completeness_score#
- sklearn.metrics.completeness_score(labels_true, labels_pred)[Quelle]#
Berechne die Vollständigkeitsmetrik einer Cluster-Beschriftung gegeben eine Grundwahrheit.
Ein Clustering-Ergebnis erfüllt Vollständigkeit, wenn alle Datenpunkte, die zu einer bestimmten Klasse gehören, Elemente desselben Clusters sind.
Diese Metrik ist unabhängig von den absoluten Werten der Labels: eine Permutation der Klassen- oder Cluster-Labelwerte ändert den Score-Wert in keiner Weise.
Diese Metrik ist nicht symmetrisch: Das Vertauschen von
label_truemitlabel_predgibt diehomogeneity_scorezurück, die im Allgemeinen unterschiedlich sein wird.Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- labels_truearray-like von Form (n_samples,)
Wahre Klassenlabels als Referenz.
- labels_predarray-like von Form (n_samples,)
Zu bewertende Clusterlabels.
- Gibt zurück:
- completenessfloat
Score zwischen 0.0 und 1.0. 1.0 steht für eine perfekt vollständige Kennzeichnung.
Siehe auch
homogeneity_scoreHomogenitätsmetrik der Cluster-Kennzeichnung.
v_measure_scoreV-Maß (NMI mit arithmetischem Mittelwert-Option).
Referenzen
Beispiele
Perfekte Kennzeichnungen sind vollständig
>>> from sklearn.metrics.cluster import completeness_score >>> completeness_score([0, 0, 1, 1], [1, 1, 0, 0]) 1.0
Nicht perfekte Kennzeichnungen, die alle Klassenmitglieder denselben Clustern zuordnen, sind immer noch vollständig
>>> print(completeness_score([0, 0, 1, 1], [0, 0, 0, 0])) 1.0 >>> print(completeness_score([0, 1, 2, 3], [0, 0, 1, 1])) 0.999
Wenn Klassenmitglieder auf verschiedene Cluster aufgeteilt sind, kann die Zuordnung nicht vollständig sein
>>> print(completeness_score([0, 0, 1, 1], [0, 1, 0, 1])) 0.0 >>> print(completeness_score([0, 0, 0, 0], [0, 1, 2, 3])) 0.0
Galeriebeispiele#

Demo des Affinity Propagation Clustering Algorithmus

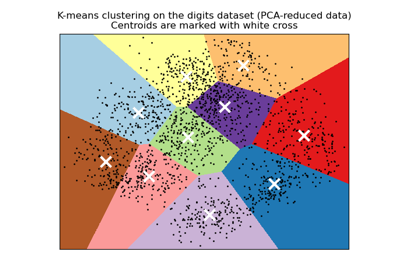
Eine Demo des K-Means Clusterings auf den handschriftlichen Zifferndaten