der Standard-Schwellenwert ist als Posterior-Wahrscheinlichkeitsschätzung von 0.5 oder als Entscheidungs-Score von 0.0 definiert. Diese Standardstrategie ist jedoch möglicherweise nicht optimal für die jeweilige Aufgabe.
Dieses Beispiel zeigt, wie die TunedThresholdClassifierCV verwendet werden kann, um den Entscheidungsschwellenwert basierend auf einer interessierenden Metrik zu optimieren.
# Authors: The scikit-learn developers# SPDX-License-Identifier: BSD-3-Clause
Zur Veranschaulichung des Tunings des Entscheidungsschwellenwerts verwenden wir den Diabetes-Datensatz. Dieser Datensatz ist auf OpenML verfügbar: https://www.openml.org/d/37. Wir verwenden die Funktion fetch_openml, um diesen Datensatz abzurufen.
Wir betrachten das Ziel, um die Art des Problems zu verstehen, mit dem wir es zu tun haben.
target.value_counts()
class
tested_negative 500
tested_positive 268
Name: count, dtype: int64
Wir sehen, dass wir es mit einem binären Klassifikationsproblem zu tun haben. Da die Labels nicht als 0 und 1 kodiert sind, machen wir deutlich, dass wir die Klasse "tested_negative" als negative Klasse (die auch die häufigste ist) und die Klasse "tested_positive" als positive Klasse betrachten.
neg_label,pos_label=target.value_counts().index
Wir können auch beobachten, dass dieses binäre Problem leicht unausgewogen ist, da wir etwa doppelt so viele Stichproben aus der negativen Klasse wie aus der positiven Klasse haben. Bei der Auswertung sollten wir diesen Aspekt berücksichtigen, um die Ergebnisse zu interpretieren.
In einer Jupyter-Umgebung führen Sie diese Zelle bitte erneut aus, um die HTML-Darstellung anzuzeigen, oder vertrauen Sie dem Notebook. Auf GitHub kann die HTML-Darstellung nicht gerendert werden. Versuchen Sie bitte, diese Seite mit nbviewer.org zu laden.
Wir evaluieren unser Modell mittels Kreuzvalidierung. Wir verwenden die Genauigkeit und die balancierte Genauigkeit, um die Leistung unseres Modells zu berichten. Die balancierte Genauigkeit ist eine Metrik, die weniger empfindlich auf Klassenungleichgewichte reagiert und es uns ermöglicht, den Genauigkeitswert in Perspektive zu setzen.
Die Kreuzvalidierung ermöglicht es uns, die Varianz des Entscheidungsschwellenwerts über verschiedene Datenaufteilungen hinweg zu untersuchen. Da der Datensatz jedoch eher klein ist, wäre es nachteilig, mehr als 5 Folds zur Bewertung der Dispersion zu verwenden. Daher verwenden wir eine RepeatedStratifiedKFold, bei der wir mehrere Wiederholungen einer 5-fach-Kreuzvalidierung anwenden.
Unser prädiktives Modell ist erfolgreich darin, die Beziehung zwischen den Daten und dem Ziel zu erfassen. Die Trainings- und Testergebnisse liegen nahe beieinander, was bedeutet, dass unser prädiktives Modell kein Overfitting aufweist. Wir können auch beobachten, dass die balancierte Genauigkeit aufgrund des zuvor erwähnten Klassenungleichgewichts niedriger ist als die Genauigkeit.
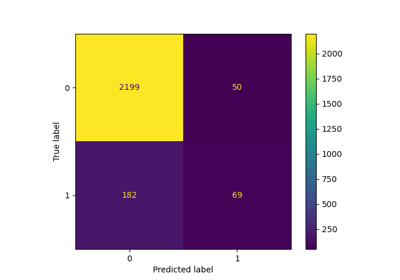
Für diesen Klassifikator belassen wir den Entscheidungsschwellenwert, der zur Umwandlung der Wahrscheinlichkeit der positiven Klasse in eine Klassenvorhersage verwendet wird, bei seinem Standardwert: 0.5. Dieser Schwellenwert ist jedoch möglicherweise nicht optimal. Wenn unser Interesse darin besteht, die balancierte Genauigkeit zu maximieren, sollten wir einen anderen Schwellenwert auswählen, der diese Metrik maximiert.
Der Meta-Schätzer TunedThresholdClassifierCV ermöglicht die Optimierung des Entscheidungsschwellenwerts eines Klassifikators unter Berücksichtigung einer interessierenden Metrik.
Wir erstellen eine TunedThresholdClassifierCV und konfigurieren sie, um die balancierte Genauigkeit zu maximieren. Wir evaluieren das Modell unter Verwendung derselben Kreuzvalidierungsstrategie wie zuvor.
Im Vergleich zum Standardmodell beobachten wir, dass der Score der balancierten Genauigkeit gestiegen ist. Dies geht natürlich auf Kosten eines niedrigeren Genauigkeits-Scores. Das bedeutet, dass unser Modell nun sensitiver für die positive Klasse ist, aber mehr Fehler bei der negativen Klasse macht.
Es ist jedoch wichtig zu beachten, dass dieses optimierte prädiktive Modell intern dasselbe Modell wie das Standardmodell ist: Sie haben die gleichen angepassten Koeffizienten.
importmatplotlib.pyplotaspltvanilla_model_coef=pd.DataFrame([est[-1].coef_.ravel()forestincv_results_vanilla_model["estimator"]],columns=diabetes.feature_names,)tuned_model_coef=pd.DataFrame([est.estimator_[-1].coef_.ravel()forestincv_results_tuned_model["estimator"]],columns=diabetes.feature_names,)fig,ax=plt.subplots(ncols=2,figsize=(12,4),sharex=True,sharey=True)vanilla_model_coef.boxplot(ax=ax[0])ax[0].set_ylabel("Coefficient value")ax[0].set_title("Vanilla model")tuned_model_coef.boxplot(ax=ax[1])ax[1].set_title("Tuned model")_=fig.suptitle("Coefficients of the predictive models")
Nur der Entscheidungsschwellenwert jedes Modells wurde während der Kreuzvalidierung geändert.
decision_threshold=pd.Series([est.best_threshold_forestincv_results_tuned_model["estimator"]],)ax=decision_threshold.plot.kde()ax.axvline(decision_threshold.mean(),color="k",linestyle="--",label=f"Mean decision threshold: {decision_threshold.mean():.2f}",)ax.set_xlabel("Decision threshold")ax.legend(loc="upper right")_=ax.set_title("Distribution of the decision threshold \nacross different cross-validation folds")
Im Durchschnitt maximiert ein Entscheidungsschwellenwert von etwa 0.32 die balancierte Genauigkeit, was vom Standard-Entscheidungsschwellenwert von 0.5 abweicht. Daher ist die Optimierung des Entscheidungsschwellenwerts besonders wichtig, wenn die Ausgabe des prädiktiven Modells zur Entscheidungsfindung verwendet wird. Außerdem sollte die zur Optimierung des Entscheidungsschwellenwerts verwendete Metrik sorgfältig ausgewählt werden. Hier haben wir die balancierte Genauigkeit verwendet, aber sie ist möglicherweise nicht die am besten geeignete Metrik für das vorliegende Problem. Die Wahl der "richtigen" Metrik ist in der Regel problemabhängig und erfordert möglicherweise Fachwissen. Weitere Informationen finden Sie im Beispiel mit dem Titel Post-Tuning des Entscheidungsschwellenwerts für kostensensitive Lernverfahren.
Gesamtlaufzeit des Skripts: (0 Minuten 33,969 Sekunden)