fetch_20newsgroups#
- sklearn.datasets.fetch_20newsgroups(*, data_home=None, subset='train', categories=None, shuffle=True, random_state=42, remove=(), download_if_missing=True, return_X_y=False, n_retries=3, delay=1.0)[Quelle]#
Lädt die Dateinamen und Daten aus dem 20 newsgroups Datensatz (Klassifikation).
Bei Bedarf herunterladen.
Klassen
20
Gesamtanzahl Samples
18846
Dimensionalität
1
Merkmale
text
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- data_homestr oder path-like, Standard=None
Geben Sie einen Download- und Cache-Ordner für die Datensätze an. Wenn None, werden alle scikit-learn-Daten in Unterordnern von „~/scikit_learn_data“ gespeichert.
- subset{‘train’, ‘test’, ‘all’}, Standard=’train’
Wählen Sie den zu ladenden Datensatz aus: „train“ für das Trainingsset, „test“ für das Testset, „all“ für beide mit gemischter Reihenfolge.
- categoriesarray-like, dtype=str, Standard=None
Wenn None (Standard), werden alle Kategorien geladen. Wenn nicht None, Liste der zu ladenden Kategorienamen (andere Kategorien werden ignoriert).
- shufflebool, Standard=True
Ob die Daten gemischt werden sollen oder nicht: Kann wichtig für Modelle sein, die die Annahme treffen, dass die Samples unabhängig und identisch verteilt (i.i.d.) sind, wie z. B. stochastisches Gradientenverfahren.
- random_stateint, RandomState-Instanz oder None, Standard=42
Bestimmt die Zufallszahlengenerierung für das Mischen der Datensätze. Übergeben Sie einen int für reproduzierbare Ergebnisse über mehrere Funktionsaufrufe hinweg. Siehe Glossar.
- removetuple, Standard=()
Kann eine beliebige Teilmenge von („headers“, „footers“, „quotes“) enthalten. Jede dieser Arten von Text wird erkannt und aus den Newsgroup-Posts entfernt, um zu verhindern, dass Klassifikatoren auf Metadaten überanpassen.
„headers“ entfernt Newsgroup-Header, „footers“ entfernt Blöcke am Ende von Posts, die wie Signaturen aussehen, und „quotes“ entfernt Zeilen, die anscheinend einen anderen Post zitieren.
„headers“ folgt einem exakten Standard; die anderen Filter sind nicht immer korrekt.
- download_if_missingbool, Standard=True
Wenn False, wird eine OSError ausgelöst, wenn die Daten nicht lokal verfügbar sind, anstatt zu versuchen, die Daten von der Quell-Website herunterzuladen.
- return_X_ybool, Standard=False
Wenn True, wird
(data.data, data.target)anstelle eines Bunch-Objekts zurückgegeben.Hinzugefügt in Version 0.22.
- n_retriesint, Standard=3
Anzahl der Wiederholungsversuche bei HTTP-Fehlern.
Hinzugefügt in Version 1.5.
- delayfloat, Standard=1.0
Anzahl der Sekunden zwischen den Wiederholungsversuchen.
Hinzugefügt in Version 1.5.
- Gibt zurück:
- bunch
Bunch Dictionary-ähnliches Objekt mit den folgenden Attributen.
- datalist der Form (n_samples,)
Die zu lernende Datenliste.
- target: ndarray der Form (n_samples,)
Die Ziel-Labels.
- filenames: list der Form (n_samples,)
Der Pfad zum Speicherort der Daten.
- DESCR: str
Die vollständige Beschreibung des Datensatzes.
- target_names: list der Form (n_classes,)
Die Namen der Zielklassen.
- (data, target)tuple, wenn
return_X_y=True Ein Tupel aus zwei ndarrays. Das erste enthält ein 2D-Array der Form (n_samples, n_classes), wobei jede Zeile ein Sample darstellt und jede Spalte die Merkmale repräsentiert. Das zweite Array der Form (n_samples,) enthält die Ziel-Samples.
Hinzugefügt in Version 0.22.
- bunch
Beispiele
>>> from sklearn.datasets import fetch_20newsgroups >>> cats = ['alt.atheism', 'sci.space'] >>> newsgroups_train = fetch_20newsgroups(subset='train', categories=cats) >>> list(newsgroups_train.target_names) ['alt.atheism', 'sci.space'] >>> newsgroups_train.filenames.shape (1073,) >>> newsgroups_train.target.shape (1073,) >>> newsgroups_train.target[:10] array([0, 1, 1, 1, 0, 1, 1, 0, 0, 0])
Galeriebeispiele#

Themenextraktion mit Non-negative Matrix Factorization und Latent Dirichlet Allocation

Biclustering von Dokumenten mit dem Spectral Co-Clustering Algorithmus

Beispiel-Pipeline für Textmerkmal-Extraktion und -Bewertung
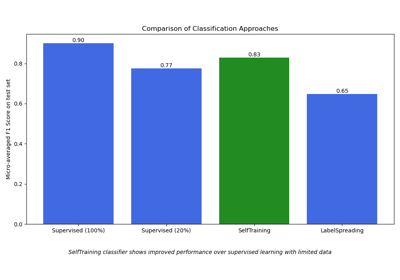
Semi-überwachte Klassifikation auf einem Textdatensatz

Klassifikation von Textdokumenten mit spärlichen Merkmalen

