PartialDependenceDisplay#
- class sklearn.inspection.PartialDependenceDisplay(pd_results, *, features, feature_names, target_idx, deciles, kind='average', subsample=1000, random_state=None, is_categorical=None)[Quelle]#
Partial Dependence Plot (PDP) und Individual Conditional Expectation (ICE).
Es wird empfohlen,
from_estimatorzu verwenden, um einPartialDependenceDisplayzu erstellen. Alle Parameter werden als Attribute gespeichert.Allgemeine Informationen zu Visualisierungswerkzeugen von
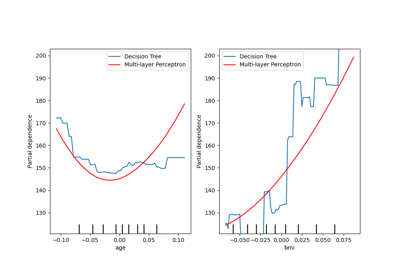
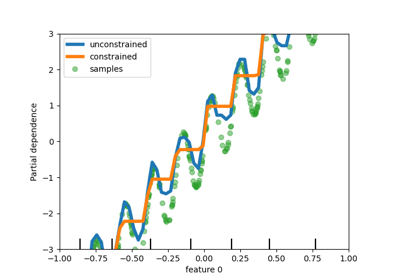
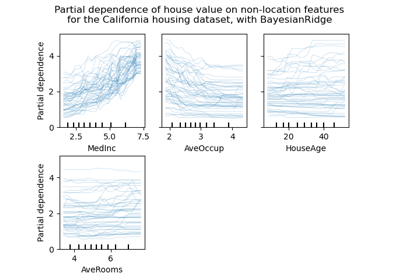
scikit-learnfinden Sie im Visualisierungsleitfaden. Anleitungen zur Interpretation dieser Diagramme finden Sie im Inspektionsleitfaden.Ein Beispiel für die Verwendung dieser Klasse finden Sie im folgenden Beispiel: Erweiterte Diagrammerstellung mit Partial Dependence.
Hinzugefügt in Version 0.22.
- Parameter:
- pd_resultsListe von Bunch
Ergebnisse von
partial_dependencefürfeatures.- featuresListe von (int,) oder Liste von (int, int)
Indizes der Merkmale für ein gegebenes Diagramm. Ein Tupel mit einer ganzen Zahl erstellt eine Partial-Dependence-Kurve eines Merkmals. Ein Tupel mit zwei ganzen Zahlen erstellt eine zweidimensionale Partial-Dependence-Kurve als Konturdiagramm.
- feature_namesListe von str
Namen der Merkmale, die den Indizes in
featuresentsprechen.- target_idxint
In einem Multiklassen-Szenario gibt die Klasse an, für die die PDPs berechnet werden sollen. Beachten Sie, dass bei binärer Klassifizierung immer die positive Klasse (Index 1) verwendet wird.
In einem Multi-Output-Szenario gibt die Aufgabe an, für die die PDPs berechnet werden sollen.
Ignoriert bei binärer Klassifizierung oder klassischen Regressionsszenarien.
- decilesdict
Dezile für die Merkmalsindizes in
features.- kind{‘average’, ‘individual’, ‘both’} oder Liste von solchen str, Standard=‘average’
Ob die partielle Abhängigkeit gemittelt über alle Stichproben im Datensatz oder eine Linie pro Stichprobe oder beides gezeichnet werden soll.
kind='average'ergibt das traditionelle PD-Diagramm;kind='individual'ergibt das ICE-Diagramm;kind='both'ergibt das Zeichnen sowohl der ICE- als auch der PD-Diagramme auf demselben Diagramm.
Eine Liste solcher Zeichenfolgen kann bereitgestellt werden, um
kindpro Diagramm anzugeben. Die Länge der Liste sollte mit der Anzahl der infeaturesangeforderten Interaktionen übereinstimmen.Hinweis
ICE („individual“ oder „both“) ist keine gültige Option für zweidimensionale Interaktionsdiagramme. Daher wird ein Fehler ausgelöst. Zweidimensionale Interaktionsdiagramme sollten immer so konfiguriert werden, dass sie die „average“-Art verwenden.
Hinweis
Die schnelle Option
method='recursion'ist nur fürkind='average'undsample_weights=Noneverfügbar. Das Berechnen individueller Abhängigkeiten und gewichteter Mittelwerte erfordert die Verwendung der langsameren Methodemethod='brute'.Hinzugefügt in Version 0.24: Parameter
kindmit den Optionen'average','individual'und'both'hinzugefügt.Hinzugefügt in Version 1.1: Möglichkeit hinzugefügt, eine Liste von Zeichenfolgen zu übergeben, um
kindfür jedes Diagramm anzugeben.- subsamplefloat, int oder None, Standard=1000
Stichproben für ICE-Kurven, wenn
kind„individual“ oder „both“ ist. Wenn float, sollte er zwischen 0,0 und 1,0 liegen und den Anteil des Datensatzes darstellen, der zum Zeichnen von ICE-Kurven verwendet wird. Wenn int, stellt er die maximale absolute Anzahl der zu verwendenden Stichproben dar.Beachten Sie, dass der vollständige Datensatz immer noch zur Berechnung der partiellen Abhängigkeit verwendet wird, wenn
kind='both'ist.Hinzugefügt in Version 0.24.
- random_stateint, RandomState-Instanz oder None, default=None
Steuert die Zufälligkeit der ausgewählten Stichproben, wenn subsamples nicht
Noneist. Siehe Glossar für Details.Hinzugefügt in Version 0.24.
- is_categoricalListe von (bool,) oder Liste von (bool, bool), Standard=None
Gibt an, ob jedes Zielmerkmal in
featureskategorisch ist oder nicht. Die Liste sollte die gleiche Größe wiefeatureshaben. WennNone, werden alle Merkmale als kontinuierlich angenommen.Hinzugefügt in Version 1.2.
- Attribute:
- bounding_ax_matplotlib Axes oder None
Wenn
axeine Achse oder None ist, istbounding_ax_die Achse, auf der das Gitter der Partial-Dependence-Diagramme gezeichnet wird. Wennaxeine Liste von Achsen oder ein NumPy-Array von Achsen ist, istbounding_ax_None.- axes_ndarray von matplotlib Axes
Wenn
axeine Achse oder None ist, istaxes_[i, j]die Achse in der i-ten Zeile und j-ten Spalte. Wennaxeine Liste von Achsen ist, istaxes_[i]das i-te Element inax. Elemente, die None sind, entsprechen einer nicht vorhandenen Achse an dieser Position.- lines_ndarray von matplotlib Artists
Wenn
axeine Achse oder None ist, istlines_[i, j]die partielle Abhängigkeitskurve in der i-ten Zeile und j-ten Spalte. Wennaxeine Liste von Achsen ist, istlines_[i]die partielle Abhängigkeitskurve, die dem i-ten Element inaxentspricht. Elemente, die None sind, entsprechen einer nicht vorhandenen Achse oder einer Achse, die keine Linienzeichnung enthält.- deciles_vlines_ndarray von matplotlib LineCollection
Wenn
axeine Achse oder None ist, istvlines_[i, j]die Linienkollektion, die die Dezile der x-Achse der i-ten Zeile und j-ten Spalte darstellt. Wennaxeine Liste von Achsen ist, entsprichtvlines_[i]dem i-ten Element inax. Elemente, die None sind, entsprechen einer nicht vorhandenen Achse oder einer Achse, die kein PDP-Diagramm enthält.Hinzugefügt in Version 0.23.
- deciles_hlines_ndarray von matplotlib LineCollection
Wenn
axeine Achse oder None ist, istvlines_[i, j]die Linienkollektion, die die Dezile der y-Achse der i-ten Zeile und j-ten Spalte darstellt. Wennaxeine Liste von Achsen ist, entsprichtvlines_[i]dem i-ten Element inax. Elemente, die None sind, entsprechen einer nicht vorhandenen Achse oder einer Achse, die kein zweidimensionales Diagramm enthält.Hinzugefügt in Version 0.23.
- contours_ndarray von matplotlib Artists
Wenn
axeine Achse oder None ist, istcontours_[i, j]das partielle Abhängigkeitsdiagramm in der i-ten Zeile und j-ten Spalte. Wennaxeine Liste von Achsen ist, istcontours_[i]das partielle Abhängigkeitsdiagramm, das dem i-ten Element inaxentspricht. Elemente, die None sind, entsprechen einer nicht vorhandenen Achse oder einer Achse, die kein Konturdiagramm enthält.- bars_ndarray von matplotlib Artists
Wenn
axeine Achse oder None ist, istbars_[i, j]das partielle Abhängigkeitsbalkendiagramm in der i-ten Zeile und j-ten Spalte (für ein kategoriales Merkmal). Wennaxeine Liste von Achsen ist, istbars_[i]das partielle Abhängigkeitsbalkendiagramm, das dem i-ten Element inaxentspricht. Elemente, die None sind, entsprechen einer nicht vorhandenen Achse oder einer Achse, die kein Balkendiagramm enthält.Hinzugefügt in Version 1.2.
- heatmaps_ndarray von matplotlib Artists
Wenn
axeine Achse oder None ist, istheatmaps_[i, j]die partielle Abhängigkeits-Heatmap in der i-ten Zeile und j-ten Spalte (für ein Paar kategorialer Merkmale). Wennaxeine Liste von Achsen ist, istheatmaps_[i]die partielle Abhängigkeits-Heatmap, die dem i-ten Element inaxentspricht. Elemente, die None sind, entsprechen einer nicht vorhandenen Achse oder einer Achse, die keine Heatmap enthält.Hinzugefügt in Version 1.2.
- figure_matplotlib Figure
Figur, die partielle Abhängigkeitsdiagramme enthält.
Siehe auch
partial_dependenceBerechnet partielle Abhängigkeitswerte.
PartialDependenceDisplay.from_estimatorZeichnet partielle Abhängigkeiten.
Beispiele
>>> import numpy as np >>> import matplotlib.pyplot as plt >>> from sklearn.datasets import make_friedman1 >>> from sklearn.ensemble import GradientBoostingRegressor >>> from sklearn.inspection import PartialDependenceDisplay >>> from sklearn.inspection import partial_dependence >>> X, y = make_friedman1() >>> clf = GradientBoostingRegressor(n_estimators=10).fit(X, y) >>> features, feature_names = [(0,)], [f"Features #{i}" for i in range(X.shape[1])] >>> deciles = {0: np.linspace(0, 1, num=5)} >>> pd_results = partial_dependence( ... clf, X, features=0, kind="average", grid_resolution=5) >>> display = PartialDependenceDisplay( ... [pd_results], features=features, feature_names=feature_names, ... target_idx=0, deciles=deciles ... ) >>> display.plot(pdp_lim={1: (-1.38, 0.66)}) <...> >>> plt.show()

- classmethod from_estimator(estimator, X, features, *, sample_weight=None, categorical_features=None, feature_names=None, target=None, response_method='auto', n_cols=3, grid_resolution=100, percentiles=(0.05, 0.95), custom_values=None, method='auto', n_jobs=None, verbose=0, line_kw=None, ice_lines_kw=None, pd_line_kw=None, contour_kw=None, ax=None, kind='average', centered=False, subsample=1000, random_state=None)[Quelle]#
Partial-Dependence- (PD) und Individual Conditional Expectation- (ICE) Diagramme.
Partial-Dependence-Diagramme, Individual Conditional Expectation-Diagramme oder eine Überlagerung von beidem können durch Einstellen des Parameters
kindgezeichnet werden. Diese Methode erstellt ein Diagramm für jeden Eintrag infeatures. Die Diagramme sind in einem Gitter mitn_colsSpalten angeordnet. Bei eindimensionalen Partial-Dependence-Diagrammen werden die Dezile der Merkmalswerte auf der x-Achse angezeigt. Bei zweidimensionalen Diagrammen werden die Dezile auf beiden Achsen angezeigt und PDPs sind Konturdiagramme.Allgemeine Informationen zu Visualisierungswerkzeugen von
scikit-learnfinden Sie im Visualisierungsleitfaden. Anleitungen zur Interpretation dieser Diagramme finden Sie im Inspektionsleitfaden.Ein Beispiel für die Verwendung dieser Klassenmethode finden Sie unter Partial Dependence und Individual Conditional Expectation Plots.
Hinweis
PartialDependenceDisplay.from_estimatorunterstützt nicht die Verwendung derselben Achsen mit mehreren Aufrufen. Um die partielle Abhängigkeit für mehrere Schätzer zu zeichnen, übergeben Sie bitte die durch den ersten Aufruf erstellten Achsen an den zweiten Aufruf.>>> from sklearn.inspection import PartialDependenceDisplay >>> from sklearn.datasets import make_friedman1 >>> from sklearn.linear_model import LinearRegression >>> from sklearn.ensemble import RandomForestRegressor >>> X, y = make_friedman1() >>> est1 = LinearRegression().fit(X, y) >>> est2 = RandomForestRegressor().fit(X, y) >>> disp1 = PartialDependenceDisplay.from_estimator(est1, X, ... [1, 2]) >>> disp2 = PartialDependenceDisplay.from_estimator(est2, X, [1, 2], ... ax=disp1.axes_)
Warnung
Für
GradientBoostingClassifierundGradientBoostingRegressorberücksichtigt die Methode'recursion'(die standardmäßig verwendet wird) nicht deninit-Prädiktor des Boosting-Prozesses. In der Praxis führt dies zu denselben Werten wie'brute'bis auf eine konstante Verschiebung in der Zielantwort, vorausgesetzt,initist ein konstanter Schätzer (was der Standard ist). Wenninitjedoch kein konstanter Schätzer ist, sind die partiellen Abhängigkeitswerte für'recursion'falsch, da die Verschiebung stichprobenabhängig ist. Es ist vorzuziehen, die Methode'brute'zu verwenden. Beachten Sie, dass dies nur fürGradientBoostingClassifierundGradientBoostingRegressorgilt, nicht aber fürHistGradientBoostingClassifierundHistGradientBoostingRegressor.Hinzugefügt in Version 1.0.
- Parameter:
- estimatorBaseEstimator
Ein trainiertes Schätzerobjekt, das predict, predict_proba oder decision_function implementiert. Multi-Output-Multi-Klassen-Klassifikatoren werden nicht unterstützt.
- X{array-like, dataframe} der Form (n_samples, n_features)
Xwird verwendet, um ein Gitter von Werten für die Ziel-featureszu generieren (an denen die partielle Abhängigkeit ausgewertet wird) und um Werte für die komplementären Merkmale zu generieren, wenn diemethod'brute'ist.- featuresListe von {int, str, Paar von int, Paar von str}
Die Zielmerkmale, für die PDPs erstellt werden sollen. Wenn
features[i]eine ganze Zahl oder ein String ist, wird eine eindimensionale PDP erstellt; wennfeatures[i]ein Tupel ist, wird eine zweidimensionale PDP erstellt (nur unterstützt mitkind='average'). Jedes Tupel muss eine Größe von 2 haben. Wenn ein Eintrag ein String ist, muss er infeature_namesvorhanden sein.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte werden verwendet, um gewichtete Mittelwerte bei der Mittelung der Modellantwort zu berechnen. Wenn
None, dann sind die Stichproben gleich gewichtet. Wennsample_weightnichtNoneist, wirdmethodauf'brute'gesetzt. Beachten Sie, dasssample_weightfürkind='individual'ignoriert wird.Hinzugefügt in Version 1.3.
- categorical_featuresarray-like der Form (n_features,) oder (n_categorical_features,), dtype={bool, int, str}, Standard=None
Zeigt die kategorialen Merkmale an.
None: kein Merkmal wird als kategorial betrachtet;boolsches Array-like: boolsche Maske der Form
(n_features,), die angibt, welche Merkmale kategorial sind. Somit hat dieses Array die gleiche Form wieX.shape[1];Ganzzahl- oder Zeichenketten-Array-like: Ganzzahlindizes oder Zeichenketten, die kategoriale Merkmale angeben.
Hinzugefügt in Version 1.2.
- feature_namesarray-like der Form (n_features,), dtype=str, Standard=None
Name jedes Merkmals;
feature_names[i]enthält den Namen des Merkmals mit Indexi. Standardmäßig entspricht der Name des Merkmals seinem numerischen Index für NumPy-Arrays und seinem Spaltennamen für Pandas-DataFrames.- targetint, Standard=None
In einem Multiklassen-Szenario gibt die Klasse an, für die die PDPs berechnet werden sollen. Beachten Sie, dass bei binärer Klassifizierung immer die positive Klasse (Index 1) verwendet wird.
In einem Multi-Output-Szenario gibt die Aufgabe an, für die die PDPs berechnet werden sollen.
Ignoriert bei binärer Klassifizierung oder klassischen Regressionsszenarien.
- response_method{‘auto’, ‘predict_proba’, ‘decision_function’}, Standard=‘auto’
Gibt an, ob predict_proba oder decision_function als Zielantwort verwendet werden soll. Für Regressoren wird dieser Parameter ignoriert und die Antwort ist immer die Ausgabe von predict. Standardmäßig wird predict_proba zuerst versucht und zu decision_function zurückgefallen, wenn diese nicht existiert. Wenn
method'recursion'ist, ist die Antwort immer die Ausgabe von decision_function.- n_colsint, Standard=3
Die maximale Anzahl von Spalten im Gitterdiagramm. Nur aktiv, wenn
axeine einzelne Achse ist oderNone.- grid_resolutionint, Standard=100
Die Anzahl der gleichmäßig verteilten Punkte auf den Achsen der Diagramme für jedes Zielmerkmal. Dieser Parameter wird durch
custom_valuesüberschrieben, wenn dieser Parameter gesetzt ist.- percentilesTupel von float, Standard=(0.05, 0.95)
Das untere und obere Perzentil, das zur Erstellung der Extremwerte für die PDP-Achsen verwendet wird. Muss im Bereich [0, 1] liegen. Dieser Parameter wird durch
custom_valuesüberschrieben, wenn dieser Parameter gesetzt ist.- custom_valuesdict
Ein Dictionary, das den Index eines Elements von
featuresauf ein Array von Werten abbildet, an denen die partielle Abhängigkeit für dieses Merkmal berechnet werden soll. Das Setzen eines Wertebereichs für ein Merkmal überschreibtgrid_resolutionundpercentiles.Hinzugefügt in Version 1.7.
- methodstr, Standard=‘auto’
Die Methode zur Berechnung der gemittelten Vorhersagen.
'recursion'wird nur für einige baumbasierte Schätzer unterstützt (nämlichGradientBoostingClassifier,GradientBoostingRegressor,HistGradientBoostingClassifier,HistGradientBoostingRegressor,DecisionTreeRegressor,RandomForestRegressor, ist aber hinsichtlich der Geschwindigkeit effizienter. Mit dieser Methode ist die Zielantwort eines Klassifikators immer die Entscheidungsgrenze, nicht die Wahrscheinlichkeiten. Da die Methode'recursion'implizit den Durchschnitt der ICEs berechnet, ist sie nicht mit ICE kompatibel und daher musskind'average'sein.'brute'wird für jeden Schätzer unterstützt, ist aber rechenintensiver.'auto':'recursion'wird für Schätzer verwendet, die es unterstützen, und andernfalls'brute'. Wennsample_weightnichtNoneist, wird'brute'unabhängig vom Schätzer verwendet.
Bitte lesen Sie diesen Hinweis, um die Unterschiede zwischen der
'brute'und der'recursion'Methode zu erfahren.- n_jobsint, default=None
Die Anzahl der CPUs, die zur Berechnung der partiellen Abhängigkeiten verwendet werden. Die Berechnung wird für die durch den Parameter
featuresangegebenen Merkmale parallelisiert.Nonebedeutet 1, außer in einemjoblib.parallel_backendKontext.-1bedeutet die Verwendung aller Prozessoren. Siehe Glossar für weitere Details.- verboseint, default=0
Ausführliche Ausgabe während der PD-Berechnungen.
- line_kwdict, Standard=None
Dict mit Schlüsselwörtern, die an den Aufruf von
matplotlib.pyplot.plotübergeben werden. Für eindimensionale Partial-Dependence-Diagramme. Es kann verwendet werden, um gemeinsame Eigenschaften für sowohlice_lines_kwals auchpdp_line_kwzu definieren.- ice_lines_kwdict, Standard=None
Dictionary mit Schlüsselwörtern, die an den Aufruf von
matplotlib.pyplot.plotübergeben werden. Für ICE-Linien in eindimensionalen Partial-Dependence-Diagrammen. Die inice_lines_kwdefinierten Schlüssel-Wert-Paare haben Vorrang vorline_kw.- pd_line_kwdict, Standard=None
Dictionary mit Schlüsselwörtern, die an den Aufruf von
matplotlib.pyplot.plotübergeben werden. Für partielle Abhängigkeit in eindimensionalen Partial-Dependence-Diagrammen. Die inpd_line_kwdefinierten Schlüssel-Wert-Paare haben Vorrang vorline_kw.- contour_kwdict, Standard=None
Dict mit Schlüsselwörtern, die an den Aufruf von
matplotlib.pyplot.contourfübergeben werden. Für zweidimensionale Partial-Dependence-Diagramme.- axMatplotlib-Achsen oder Array von Matplotlib-Achsen, Standard=None
Wenn eine einzelne Achse übergeben wird, wird diese als Begrenzungsachse behandelt und ein Gitter von Partial-Dependence-Diagrammen wird innerhalb dieser Grenzen gezeichnet. Der Parameter
n_colssteuert die Anzahl der Spalten im Gitter.Wenn ein Array von Achsen übergeben wird, werden die Partial-Dependence-Diagramme direkt in diese Achsen gezeichnet.
Wenn
None, wird eine Figur und eine Begrenzungsachse erstellt und als einzelne Achse behandelt.
- kind{‘average’, ‘individual’, ‘both’}, Standard=‘average’
Ob die partielle Abhängigkeit gemittelt über alle Stichproben im Datensatz oder eine Linie pro Stichprobe oder beides gezeichnet werden soll.
kind='average'ergibt das traditionelle PD-Diagramm;kind='individual'ergibt das ICE-Diagramm.
Beachten Sie, dass die schnelle Option
method='recursion'nur fürkind='average'undsample_weights=Noneverfügbar ist. Das Berechnen individueller Abhängigkeiten und gewichteter Mittelwerte erfordert die Verwendung der langsameren Methodemethod='brute'.- centeredbool, Standard=False
Wenn
True, beginnen die ICE- und PD-Linien am Ursprung der y-Achse. Standardmäßig erfolgt keine Zentrierung.Hinzugefügt in Version 1.1.
- subsamplefloat, int oder None, Standard=1000
Stichproben für ICE-Kurven, wenn
kind„individual“ oder „both“ ist. Wennfloat, sollte er zwischen 0,0 und 1,0 liegen und den Anteil des Datensatzes darstellen, der zum Zeichnen von ICE-Kurven verwendet wird. Wennint, stellt er die absolute Anzahl der zu verwendenden Stichproben dar.Beachten Sie, dass der vollständige Datensatz immer noch zur Berechnung der gemittelten partiellen Abhängigkeit verwendet wird, wenn
kind='both'ist.- random_stateint, RandomState-Instanz oder None, default=None
Steuert die Zufälligkeit der ausgewählten Stichproben, wenn subsamples nicht
Noneist undkindentweder'both'oder'individual'ist. Siehe Glossar für Details.
- Gibt zurück:
- display
PartialDependenceDisplay
- display
Siehe auch
partial_dependenceBerechnet partielle Abhängigkeitswerte.
Beispiele
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import make_friedman1 >>> from sklearn.ensemble import GradientBoostingRegressor >>> from sklearn.inspection import PartialDependenceDisplay >>> X, y = make_friedman1() >>> clf = GradientBoostingRegressor(n_estimators=10).fit(X, y) >>> PartialDependenceDisplay.from_estimator(clf, X, [0, (0, 1)]) <...> >>> plt.show()

- plot(*, ax=None, n_cols=3, line_kw=None, ice_lines_kw=None, pd_line_kw=None, contour_kw=None, bar_kw=None, heatmap_kw=None, pdp_lim=None, centered=False)[Quelle]#
Zeichnet Partial Dependence Plots.
- Parameter:
- axMatplotlib-Achsen oder Array von Matplotlib-Achsen, Standard=None
- Wenn eine einzelne Achse übergeben wird, wird sie als umschließende Achse behandelt
und ein Gitter von Partial Dependence Plots wird innerhalb dieser Grenzen gezeichnet. Der Parameter
n_colssteuert die Anzahl der Spalten im Gitter.
- Wenn ein Array von Achsen übergeben wird, werden die Partial Dependence
Plots direkt in diese Achsen gezeichnet.
- Wenn
None, wird eine Figur und eine umschließende Achse erstellt und behandelt als der Fall einer einzelnen Achse.
- Wenn
- n_colsint, Standard=3
Die maximale Anzahl von Spalten im Gitter-Plot. Nur aktiv, wenn
axeine einzelne Achse ist oderNone.- line_kwdict, Standard=None
Dict mit Schlüsselwörtern, die an den
matplotlib.pyplot.plotAufruf übergeben werden. Für einwegige Partial Dependence Plots.- ice_lines_kwdict, Standard=None
Dictionary mit Schlüsselwörtern, die an den Aufruf von
matplotlib.pyplot.plotübergeben werden. Für ICE-Linien in eindimensionalen Partial-Dependence-Diagrammen. Die inice_lines_kwdefinierten Schlüssel-Wert-Paare haben Vorrang vorline_kw.Hinzugefügt in Version 1.0.
- pd_line_kwdict, Standard=None
Dictionary mit Schlüsselwörtern, die an den Aufruf von
matplotlib.pyplot.plotübergeben werden. Für partielle Abhängigkeit in eindimensionalen Partial-Dependence-Diagrammen. Die inpd_line_kwdefinierten Schlüssel-Wert-Paare haben Vorrang vorline_kw.Hinzugefügt in Version 1.0.
- contour_kwdict, Standard=None
Dict mit Schlüsselwörtern, die an den
matplotlib.pyplot.contourfAufruf für zweizwegige Partial Dependence Plots übergeben werden.- bar_kwdict, Standard=None
Dict mit Schlüsselwörtern, die an den
matplotlib.pyplot.barAufruf für einwegige kategorische Partial Dependence Plots übergeben werden.Hinzugefügt in Version 1.2.
- heatmap_kwdict, Standard=None
Dict mit Schlüsselwörtern, die an den
matplotlib.pyplot.imshowAufruf für zweizwegige kategorische Partial Dependence Plots übergeben werden.Hinzugefügt in Version 1.2.
- pdp_limdict, Standard=None
Globale Minima und Maxima der durchschnittlichen Vorhersagen, so dass alle Plots die gleiche Skala und y-Grenzen haben.
pdp_lim[1]ist das globale Minimum und Maximum für einzelne Partial Dependence Kurven.pdp_lim[2]ist das globale Minimum und Maximum für zweizwegige Partial Dependence Kurven. WennNone(Standard), wird die Grenze aus dem globalen Minimum und Maximum aller Vorhersagen abgeleitet.Hinzugefügt in Version 1.1.
- centeredbool, Standard=False
Wenn
True, beginnen die ICE- und PD-Linien am Ursprung der y-Achse. Standardmäßig erfolgt keine Zentrierung.Hinzugefügt in Version 1.1.
- Gibt zurück:
- display
PartialDependenceDisplay Gibt ein
PartialDependenceDisplayObjekt zurück, das die Partial Dependence Plots enthält.
- display
Galeriebeispiele#



Partial Dependence und Individual Conditional Expectation Plots