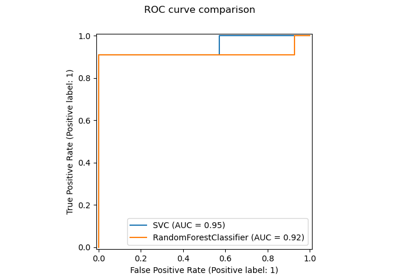
roc_auc_score#
- sklearn.metrics.roc_auc_score(y_true, y_score, *, average='macro', sample_weight=None, max_fpr=None, multi_class='raise', labels=None)[source]#
Berechne die Fläche unter der Receiver Operating Characteristic Curve (ROC AUC) aus den Vorhersagescores.
Hinweis: Diese Implementierung kann mit binärer, multiklassen und multilabel Klassifizierung verwendet werden, jedoch mit einigen Einschränkungen (siehe Parameter).
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- y_truearray-like von Form (n_samples,) oder (n_samples, n_classes)
Wahre Labels oder binäre Label-Indikatoren. Die binären und multiklassen Fälle erwarten Labels mit der Form (n_samples,), während der multilabel Fall binäre Label-Indikatoren mit der Form (n_samples, n_classes) erwartet.
- y_scorearray-ähnlich der Form (n_samples,) oder (n_samples, n_classes)
Zielwerte (scores).
Im binären Fall entspricht dies einem Array der Form
(n_samples,). Sowohl Wahrscheinlichkeitsschätzungen als auch nicht-thresholded Entscheidungswerte können bereitgestellt werden. Die Wahrscheinlichkeitsschätzungen entsprechen der Wahrscheinlichkeit der Klasse mit dem größeren Label, d.h.estimator.classes_[1]und somitestimator.predict_proba(X, y)[:, 1]. Die Entscheidungswerte entsprechen der Ausgabe vonestimator.decision_function(X, y). Siehe weitere Informationen im Benutzerhandbuch;Im multiklassen Fall entspricht dies einem Array der Form
(n_samples, n_classes)von Wahrscheinlichkeitsschätzungen, die von der Methodepredict_probabereitgestellt werden. Die Wahrscheinlichkeitsschätzungen müssen sich über die möglichen Klassen zu 1 summieren. Zusätzlich muss die Reihenfolge der Klassen-Scores der Reihenfolge vonlabelsentsprechen, falls diese angegeben sind, andernfalls der numerischen oder lexikografischen Reihenfolge der Labels iny_true. Siehe weitere Informationen im Benutzerhandbuch;Im multilabel Fall entspricht dies einem Array der Form
(n_samples, n_classes). Wahrscheinlichkeitsschätzungen werden von der Methodepredict_probaund nicht-thresholded Entscheidungswerte von der Methodedecision_functionbereitgestellt. Die Wahrscheinlichkeitsschätzungen entsprechen der Wahrscheinlichkeit der Klasse mit dem größeren Label für jede Ausgabe des Klassifikators. Siehe weitere Informationen im Benutzerhandbuch.
- average{‘micro’, ‘macro’, ‘samples’, ‘weighted’} oder None, Standard=‘macro’
Wenn
None, werden die Scores für jede Klasse zurückgegeben. Andernfalls bestimmt dies die Art der Mittelwertbildung (Averaging), die auf den Daten durchgeführt wird. Hinweis: Multiklassen-ROC AUC unterstützt derzeit nur die Mittelwerte ‘macro’ und ‘weighted’. Für Multiklassen-Ziele istaverage=Nonenur fürmulti_class='ovr'implementiert, undaverage='micro'ist nur fürmulti_class='ovr'implementiert.'micro':Metriken global berechnen, indem jedes Element der Label-Indikatormatrix als ein Label betrachtet wird.
'macro':Metriken für jede Bezeichnung berechnen und deren ungewichtetes Mittel finden. Dies berücksichtigt keine unausgeglichenen Bezeichnungen.
'weighted':Metriken für jedes Label berechnen und deren Mittelwert finden, gewichtet nach der Unterstützung (Support) (der Anzahl der tatsächlichen Instanzen für jedes Label).
'samples':Metriken für jede Instanz berechnen und deren Mittelwert finden.
Wird ignoriert, wenn
y_truebinär ist.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- max_fprfloat > 0 und <= 1, Standard=None
Wenn nicht
None, wird die standardisierte partielle AUC [2] im Bereich [0, max_fpr] zurückgegeben. Für den multiklassen Fall solltemax_fprentweder gleichNoneoder1.0sein, da die partielle AUC ROC-Berechnung derzeit nicht für multiklassen unterstützt wird.- multi_class{‘raise’, ‘ovr’, ‘ovo’}, Standard=‘raise’
Wird nur für multiklassen Ziele verwendet. Bestimmt den zu verwendenden Konfigurationstyp. Der Standardwert löst einen Fehler aus, daher müssen entweder
'ovr'oder'ovo'explizit übergeben werden.'ovr':Steht für One-vs-rest. Berechnet die AUC jeder Klasse gegen den Rest [3] [4]. Dies behandelt den multiklassen Fall auf die gleiche Weise wie den multilabel Fall. Ist empfindlich gegenüber Klassenungleichgewichten, auch wenn
average == 'macro', da Klassenungleichgewichte die Zusammensetzung jeder der ‘rest’-Gruppierungen beeinflussen.'ovo':Steht für One-vs-one. Berechnet den Durchschnitt der AUC aller möglichen paarweisen Kombinationen von Klassen [5]. Ist unempfindlich gegenüber Klassenungleichgewichten, wenn
average == 'macro'.
- labelsarray-like der Form (n_classes,), Standard=None
Wird nur für multiklassen Ziele verwendet. Liste von Labels, die die Klassen in
y_scoreindizieren. WennNone, wird die numerische oder lexikografische Reihenfolge der Labels iny_trueverwendet.
- Gibt zurück:
- aucfloat
Fläche unter der Kurve (Area Under the Curve) Score.
Siehe auch
average_precision_scoreFläche unter der Precision-Recall-Kurve.
roc_curveBerechnen Sie die Receiver Operating Characteristic (ROC)-Kurve.
RocCurveDisplay.from_estimatorZeichnen Sie die Receiver Operating Characteristic (ROC)-Kurve anhand eines Estimators und einiger Daten.
RocCurveDisplay.from_predictionsZeichnen Sie die Receiver Operating Characteristic (ROC)-Kurve anhand der wahren und vorhergesagten Werte.
Anmerkungen
Der Gini-Koeffizient ist ein zusammenfassendes Maß für die Ranking-Fähigkeit von binären Klassifikatoren. Er wird anhand der Fläche unter der ROC-Kurve wie folgt ausgedrückt:
G = 2 * AUC - 1
Wobei G der Gini-Koeffizient und AUC der ROC-AUC-Score ist. Diese Normalisierung stellt sicher, dass zufälliges Raten im Erwartungswert einen Score von 0 ergibt und nach oben durch 1 begrenzt ist.
Referenzen
[3]Provost, F., Domingos, P. (2000). Well-trained PETs: Improving probability estimation trees (Section 6.2), CeDER Working Paper #IS-00-04, Stern School of Business, New York University.
[4]Fawcett, T. (2006). An introduction to ROC analysis. Pattern Recognition Letters, 27(8), 861-874.
[5]Beispiele
Binärer Fall
>>> from sklearn.datasets import load_breast_cancer >>> from sklearn.linear_model import LogisticRegression >>> from sklearn.metrics import roc_auc_score >>> X, y = load_breast_cancer(return_X_y=True) >>> clf = LogisticRegression(solver="newton-cholesky", random_state=0).fit(X, y) >>> roc_auc_score(y, clf.predict_proba(X)[:, 1]) 0.99 >>> roc_auc_score(y, clf.decision_function(X)) 0.99
Multiklassenfall
>>> from sklearn.datasets import load_iris >>> X, y = load_iris(return_X_y=True) >>> clf = LogisticRegression(solver="newton-cholesky").fit(X, y) >>> roc_auc_score(y, clf.predict_proba(X), multi_class='ovr') 0.99
Multilabel-Fall
>>> import numpy as np >>> from sklearn.datasets import make_multilabel_classification >>> from sklearn.multioutput import MultiOutputClassifier >>> X, y = make_multilabel_classification(random_state=0) >>> clf = MultiOutputClassifier(clf).fit(X, y) >>> # get a list of n_output containing probability arrays of shape >>> # (n_samples, n_classes) >>> y_score = clf.predict_proba(X) >>> # extract the positive columns for each output >>> y_score = np.transpose([score[:, 1] for score in y_score]) >>> roc_auc_score(y, y_score, average=None) array([0.828, 0.852, 0.94, 0.869, 0.95]) >>> from sklearn.linear_model import RidgeClassifierCV >>> clf = RidgeClassifierCV().fit(X, y) >>> roc_auc_score(y, clf.decision_function(X), average=None) array([0.82, 0.847, 0.93, 0.872, 0.944])
Galeriebeispiele#

Leistung eines Klassifikators mit Konfusionsmatrix bewerten

Statistischer Vergleich von Modellen mittels Gitter-Suche

Multiklassen-Receiver Operating Characteristic (ROC)