Normalizer#
- class sklearn.preprocessing.Normalizer(norm='l2', *, copy=True)[Quelle]#
Normalisiert Stichproben einzeln auf Norm 1.
Jede Stichprobe (d.h. jede Zeile der Datenmatrix) mit mindestens einer Nicht-Null-Komponente wird unabhängig von anderen Stichproben so skaliert, dass ihre Norm (l1, l2 oder inf) gleich eins ist.
Dieser Transformer kann sowohl mit dichten NumPy-Arrays als auch mit scipy.sparse-Matrizen arbeiten (verwenden Sie das CSR-Format, wenn Sie die Belastung durch eine Kopie/Konvertierung vermeiden möchten).
Die Skalierung von Eingaben auf Einheitsnormen ist beispielsweise eine gängige Operation für die Textklassifizierung oder das Clustering. Zum Beispiel ist das Skalarprodukt zweier l2-normalisierter TF-IDF-Vektoren die Kosinus-Ähnlichkeit der Vektoren und die grundlegende Ähnlichkeitsmetrik für das Vektorraummodell, das häufig von der Community der Informationsrückgewinnung verwendet wird.
Eine Beispielvisualisierung finden Sie unter Vergleich von Normalizer mit anderen Skalierern.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- norm{‘l1’, ‘l2’, ‘max’}, Standard=‘l2’
Die zu verwendende Norm zur Normalisierung jeder Nicht-Null-Stichprobe. Wenn norm=’max’ verwendet wird, werden die Werte mit dem Maximum der Absolutwerte skaliert.
- copybool, Standard=True
Auf False setzen, um die zeilenweise Normalisierung inplace durchzuführen und eine Kopie zu vermeiden (wenn die Eingabe bereits ein NumPy-Array oder eine scipy.sparse CSR-Matrix ist).
- Attribute:
Siehe auch
normalizeÄquivalente Funktion ohne die Estimator-API.
Anmerkungen
Dieser Estimator ist zustandslos und muss nicht angepasst werden. Wir empfehlen jedoch,
fit_transformanstelle vontransformaufzurufen, da die Parameterprüfung nur infitdurchgeführt wird.Beispiele
>>> from sklearn.preprocessing import Normalizer >>> X = [[4, 1, 2, 2], ... [1, 3, 9, 3], ... [5, 7, 5, 1]] >>> transformer = Normalizer().fit(X) # fit does nothing. >>> transformer Normalizer() >>> transformer.transform(X) array([[0.8, 0.2, 0.4, 0.4], [0.1, 0.3, 0.9, 0.3], [0.5, 0.7, 0.5, 0.1]])
- fit(X, y=None)[Quelle]#
Validiert nur die Parameter des Estimators.
Diese Methode erlaubt: (i) die Validierung der Parameter des Estimators und (ii) Konsistenz mit der scikit-learn Transformer API.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die Daten zur Schätzung der Normalisierungsparameter.
- yIgnoriert
Nicht verwendet, hier zur API-Konsistenz durch Konvention vorhanden.
- Gibt zurück:
- selfobject
Gefitteter Transformer.
- fit_transform(X, y=None, **fit_params)[Quelle]#
An Daten anpassen, dann transformieren.
Passt den Transformer an
Xundymit optionalen Parameternfit_paramsan und gibt eine transformierte Version vonXzurück.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Eingabestichproben.
- yarray-like der Form (n_samples,) oder (n_samples, n_outputs), Standardwert=None
Zielwerte (None für unüberwachte Transformationen).
- **fit_paramsdict
Zusätzliche Fit-Parameter. Nur übergeben, wenn der Estimator zusätzliche Parameter in seiner
fit-Methode akzeptiert.
- Gibt zurück:
- X_newndarray array der Form (n_samples, n_features_new)
Transformiertes Array.
- get_feature_names_out(input_features=None)[Quelle]#
Holt die Ausgabemerkmale für die Transformation.
- Parameter:
- input_featuresarray-like von str oder None, default=None
Eingabemerkmale.
Wenn
input_featuresNoneist, werdenfeature_names_in_als Merkmalnamen verwendet. Wennfeature_names_in_nicht definiert ist, werden die folgenden Eingabemerkmalsnamen generiert:["x0", "x1", ..., "x(n_features_in_ - 1)"].Wenn
input_featuresein Array-ähnliches Objekt ist, mussinput_featuresmitfeature_names_in_übereinstimmen, wennfeature_names_in_definiert ist.
- Gibt zurück:
- feature_names_outndarray von str-Objekten
Gleich wie Eingabemerkmale.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- set_output(*, transform=None)[Quelle]#
Ausgabecontainer festlegen.
Siehe Einführung in die set_output API für ein Beispiel zur Verwendung der API.
- Parameter:
- transform{“default”, “pandas”, “polars”}, default=None
Konfiguriert die Ausgabe von
transformundfit_transform."default": Standardausgabeformat eines Transformers"pandas": DataFrame-Ausgabe"polars": Polars-AusgabeNone: Die Transformationskonfiguration bleibt unverändert
Hinzugefügt in Version 1.4: Die Option
"polars"wurde hinzugefügt.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_transform_request(*, copy: bool | None | str = '$UNCHANGED$') Normalizer[Quelle]#
Konfiguriert, ob Metadaten für die
transform-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, antransformweitergegeben. Die Anforderung wird ignoriert, wenn keine Metadaten bereitgestellt werden.False: Metadaten werden nicht angefordert und die Meta-Schätzung übergibt sie nicht antransform.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- copystr, True, False oder None, Standard=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
copyintransform.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- transform(X, copy=None)[Quelle]#
Skaliert jede Nicht-Null-Zeile von X auf die Einheitsnorm.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Die zu normalisierenden Daten, Zeile für Zeile. scipy.sparse-Matrizen sollten im CSR-Format vorliegen, um eine unnötige Kopie zu vermeiden.
- copybool, Standard=None
Kopiert die Eingabe X oder nicht.
- Gibt zurück:
- X_tr{ndarray, sparse matrix} mit der Form (n_samples, n_features)
Transformiertes Array.
Galeriebeispiele#

Skalierbares Lernen mit Polynom-Kernel-Approximation
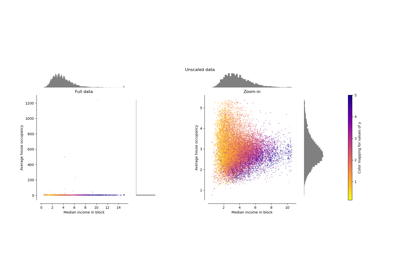
Vergleich der Auswirkungen verschiedener Skalierer auf Daten mit Ausreißern
