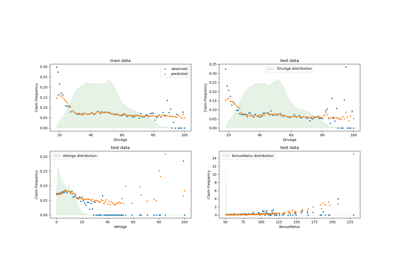
PoissonRegressor#
- class sklearn.linear_model.PoissonRegressor(*, alpha=1.0, fit_intercept=True, solver='lbfgs', max_iter=100, tol=0.0001, warm_start=False, verbose=0)[Quelle]#
Generalisiertes lineares Modell mit einer Poisson-Verteilung.
Dieser Regressor verwendet die 'log'-Linkfunktion.
Lesen Sie mehr im Benutzerhandbuch.
Hinzugefügt in Version 0.23.
- Parameter:
- alphafloat, Standard=1
Konstante, die den L2-Strafterm multipliziert und die Stärke der Regularisierung bestimmt.
alpha = 0entspricht unbestraften GLMs. In diesem Fall muss die DesignmatrixXeine volle Spaltenrangigkeit haben (keine Kollinearitäten). Werte vonalphamüssen im Bereich[0.0, inf)liegen.- fit_interceptbool, Standardwert=True
Gibt an, ob eine Konstante (auch Bias oder Achsenabschnitt genannt) zum linearen Prädiktor hinzugefügt werden soll (
X @ coef + intercept).- solver{‘lbfgs’, ‘newton-cholesky’}, Standard=’lbfgs’
Algorithmus, der im Optimierungsproblem verwendet werden soll
- ‘lbfgs’
Ruft den L-BFGS-B-Optimierer von SciPy auf.
- ‘newton-cholesky’
Verwendet Newton-Raphson-Schritte (in beliebiger Präzisionsarithmetik äquivalent zu iterativer reweighted kleinster Quadrate) mit einem internen Cholesky-basierten Löser. Dieser Löser ist eine gute Wahl für
n_samples>>n_features, insbesondere mit One-Hot-kodierten kategorialen Merkmalen mit seltenen Kategorien. Beachten Sie, dass der Speicherbedarf dieses Lösers eine quadratische Abhängigkeit vonn_featureshat, da er die Hesse-Matrix explizit berechnet.Hinzugefügt in Version 1.2.
- max_iterint, default=100
Die maximale Anzahl von Iterationen für den Löser. Werte müssen im Bereich
[1, inf)liegen.- tolfloat, Standard=1e-4
Abbruchkriterium. Für den lbfgs-Löser wird die Iteration gestoppt, wenn
max{|g_j|, j = 1, ..., d} <= tolist, wobeig_jdie j-te Komponente des Gradienten (Ableitung) der Zielfunktion ist. Werte müssen im Bereich(0.0, inf)liegen.- warm_startbool, Standard=False
Wenn auf
Truegesetzt, wird die Lösung des vorherigen Aufrufs vonfitals Initialisierung fürcoef_undintercept_wiederverwendet.- verboseint, default=0
Für den lbfgs-Löser setzen Sie verbose auf eine beliebige positive Zahl für die Ausführlichkeit. Werte müssen im Bereich
[0, inf)liegen.
- Attribute:
- coef_array der Form (n_features,)
Geschätzte Koeffizienten für den linearen Prädiktor (
X @ coef_ + intercept_) im GLM.- intercept_float
Achsenabschnitt (auch Bias genannt), der zum linearen Prädiktor hinzugefügt wird.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
- n_iter_int
Tatsächliche Anzahl der im Löser verwendeten Iterationen.
Siehe auch
TweedieRegressorGeneralisiertes lineares Modell mit einer Tweedie-Verteilung.
Beispiele
>>> from sklearn import linear_model >>> clf = linear_model.PoissonRegressor() >>> X = [[1, 2], [2, 3], [3, 4], [4, 3]] >>> y = [12, 17, 22, 21] >>> clf.fit(X, y) PoissonRegressor() >>> clf.score(X, y) np.float64(0.990) >>> clf.coef_ array([0.121, 0.158]) >>> clf.intercept_ np.float64(2.088) >>> clf.predict([[1, 1], [3, 4]]) array([10.676, 21.875])
- fit(X, y, sample_weight=None)[Quelle]#
Anpassen eines verallgemeinerten linearen Modells.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Trainingsdaten.
- yarray-like von Form (n_samples,)
Zielwerte.
- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- selfobject
Angepasstes Modell.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X)[Quelle]#
Vorhersage mit GLM mit der Merkmalsmatrix X.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Stichproben.
- Gibt zurück:
- y_predArray der Form (n_samples,)
Gibt vorhergesagte Werte zurück.
- score(X, y, sample_weight=None)[Quelle]#
Berechnet D^2, den Prozentsatz der erklärten Devianz.
D^2 ist eine Verallgemeinerung des Bestimmtheitsmaßes R^2. R^2 verwendet den quadrierten Fehler und D^2 verwendet die Devianz dieses GLM, siehe das Benutzerhandbuch.
D^2 ist definiert als \(D^2 = 1-\frac{D(y_{true},y_{pred})}{D_{null}}\), \(D_{null}\) ist die Null-Devianz, d.h. die Devianz eines Modells nur mit Achsenabschnitt, was \(y_{pred} = \bar{y}\) entspricht. Der Mittelwert \(\bar{y}\) wird mit sample_weight gemittelt. Der bestmögliche Score ist 1.0 und er kann negativ sein (da das Modell beliebig schlechter sein kann).
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Teststichproben.
- yarray-like von Form (n_samples,)
Wahre Werte des Ziels.
- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
D^2 von self.predict(X) in Bezug auf y.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') PoissonRegressor[Quelle]#
Konfiguriert, ob Metadaten für die
fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anfitübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anfit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinfit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') PoissonRegressor[Quelle]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
Galeriebeispiele#
Poisson-Regression und nicht-normale Verlustfunktion