Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Release Highlights für scikit-learn 1.2#
Wir freuen uns, die Veröffentlichung von scikit-learn 1.2 bekannt zu geben! Viele Fehlerbehebungen und Verbesserungen wurden hinzugefügt, ebenso wie einige neue Kernfunktionen. Im Folgenden beschreiben wir einige der wichtigsten Funktionen dieser Version. **Eine vollständige Liste aller Änderungen** finden Sie in den Release Notes.
Um die neueste Version zu installieren (mit pip)
pip install --upgrade scikit-learn
oder mit conda
conda install -c conda-forge scikit-learn
Pandas-Ausgabe mit der set_output API#
Die Transformer von scikit-learn unterstützen jetzt die Pandas-Ausgabe mit der set_output API. Um mehr über die set_output API zu erfahren, siehe das Beispiel: Einführung der set_output API und dieses Video, Pandas DataFrame-Ausgabe für scikit-learn Transformer (einige Beispiele).
import numpy as np
from sklearn.compose import ColumnTransformer
from sklearn.datasets import load_iris
from sklearn.preprocessing import KBinsDiscretizer, StandardScaler
X, y = load_iris(as_frame=True, return_X_y=True)
sepal_cols = ["sepal length (cm)", "sepal width (cm)"]
petal_cols = ["petal length (cm)", "petal width (cm)"]
preprocessor = ColumnTransformer(
[
("scaler", StandardScaler(), sepal_cols),
(
"kbin",
KBinsDiscretizer(encode="ordinal", quantile_method="averaged_inverted_cdf"),
petal_cols,
),
],
verbose_feature_names_out=False,
).set_output(transform="pandas")
X_out = preprocessor.fit_transform(X)
X_out.sample(n=5, random_state=0)
Interaktionsbeschränkungen in Histogramm-basierten Gradient Boosting Trees#
HistGradientBoostingRegressor und HistGradientBoostingClassifier unterstützen jetzt Interaktionsbeschränkungen mit dem Parameter interaction_cst. Details finden Sie im Benutzerhandbuch. Im folgenden Beispiel dürfen Features nicht interagieren.
from sklearn.datasets import load_diabetes
from sklearn.ensemble import HistGradientBoostingRegressor
X, y = load_diabetes(return_X_y=True, as_frame=True)
hist_no_interact = HistGradientBoostingRegressor(
interaction_cst=[[i] for i in range(X.shape[1])], random_state=0
)
hist_no_interact.fit(X, y)
Neue und erweiterte Anzeigen#
PredictionErrorDisplay bietet eine Möglichkeit, Regressionsmodelle qualitativ zu analysieren.
import matplotlib.pyplot as plt
from sklearn.metrics import PredictionErrorDisplay
fig, axs = plt.subplots(nrows=1, ncols=2, figsize=(12, 5))
_ = PredictionErrorDisplay.from_estimator(
hist_no_interact, X, y, kind="actual_vs_predicted", ax=axs[0]
)
_ = PredictionErrorDisplay.from_estimator(
hist_no_interact, X, y, kind="residual_vs_predicted", ax=axs[1]
)

LearningCurveDisplay ist jetzt verfügbar, um Ergebnisse von learning_curve zu plotten.
from sklearn.model_selection import LearningCurveDisplay
_ = LearningCurveDisplay.from_estimator(
hist_no_interact, X, y, cv=5, n_jobs=2, train_sizes=np.linspace(0.1, 1, 5)
)

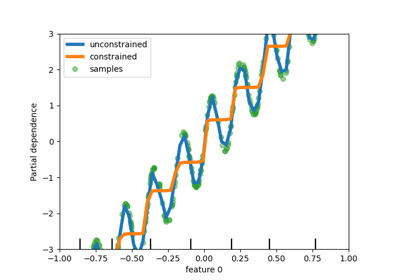
PartialDependenceDisplay stellt einen neuen Parameter categorical_features zur Verfügung, um die partielle Abhängigkeit für kategoriale Merkmale mithilfe von Balkendiagrammen und Heatmaps anzuzeigen.
from sklearn.datasets import fetch_openml
X, y = fetch_openml(
"titanic", version=1, as_frame=True, return_X_y=True, parser="pandas"
)
X = X.select_dtypes(["number", "category"]).drop(columns=["body"])
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OrdinalEncoder
categorical_features = ["pclass", "sex", "embarked"]
model = make_pipeline(
ColumnTransformer(
transformers=[("cat", OrdinalEncoder(), categorical_features)],
remainder="passthrough",
),
HistGradientBoostingRegressor(random_state=0),
).fit(X, y)
from sklearn.inspection import PartialDependenceDisplay
fig, ax = plt.subplots(figsize=(14, 4), constrained_layout=True)
_ = PartialDependenceDisplay.from_estimator(
model,
X,
features=["age", "sex", ("pclass", "sex")],
categorical_features=categorical_features,
ax=ax,
)

Schnellerer Parser in fetch_openml#
fetch_openml unterstützt jetzt einen neuen "pandas"-Parser, der speicher- und CPU-effizienter ist. In v1.4 wird der Standardwert zu parser="auto" geändert, der automatisch den "pandas"-Parser für dichte Daten und "liac-arff" für spärliche Daten verwendet.
X, y = fetch_openml(
"titanic", version=1, as_frame=True, return_X_y=True, parser="pandas"
)
X.head()
Experimentelle Array API-Unterstützung in LinearDiscriminantAnalysis#
Experimentelle Unterstützung für die Array API Spezifikation wurde zu LinearDiscriminantAnalysis hinzugefügt. Der Schätzer kann jetzt auf jeder Array API-konformen Bibliothek wie CuPy, einer GPU-beschleunigten Array-Bibliothek, ausgeführt werden. Details finden Sie im Benutzerhandbuch.
Verbesserte Effizienz vieler Schätzer#
In Version 1.1 wurde die Effizienz vieler Schätzer, die auf der Berechnung von paarweisen Distanzen basieren (im Wesentlichen Schätzer im Zusammenhang mit Clustering-, Manifold-Learning- und Nachbarschaftssuchalgorithmen), für float64-dichte Eingaben stark verbessert. Insbesondere führten Effizienzverbesserungen zu einem reduzierten Speicherbedarf und einer deutlich besseren Skalierbarkeit auf Multi-Core-Maschinen. In Version 1.2 wurde die Effizienz dieser Schätzer für alle Kombinationen von dichten und spärlichen Eingaben auf float32- und float64-Datensätzen weiter verbessert, mit Ausnahme der spärlich-dichten und dicht-spärlichen Kombinationen für die metrischen Abstände Euklidisch und Quadratisch Euklidisch. Eine detaillierte Liste der betroffenen Schätzer finden Sie im Changelog.
Gesamtlaufzeit des Skripts: (0 Minuten 5,676 Sekunden)
Verwandte Beispiele