Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Release Highlights für scikit-learn 1.7#
Wir freuen uns, die Veröffentlichung von scikit-learn 1.7 bekannt zu geben! Viele Fehlerbehebungen und Verbesserungen wurden hinzugefügt, ebenso wie einige wichtige neue Funktionen. Nachfolgend beschreiben wir die Highlights dieser Veröffentlichung. Für eine vollständige Liste aller Änderungen siehe die Release Notes.
Um die neueste Version zu installieren (mit pip)
pip install --upgrade scikit-learn
oder mit conda
conda install -c conda-forge scikit-learn
Verbesserte HTML-Darstellung von Estimators#
Die HTML-Darstellung von Estimators enthält nun einen Abschnitt mit der Liste der Parameter und ihren Werten. Nicht-Standard-Parameter sind orange hervorgehoben. Ein Kopier-Button ist ebenfalls verfügbar, um den „vollqualifizierten“ Parameternamen zu kopieren, ohne die Methode get_params aufrufen zu müssen. Dies ist besonders nützlich bei der Definition eines Parameter-Rasters für eine Grid-Suche oder eine Zufallssuche mit einer komplexen Pipeline.
Sehen Sie sich das untenstehende Beispiel an und klicken Sie auf die verschiedenen Estimator-Blöcke, um die verbesserte HTML-Darstellung zu sehen.
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
model = make_pipeline(StandardScaler(with_std=False), LogisticRegression(C=2.0))
model
Benutzerdefiniertes Validierungsset für histogrammbasierte Gradient Boosting Estimators#
Die Klassen ensemble.HistGradientBoostingClassifier und ensemble.HistGradientBoostingRegressor unterstützen nun die direkte Übergabe eines benutzerdefinierten Validierungssets für Early Stopping an die `fit`-Methode über die Parameter X_val, y_val und sample_weight_val. In einer pipeline.Pipeline kann das Validierungsset X_val zusammen mit X über den Parameter transform_input transformiert werden.
import sklearn
from sklearn.datasets import make_classification
from sklearn.ensemble import HistGradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
sklearn.set_config(enable_metadata_routing=True)
X, y = make_classification(random_state=0)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=0)
clf = HistGradientBoostingClassifier()
clf.set_fit_request(X_val=True, y_val=True)
model = Pipeline([("sc", StandardScaler()), ("clf", clf)], transform_input=["X_val"])
model.fit(X, y, X_val=X_val, y_val=y_val)
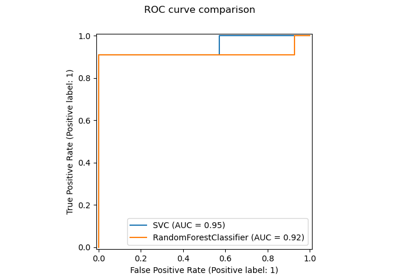
ROC-Kurven aus Kreuzvalidierungsergebnissen plotten#
Die Klasse metrics.RocCurveDisplay verfügt über eine neue Klassenmethode from_cv_results, die es ermöglicht, leicht mehrere ROC-Kurven aus den Ergebnissen von model_selection.cross_validate zu plotten.
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import RocCurveDisplay
from sklearn.model_selection import cross_validate
X, y = make_classification(n_samples=150, random_state=0)
clf = LogisticRegression(random_state=0)
cv_results = cross_validate(clf, X, y, cv=5, return_estimator=True, return_indices=True)
_ = RocCurveDisplay.from_cv_results(cv_results, X, y)

Array API-Unterstützung#
Mehrere Funktionen wurden aktualisiert, um array-API-kompatible Eingaben seit Version 1.6 zu unterstützen, insbesondere Metriken aus dem Modul sklearn.metrics.
Zusätzlich ist es nicht mehr erforderlich, das Paket array-api-compat zu installieren, um die experimentelle Array-API-Unterstützung in scikit-learn zu nutzen.
Bitte lesen Sie die Seite zur Array API-Unterstützung für Anweisungen zur Verwendung von scikit-learn mit Array-API-kompatiblen Bibliotheken wie PyTorch oder CuPy.
Verbesserte API-Konsistenz von Multi-Layer Perceptron#
Der neural_network.MLPRegressor verfügt über einen neuen Parameter loss und unterstützt nun zusätzlich zur Standard-Loss-Funktion "squared_error" auch die "poisson"-Loss-Funktion. Darüber hinaus unterstützen die Estimators neural_network.MLPClassifier und neural_network.MLPRegressor nun Sample Weights. Diese Verbesserungen wurden vorgenommen, um die Konsistenz dieser Estimators im Vergleich zu anderen Estimators in scikit-learn zu verbessern.
Migration zu Sparse Arrays#
Um die Migration von SciPy von Sparse Matrizen zu Sparse Arrays vorzubereiten, akzeptieren nun alle scikit-learn Estimators, die Sparse Matrizen als Eingabe akzeptieren, auch Sparse Arrays.
Gesamtlaufzeit des Skripts: (0 Minuten 0,131 Sekunden)
Verwandte Beispiele