Pipeline#
- class sklearn.pipeline.Pipeline(steps, *, transform_input=None, memory=None, verbose=False)[Quelle]#
Eine Sequenz von Datentransformatoren mit einem optionalen finalen Prädiktor.
Pipelineermöglicht es Ihnen, eine Liste von Transformern sequenziell anzuwenden, um die Daten vorzuverarbeiten und, falls gewünscht, die Sequenz mit einem abschließenden Prädiktor für die prädiktive Modellierung abzuschließen.Zwischenschritte der Pipeline müssen Transformer sein, d.h. sie müssen
fitundtransformMethoden implementieren. Der abschließende Estimator muss nurfitimplementieren. Die Transformer in der Pipeline können mit demmemoryArgument zwischengespeichert werden.Der Zweck der Pipeline ist es, mehrere Schritte zusammenzufassen, die gemeinsam mittels Kreuzvalidierung ausgewertet werden können, während unterschiedliche Parameter eingestellt werden. Dazu ermöglicht sie das Einstellen von Parametern der verschiedenen Schritte unter Verwendung ihrer Namen und des Parameternamens, getrennt durch ein
'__', wie im folgenden Beispiel gezeigt. Ein Estimator eines Schritts kann vollständig ersetzt werden, indem der Parameter mit seinem Namen auf einen anderen Estimator gesetzt wird, oder ein Transformer kann entfernt werden, indem er auf'passthrough'oderNonegesetzt wird.Ein Anwendungsbeispiel für die Verwendung von
Pipelinein Kombination mitGridSearchCVfinden Sie unter Auswahl der Dimensionsreduktion mit Pipeline und GridSearchCV. Das Beispiel Pipelining: Verkettung von PCA und logistischer Regression zeigt, wie mit'__'als Trennzeichen in den Parameternamen auf einer Pipeline nach der besten Konfiguration gesucht wird.Mehr dazu finden Sie im Benutzerhandbuch.
Hinzugefügt in Version 0.5.
- Parameter:
- stepsListe von Tupeln
Liste von (Name des Schritts, Estimator) Tupeln, die in sequenzieller Reihenfolge verkettet werden sollen. Um mit der scikit-learn API kompatibel zu sein, müssen alle Schritte
fitdefinieren. Alle nicht-letzten Schritte müssen außerdemtransformdefinieren. Weitere Details finden Sie unter Kombinieren von Estimators.- transform_inputListe von Strings, Standard=None
Die Namen der Metadaten-Parameter, die von der Pipeline transformiert werden sollen, bevor sie an den Schritt weitergeleitet werden, der sie benötigt.
Dies ermöglicht die Transformation einiger Eingabeargumente für
fit(außerX), die von den Schritten der Pipeline bis zu dem Schritt transformiert werden, der sie benötigt. Die Anforderung wird über Metadaten-Routing definiert. Dies kann beispielsweise verwendet werden, um einen Validierungssatz durch die Pipeline zu leiten.Sie können dies nur festlegen, wenn das Metadaten-Routing aktiviert ist, was Sie mit
sklearn.set_config(enable_metadata_routing=True)aktivieren können.Hinzugefügt in Version 1.6.
- memoryString oder Objekt mit dem joblib.Memory-Interface, Standard=None
Wird verwendet, um die gefitteten Transformer der Pipeline zwischenzuspeichern. Der letzte Schritt wird niemals zwischengespeichert, auch wenn es sich um einen Transformer handelt. Standardmäßig wird keine Zwischenspeicherung durchgeführt. Wenn ein String angegeben wird, ist dies der Pfad zum Cache-Verzeichnis. Die Aktivierung der Zwischenspeicherung löst eine Kopie der Transformer vor dem Fitten aus. Daher kann die dem Pipeline übergebene Transformer-Instanz nicht direkt inspiziert werden. Verwenden Sie das Attribut
named_stepsodersteps, um Estimators innerhalb der Pipeline zu inspizieren. Das Zwischenspeichern von Transformern ist vorteilhaft, wenn das Fitten zeitaufwendig ist. Ein Beispiel für die Aktivierung der Zwischenspeicherung finden Sie unter Zwischenspeichern von Nachbarn.- verbosebool, default=False
Wenn True, wird die beim Fitten jedes Schritts verstrichene Zeit während der Fertigstellung ausgegeben.
- Attribute:
named_stepsBunchZugriff auf die Schritte nach Namen.
classes_ndarray der Form (n_classes,)Die Klassenbezeichnungen.
n_features_in_intAnzahl der Merkmale, die während der ersten Schritts
fitMethode gesehen wurden.feature_names_in_ndarray der Form (n_features_in_,)Namen der Merkmale, die während der ersten Schritts
fitMethode gesehen wurden.
Siehe auch
make_pipelineHilfsfunktion für eine vereinfachte Pipeline-Konstruktion.
Beispiele
>>> from sklearn.svm import SVC >>> from sklearn.preprocessing import StandardScaler >>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import train_test_split >>> from sklearn.pipeline import Pipeline >>> X, y = make_classification(random_state=0) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, ... random_state=0) >>> pipe = Pipeline([('scaler', StandardScaler()), ('svc', SVC())]) >>> # The pipeline can be used as any other estimator >>> # and avoids leaking the test set into the train set >>> pipe.fit(X_train, y_train).score(X_test, y_test) 0.88 >>> # An estimator's parameter can be set using '__' syntax >>> pipe.set_params(svc__C=10).fit(X_train, y_train).score(X_test, y_test) 0.76
- decision_function(X, **params)[Quelle]#
Transformieren Sie die Daten und wenden Sie
decision_functionmit dem abschließenden Estimator an.Rufen Sie
transformjedes Transformers in der Pipeline auf. Die transformierten Daten werden schließlich an den abschließenden Estimator übergeben, der diedecision_functionMethode aufruft. Nur gültig, wenn der abschließende Estimatordecision_functionimplementiert.- Parameter:
- XIterable
Zu prognostizierende Daten. Muss die Eingabeanforderungen des ersten Schritts der Pipeline erfüllen.
- **paramsDict von String -> Objekt
Parameter, die von Schritten angefordert und akzeptiert werden. Jeder Schritt muss bestimmte Metadaten angefordert haben, damit diese Parameter an ihn weitergeleitet werden.
Hinzugefügt in Version 1.4: Nur verfügbar, wenn
enable_metadata_routing=True. Siehe Benutzerhandbuch zur Metadaten-Weiterleitung für weitere Details.
- Gibt zurück:
- y_scorendarray der Form (n_samples, n_classes)
Ergebnis des Aufrufs von
decision_functionauf dem abschließenden Estimator.
- fit(X, y=None, **params)[Quelle]#
Fittet das Modell.
Fittet alle Transformer nacheinander und transformiert die Daten sequenziell. Schließlich werden die transformierten Daten mit dem abschließenden Estimator gefittet.
- Parameter:
- XIterable
Trainingsdaten. Müssen die Eingabeanforderungen des ersten Schritts der Pipeline erfüllen.
- yIterable, Standard=None
Trainingsziele. Müssen die Label-Anforderungen für alle Schritte der Pipeline erfüllen.
- **paramsDict von str -> Objekt
Wenn
enable_metadata_routing=False(Standard): Parameter, die an diefitMethode jedes Schritts übergeben werden, wobei jeder Parametername präfixiert ist, so dass der Parameterpfür den Schrittsden Schlüssels__phat.Wenn
enable_metadata_routing=True: Parameter, die von Schritten angefordert und akzeptiert werden. Jeder Schritt muss bestimmte Metadaten angefordert haben, damit diese Parameter an ihn weitergeleitet werden.
Geändert in Version 1.4: Parameter werden nun auch an die
transformMethode der Zwischenschritte übergeben, wenn sie angefordert werden undenable_metadata_routing=Trueüberset_configgesetzt ist.Weitere Details finden Sie im Benutzerhandbuch für Metadaten-Routing.
- Gibt zurück:
- selfobject
Pipeline mit gefitteten Schritten.
- fit_predict(X, y=None, **params)[Quelle]#
Transformieren Sie die Daten und wenden Sie
fit_predictmit dem abschließenden Estimator an.Rufen Sie
fit_transformjedes Transformers in der Pipeline auf. Die transformierten Daten werden schließlich an den abschließenden Estimator übergeben, der diefit_predictMethode aufruft. Nur gültig, wenn der abschließende Estimatorfit_predictimplementiert.- Parameter:
- XIterable
Trainingsdaten. Müssen die Eingabeanforderungen des ersten Schritts der Pipeline erfüllen.
- yIterable, Standard=None
Trainingsziele. Müssen die Label-Anforderungen für alle Schritte der Pipeline erfüllen.
- **paramsDict von str -> Objekt
Wenn
enable_metadata_routing=False(Standard): Parameter für den Aufruf vonpredictam Ende aller Transformationen in der Pipeline.Wenn
enable_metadata_routing=True: Parameter, die von Schritten angefordert und akzeptiert werden. Jeder Schritt muss bestimmte Metadaten angefordert haben, damit diese Parameter an ihn weitergeleitet werden.
Hinzugefügt in Version 0.20.
Geändert in Version 1.4: Parameter werden nun auch an die
transformMethode der Zwischenschritte übergeben, wenn sie angefordert werden undenable_metadata_routing=True.Weitere Details finden Sie im Benutzerhandbuch für Metadaten-Routing.
Beachten Sie, dass, obwohl dies zur Rückgabe von Unsicherheiten von einigen Modellen mit
return_stdoderreturn_covverwendet werden kann, Unsicherheiten, die durch die Transformationen in der Pipeline generiert werden, nicht an den abschließenden Estimator weitergegeben werden.
- Gibt zurück:
- y_predndarray
Ergebnis des Aufrufs von
fit_predictauf dem abschließenden Estimator.
- fit_transform(X, y=None, **params)[Quelle]#
Fittet das Modell und transformiert mit dem abschließenden Estimator.
Fittet alle Transformer nacheinander und transformiert die Daten sequenziell. Nur gültig, wenn der abschließende Estimator entweder
fit_transformoderfitundtransformimplementiert.- Parameter:
- XIterable
Trainingsdaten. Müssen die Eingabeanforderungen des ersten Schritts der Pipeline erfüllen.
- yIterable, Standard=None
Trainingsziele. Müssen die Label-Anforderungen für alle Schritte der Pipeline erfüllen.
- **paramsDict von str -> Objekt
Wenn
enable_metadata_routing=False(Standard): Parameter, die an diefitMethode jedes Schritts übergeben werden, wobei jeder Parametername präfixiert ist, so dass der Parameterpfür den Schrittsden Schlüssels__phat.Wenn
enable_metadata_routing=True: Parameter, die von Schritten angefordert und akzeptiert werden. Jeder Schritt muss bestimmte Metadaten angefordert haben, damit diese Parameter an ihn weitergeleitet werden.
Geändert in Version 1.4: Parameter werden nun auch an die
transformMethode der Zwischenschritte übergeben, wenn sie angefordert werden undenable_metadata_routing=True.Weitere Details finden Sie im Benutzerhandbuch für Metadaten-Routing.
- Gibt zurück:
- Xtndarray der Form (n_samples, n_transformed_features)
Transformierte Samples.
- get_feature_names_out(input_features=None)[Quelle]#
Holt die Ausgabemerkmale für die Transformation.
Transformiert Eingabemerkmale mithilfe der Pipeline.
- Parameter:
- input_featuresarray-like von str oder None, default=None
Eingabemerkmale.
- Gibt zurück:
- feature_names_outndarray von str-Objekten
Transformierte Merkmalnamen.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRouter
Ein
MetadataRouter, der die Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
Gibt die im Konstruktor übergebenen Parameter sowie die in den
stepsderPipelineenthaltenen Estimators zurück.- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsMapping von String zu beliebig
Parameternamen, zugeordnet ihren Werten.
- inverse_transform(X, **params)[Quelle]#
Wendet
inverse_transformfür jeden Schritt in umgekehrter Reihenfolge an.Alle Estimators in der Pipeline müssen
inverse_transformunterstützen.- Parameter:
- XArray-ähnlich der Form (n_samples, n_transformed_features)
Datenpunkte, wobei
n_samplesdie Anzahl der Samples undn_featuresdie Anzahl der Merkmale ist. Muss die Eingabeanforderungen derinverse_transformMethode des letzten Schritts der Pipeline erfüllen.- **paramsDict von str -> Objekt
Parameter, die von Schritten angefordert und akzeptiert werden. Jeder Schritt muss bestimmte Metadaten angefordert haben, damit diese Parameter an ihn weitergeleitet werden.
Hinzugefügt in Version 1.4: Nur verfügbar, wenn
enable_metadata_routing=True. Siehe Benutzerhandbuch zur Metadaten-Weiterleitung für weitere Details.
- Gibt zurück:
- X_originalndarray von der Form (n_samples, n_features)
Invers transformierte Daten, d.h. Daten im ursprünglichen Merkmalsraum.
- property named_steps#
Zugriff auf die Schritte nach Namen.
Schreibgeschütztes Attribut zum Zugriff auf jeden Schritt anhand seines Namens. Schlüssel sind die Schrittnamen und Werte sind die Schrittobjekte.
- predict(X, **params)[Quelle]#
Transformieren Sie die Daten und wenden Sie
predictmit dem abschließenden Estimator an.Rufen Sie
transformjedes Transformers in der Pipeline auf. Die transformierten Daten werden schließlich an den abschließenden Estimator übergeben, der diepredictMethode aufruft. Nur gültig, wenn der abschließende Estimatorpredictimplementiert.- Parameter:
- XIterable
Zu prognostizierende Daten. Muss die Eingabeanforderungen des ersten Schritts der Pipeline erfüllen.
- **paramsDict von str -> Objekt
Wenn
enable_metadata_routing=False(Standard): Parameter für den Aufruf vonpredictam Ende aller Transformationen in der Pipeline.Wenn
enable_metadata_routing=True: Parameter, die von Schritten angefordert und akzeptiert werden. Jeder Schritt muss bestimmte Metadaten angefordert haben, damit diese Parameter an ihn weitergeleitet werden.
Hinzugefügt in Version 0.20.
Geändert in Version 1.4: Parameter werden nun auch an die
transformMethode der Zwischenschritte übergeben, wenn sie angefordert werden undenable_metadata_routing=Trueüberset_configgesetzt ist.Weitere Details finden Sie im Benutzerhandbuch für Metadaten-Routing.
Beachten Sie, dass, obwohl dies zur Rückgabe von Unsicherheiten von einigen Modellen mit
return_stdoderreturn_covverwendet werden kann, Unsicherheiten, die durch die Transformationen in der Pipeline generiert werden, nicht an den abschließenden Estimator weitergegeben werden.
- Gibt zurück:
- y_predndarray
Ergebnis des Aufrufs von
predictauf dem abschließenden Estimator.
- predict_log_proba(X, **params)[Quelle]#
Transformieren Sie die Daten und wenden Sie
predict_log_probamit dem abschließenden Estimator an.Rufen Sie
transformjedes Transformers in der Pipeline auf. Die transformierten Daten werden schließlich an den abschließenden Estimator übergeben, der diepredict_log_probaMethode aufruft. Nur gültig, wenn der abschließende Estimatorpredict_log_probaimplementiert.- Parameter:
- XIterable
Zu prognostizierende Daten. Muss die Eingabeanforderungen des ersten Schritts der Pipeline erfüllen.
- **paramsDict von str -> Objekt
Wenn
enable_metadata_routing=False(Standard): Parameter für den Aufruf vonpredict_log_probaam Ende aller Transformationen in der Pipeline.Wenn
enable_metadata_routing=True: Parameter, die von Schritten angefordert und akzeptiert werden. Jeder Schritt muss bestimmte Metadaten angefordert haben, damit diese Parameter an ihn weitergeleitet werden.
Hinzugefügt in Version 0.20.
Geändert in Version 1.4: Parameter werden nun auch an die
transformMethode der Zwischenschritte übergeben, wenn sie angefordert werden undenable_metadata_routing=True.Weitere Details finden Sie im Benutzerhandbuch für Metadaten-Routing.
- Gibt zurück:
- y_log_probandarray der Form (n_samples, n_classes)
Ergebnis des Aufrufs von
predict_log_probaauf dem abschließenden Estimator.
- predict_proba(X, **params)[Quelle]#
Transformieren Sie die Daten und wenden Sie
predict_probamit dem abschließenden Estimator an.Rufen Sie
transformjedes Transformers in der Pipeline auf. Die transformierten Daten werden schließlich an den abschließenden Estimator übergeben, der diepredict_probaMethode aufruft. Nur gültig, wenn der abschließende Estimatorpredict_probaimplementiert.- Parameter:
- XIterable
Zu prognostizierende Daten. Muss die Eingabeanforderungen des ersten Schritts der Pipeline erfüllen.
- **paramsDict von str -> Objekt
Wenn
enable_metadata_routing=False(Standard): Parameter für den Aufruf vonpredict_probaam Ende aller Transformationen in der Pipeline.Wenn
enable_metadata_routing=True: Parameter, die von Schritten angefordert und akzeptiert werden. Jeder Schritt muss bestimmte Metadaten angefordert haben, damit diese Parameter an ihn weitergeleitet werden.
Hinzugefügt in Version 0.20.
Geändert in Version 1.4: Parameter werden nun auch an die
transformMethode der Zwischenschritte übergeben, wenn sie angefordert werden undenable_metadata_routing=True.Weitere Details finden Sie im Benutzerhandbuch für Metadaten-Routing.
- Gibt zurück:
- y_probandarray der Form (n_samples, n_classes)
Ergebnis des Aufrufs von
predict_probaauf dem abschließenden Estimator.
- score(X, y=None, sample_weight=None, **params)[Quelle]#
Transformieren Sie die Daten und wenden Sie
scoremit dem abschließenden Estimator an.Rufen Sie
transformjedes Transformers in der Pipeline auf. Die transformierten Daten werden schließlich an den abschließenden Estimator übergeben, der diescoreMethode aufruft. Nur gültig, wenn der abschließende Estimatorscoreimplementiert.- Parameter:
- XIterable
Zu prognostizierende Daten. Muss die Eingabeanforderungen des ersten Schritts der Pipeline erfüllen.
- yIterable, Standard=None
Zu bewertende Ziele. Müssen die Label-Anforderungen für alle Schritte der Pipeline erfüllen.
- sample_weightArray-ähnlich, Standard=None
Wenn nicht None, wird dieses Argument als Keyword-Argument
sample_weightan diescoreMethode des abschließenden Estimators übergeben.- **paramsDict von str -> Objekt
Parameter, die von Schritten angefordert und akzeptiert werden. Jeder Schritt muss bestimmte Metadaten angefordert haben, damit diese Parameter an ihn weitergeleitet werden.
Hinzugefügt in Version 1.4: Nur verfügbar, wenn
enable_metadata_routing=True. Siehe Benutzerhandbuch zur Metadaten-Weiterleitung für weitere Details.
- Gibt zurück:
- scorefloat
Ergebnis des Aufrufs von
scoreauf dem abschließenden Estimator.
- score_samples(X)[Quelle]#
Transformieren Sie die Daten und wenden Sie
score_samplesmit dem abschließenden Estimator an.Rufen Sie
transformjedes Transformers in der Pipeline auf. Die transformierten Daten werden schließlich an den abschließenden Estimator übergeben, der diescore_samplesMethode aufruft. Nur gültig, wenn der abschließende Estimatorscore_samplesimplementiert.- Parameter:
- XIterable
Zu prognostizierende Daten. Muss die Eingabeanforderungen des ersten Schritts der Pipeline erfüllen.
- Gibt zurück:
- y_scorendarray der Form (n_samples,)
Ergebnis des Aufrufs von
score_samplesauf dem abschließenden Estimator.
- set_output(*, transform=None)[Quelle]#
Setzt den Ausgabebereich, wenn
"transform"und"fit_transform"aufgerufen werden.Der Aufruf von
set_outputsetzt die Ausgabe aller Estimators insteps.- Parameter:
- transform{“default”, “pandas”, “polars”}, default=None
Konfiguriert die Ausgabe von
transformundfit_transform."default": Standardausgabeformat eines Transformers"pandas": DataFrame-Ausgabe"polars": Polars-AusgabeNone: Die Transformationskonfiguration bleibt unverändert
Hinzugefügt in Version 1.4: Die Option
"polars"wurde hinzugefügt.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_params(**kwargs)[Quelle]#
Setzt die Parameter dieses Schätzers.
Gültige Parameternamen können mit
get_params()aufgelistet werden. Beachten Sie, dass Sie die Parameter der Estimators, die instepsenthalten sind, direkt setzen können.- Parameter:
- **kwargsdict
Parameter dieses Estimators oder Parameter von Estimators, die in
stepsenthalten sind. Parameter der Schritte können mit ihrem Namen und dem Parameternamen, getrennt durch ein ‘__’, gesetzt werden.
- Gibt zurück:
- selfobject
Pipeline-Klasseninstanz.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') Pipeline[Quelle]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- transform(X, **params)[Quelle]#
Transformieren Sie die Daten und wenden Sie
transformmit dem abschließenden Estimator an.Rufen Sie
transformjedes Transformers in der Pipeline auf. Die transformierten Daten werden schließlich an den abschließenden Estimator übergeben, der dietransformMethode aufruft. Nur gültig, wenn der abschließende Estimatortransformimplementiert.Dies funktioniert auch, wenn der abschließende Estimator
Noneist, in welchem Fall alle vorherigen Transformationen angewendet werden.- Parameter:
- XIterable
Zu transformierende Daten. Müssen die Eingabeanforderungen des ersten Schritts der Pipeline erfüllen.
- **paramsDict von str -> Objekt
Parameter, die von Schritten angefordert und akzeptiert werden. Jeder Schritt muss bestimmte Metadaten angefordert haben, damit diese Parameter an ihn weitergeleitet werden.
Hinzugefügt in Version 1.4: Nur verfügbar, wenn
enable_metadata_routing=True. Siehe Benutzerhandbuch zur Metadaten-Weiterleitung für weitere Details.
- Gibt zurück:
- Xtndarray der Form (n_samples, n_transformed_features)
Transformierte Daten.
Galeriebeispiele#


Dimensionsreduktion auswählen mit Pipeline und GridSearchCV

Pipelining: Verkettung einer PCA und einer logistischen Regression



Permutations-Wichtigkeit vs. Random Forest Merkmals-Wichtigkeit (MDI)
Poisson-Regression und nicht-normale Verlustfunktion


Modellkomplexität und kreuzvalidierter Score ausbalancieren

Beispiel-Pipeline für Textmerkmal-Extraktion und -Bewertung

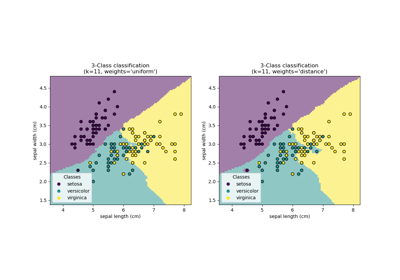

Vergleich von Nächsten Nachbarn mit und ohne Neighborhood Components Analysis

Restricted Boltzmann Machine Merkmale für Ziffernklassifikation

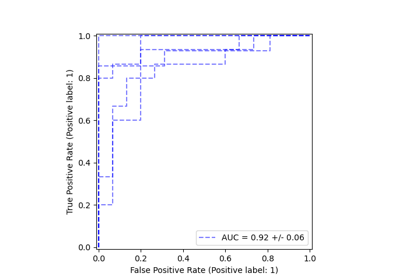
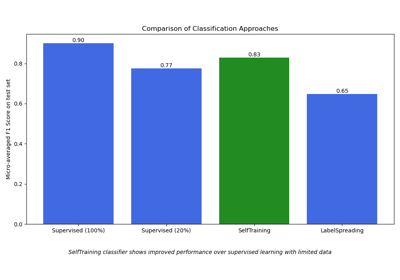
Semi-überwachte Klassifikation auf einem Textdatensatz
