SelfTrainingClassifier#
- class sklearn.semi_supervised.SelfTrainingClassifier(estimator=None, threshold=0.75, criterion='threshold', k_best=10, max_iter=10, verbose=False)[Quelle]#
Self-training Klassifikator.
Dieser Meta-Estimator ermöglicht es einem gegebenen überwachten Klassifikator, als semi-überwacht zu fungieren, indem er von unbeschrifteten Daten lernt. Dies geschieht durch iterative Vorhersage von Pseudolabels für die unbeschrifteten Daten und deren Hinzufügung zum Trainingsdatensatz.
Der Klassifikator wird so lange iterieren, bis entweder `max_iter` erreicht ist oder in der vorherigen Iteration keine Pseudolabels zum Trainingsdatensatz hinzugefügt wurden.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- estimatorEstimator-Objekt
Ein Estimator-Objekt, das `fit` und `predict_proba` implementiert. Der Aufruf der `fit`-Methode passt eine Kopie des übergebenen Estimators an, die im Attribut `estimator_` gespeichert wird.
Hinzugefügt in Version 1.6: `estimator` wurde hinzugefügt, um `base_estimator` zu ersetzen.
- thresholdfloat, default=0.75
Die Entscheidungsschwelle für die Verwendung mit `criterion='threshold'`. Sollte im Bereich [0, 1) liegen. Bei Verwendung des Kriteriums `'threshold'` sollte ein gut kalibrierter Klassifikator verwendet werden.
- criterion{‘threshold’, ‘k_best’}, default=’threshold’
Das Auswahlkriterium, das verwendet wird, um auszuwählen, welche Labels zum Trainingsdatensatz hinzugefügt werden sollen. Wenn `'threshold'`, werden Pseudolabels mit Vorhersagewahrscheinlichkeiten über `threshold` zum Datensatz hinzugefügt. Wenn `'k_best'`, werden die `k_best` Pseudolabels mit den höchsten Vorhersagewahrscheinlichkeiten zum Datensatz hinzugefügt. Bei Verwendung des Kriteriums `'threshold'` sollte ein gut kalibrierter Klassifikator verwendet werden.
- k_bestint, default=10
Die Anzahl der zu jeder Iteration hinzuzufügenden Stichproben. Wird nur verwendet, wenn `criterion='k_best'`.
- max_iterint oder None, default=10
Maximale Anzahl zulässiger Iterationen. Sollte größer oder gleich 0 sein. Wenn es `None` ist, wird der Klassifikator weiterhin Labels vorhersagen, bis keine neuen Pseudolabels hinzugefügt werden oder alle unbeschrifteten Stichproben beschriftet wurden.
- verbosebool, default=False
Aktiviert die ausführliche Ausgabe.
- Attribute:
- estimator_estimator object
Der angepasste Estimator.
- classes_ndarray oder list von ndarray der Form (n_classes,)
Klassenlabels für jede Ausgabe. (Übernommen vom trainierten `estimator_`).
- transduction_ndarray der Form (n_samples,)
Die Labels, die für die endgültige Anpassung des Klassifikators verwendet wurden, einschließlich der während der Anpassung hinzugefügten Pseudolabels.
- labeled_iter_ndarray der Form (n_samples,)
Die Iteration, in der jede Stichprobe beschriftet wurde. Wenn eine Stichprobe die Iteration 0 hat, wurde die Stichprobe bereits im ursprünglichen Datensatz beschriftet. Wenn eine Stichprobe die Iteration -1 hat, wurde die Stichprobe in keiner Iteration beschriftet.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
- n_iter_int
Die Anzahl der Runden des Selbsttrainings, d.h. die Anzahl der Male, die der Basis-Estimator auf neu beschrifteten Varianten des Trainingsdatensatzes angepasst wird.
- termination_condition_{‘max_iter’, ‘no_change’, ‘all_labeled’}
Der Grund, warum die Anpassung gestoppt wurde.
'max_iter': `n_iter_` erreichte `max_iter`.'no_change': Es wurden keine neuen Labels vorhergesagt.'all_labeled': Alle unbeschrifteten Stichproben wurden vor Erreichen von `max_iter` beschriftet.
Siehe auch
LabelPropagationLabel-Propagation-Klassifikator.
LabelSpreadingLabel-Spreading-Modell für semi-überwachtes Lernen.
Referenzen
Beispiele
>>> import numpy as np >>> from sklearn import datasets >>> from sklearn.semi_supervised import SelfTrainingClassifier >>> from sklearn.svm import SVC >>> rng = np.random.RandomState(42) >>> iris = datasets.load_iris() >>> random_unlabeled_points = rng.rand(iris.target.shape[0]) < 0.3 >>> iris.target[random_unlabeled_points] = -1 >>> svc = SVC(probability=True, gamma="auto") >>> self_training_model = SelfTrainingClassifier(svc) >>> self_training_model.fit(iris.data, iris.target) SelfTrainingClassifier(...)
- decision_function(X, **params)[Quelle]#
Ruft die Entscheidungsfunktion des `estimator` auf.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Array, das die Daten darstellt.
- **paramsDict von str -> Objekt
Parameter, die an die `decision_function`-Methode des zugrunde liegenden Estimators übergeben werden.
Hinzugefügt in Version 1.6: Nur verfügbar, wenn
enable_metadata_routing=True, was durch Setzen vonsklearn.set_config(enable_metadata_routing=True)erfolgen kann. Siehe Metadaten-Routing Benutzerhandbuch für weitere Details.
- Gibt zurück:
- yndarray der Form (n_samples, n_features)
Ergebnis der Entscheidungsfunktion des `estimator`.
- fit(X, y, **params)[Quelle]#
Passt den Selbsttrainings-Klassifikator mithilfe von `X` und `y` als Trainingsdaten an.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Array, das die Daten darstellt.
- y{array-like, sparse matrix} der Form (n_samples,)
Array, das die Labels darstellt. Unbeschriftete Stichproben sollten das Label -1 haben.
- **paramsdict
Parameter, die an die zugrunde liegenden Estimator übergeben werden.
Hinzugefügt in Version 1.6: Nur verfügbar, wenn
enable_metadata_routing=True, was durch Setzen vonsklearn.set_config(enable_metadata_routing=True)erfolgen kann. Siehe Metadaten-Routing Benutzerhandbuch für weitere Details.
- Gibt zurück:
- selfobject
Angepasster Schätzer.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
Hinzugefügt in Version 1.6.
- Gibt zurück:
- routingMetadataRouter
Ein
MetadataRouter, der die Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X, **params)[Quelle]#
Sagt die Klassen von `X` voraus.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Array, das die Daten darstellt.
- **paramsDict von str -> Objekt
Parameter, die an die `predict`-Methode des zugrunde liegenden Estimators übergeben werden.
Hinzugefügt in Version 1.6: Nur verfügbar, wenn
enable_metadata_routing=True, was durch Setzen vonsklearn.set_config(enable_metadata_routing=True)erfolgen kann. Siehe Metadaten-Routing Benutzerhandbuch für weitere Details.
- Gibt zurück:
- yndarray der Form (n_samples,)
Array mit vorhergesagten Labels.
- predict_log_proba(X, **params)[Quelle]#
Sagt die Log-Wahrscheinlichkeiten für jedes mögliche Ergebnis voraus.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Array, das die Daten darstellt.
- **paramsDict von str -> Objekt
Parameter, die an die `predict_log_proba`-Methode des zugrunde liegenden Estimators übergeben werden.
Hinzugefügt in Version 1.6: Nur verfügbar, wenn
enable_metadata_routing=True, was durch Setzen vonsklearn.set_config(enable_metadata_routing=True)erfolgen kann. Siehe Metadaten-Routing Benutzerhandbuch für weitere Details.
- Gibt zurück:
- yndarray der Form (n_samples, n_features)
Array mit Log-Vorhersagewahrscheinlichkeiten.
- predict_proba(X, **params)[Quelle]#
Vorhersage der Wahrscheinlichkeit für jedes mögliche Ergebnis.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Array, das die Daten darstellt.
- **paramsDict von str -> Objekt
Parameter, die an die `predict_proba`-Methode des zugrunde liegenden Estimators übergeben werden.
Hinzugefügt in Version 1.6: Nur verfügbar, wenn
enable_metadata_routing=True, was durch Setzen vonsklearn.set_config(enable_metadata_routing=True)erfolgen kann. Siehe Metadaten-Routing Benutzerhandbuch für weitere Details.
- Gibt zurück:
- yndarray der Form (n_samples, n_features)
Array mit Vorhersagewahrscheinlichkeiten.
- score(X, y, **params)[Quelle]#
Ruft die Score-Methode des `estimator` auf.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Array, das die Daten darstellt.
- yarray-like von Form (n_samples,)
Array, das die Labels darstellt.
- **paramsDict von str -> Objekt
Parameter, die an die `score`-Methode des zugrunde liegenden Estimators übergeben werden.
Hinzugefügt in Version 1.6: Nur verfügbar, wenn
enable_metadata_routing=True, was durch Setzen vonsklearn.set_config(enable_metadata_routing=True)erfolgen kann. Siehe Metadaten-Routing Benutzerhandbuch für weitere Details.
- Gibt zurück:
- scorefloat
Ergebnis des Aufrufs von score auf dem `estimator`.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
Galeriebeispiele#

Auswirkung der Änderung des Schwellenwerts für Self-Training
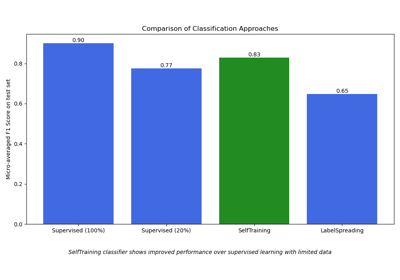
Semi-überwachte Klassifikation auf einem Textdatensatz

Entscheidungsgrenze semi-überwachter Klassifikatoren vs. SVM auf dem Iris-Datensatz