Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Semi-supervised Classification auf einem Textdatensatz#
Dieses Beispiel demonstriert die Effektivität von semi-supervised Learning für die Textklassifizierung auf Basis von TF-IDF-Features, wenn gelabelte Daten knapp sind. Zu diesem Zweck vergleichen wir vier verschiedene Ansätze
Supervised Learning unter Verwendung von 100 % der Labels im Trainingsdatensatz (Best-Case-Szenario)
Verwendet
SGDClassifiermit voller SupervisionStellt die bestmögliche Leistung dar, wenn gelabelte Daten im Überfluss vorhanden sind
Supervised Learning unter Verwendung von 20 % der Labels im Trainingsdatensatz (Baseline)
Gleiches Modell wie im Best-Case-Szenario, aber trainiert auf einer zufälligen 20 %igen Teilmenge der gelabelten Trainingsdaten
Zeigt die Leistungsdegradation eines vollständig supervised Modells aufgrund begrenzter gelabelter Daten
SelfTrainingClassifier(semi-supervised)Verwendet 20 % gelabelte Daten + 80 % ungelabelte Daten zum Trainieren
Vorhersagt iterativ Labels für ungelabelte Daten
Demonstriert, wie Self-Training die Leistung verbessern kann
LabelSpreading(semi-supervised)Verwendet 20 % gelabelte Daten + 80 % ungelabelte Daten zum Trainieren
Propagiert Labels durch die Datenmannigfaltigkeit
Zeigt, wie graphenbasierte Methoden ungelabelte Daten nutzen können
Das Beispiel verwendet den 20 Newsgroups-Datensatz und konzentriert sich auf fünf Kategorien. Die Ergebnisse zeigen, wie semi-supervised Methoden durch die effektive Nutzung ungelabelter Samples eine bessere Leistung erzielen können als supervised Learning mit begrenzten gelabelten Daten.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
from sklearn.linear_model import SGDClassifier
from sklearn.metrics import f1_score
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.semi_supervised import LabelSpreading, SelfTrainingClassifier
# Loading dataset containing first five categories
data = fetch_20newsgroups(
subset="train",
categories=[
"alt.atheism",
"comp.graphics",
"comp.os.ms-windows.misc",
"comp.sys.ibm.pc.hardware",
"comp.sys.mac.hardware",
],
)
# Parameters
sdg_params = dict(alpha=1e-5, penalty="l2", loss="log_loss")
vectorizer_params = dict(ngram_range=(1, 2), min_df=5, max_df=0.8)
# Supervised Pipeline
pipeline = Pipeline(
[
("vect", CountVectorizer(**vectorizer_params)),
("tfidf", TfidfTransformer()),
("clf", SGDClassifier(**sdg_params)),
]
)
# SelfTraining Pipeline
st_pipeline = Pipeline(
[
("vect", CountVectorizer(**vectorizer_params)),
("tfidf", TfidfTransformer()),
("clf", SelfTrainingClassifier(SGDClassifier(**sdg_params))),
]
)
# LabelSpreading Pipeline
ls_pipeline = Pipeline(
[
("vect", CountVectorizer(**vectorizer_params)),
("tfidf", TfidfTransformer()),
("clf", LabelSpreading()),
]
)
def eval_and_get_f1(clf, X_train, y_train, X_test, y_test):
"""Evaluate model performance and return F1 score"""
print(f" Number of training samples: {len(X_train)}")
print(f" Unlabeled samples in training set: {sum(1 for x in y_train if x == -1)}")
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
f1 = f1_score(y_test, y_pred, average="micro")
print(f" Micro-averaged F1 score on test set: {f1:.3f}")
print("\n")
return f1
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
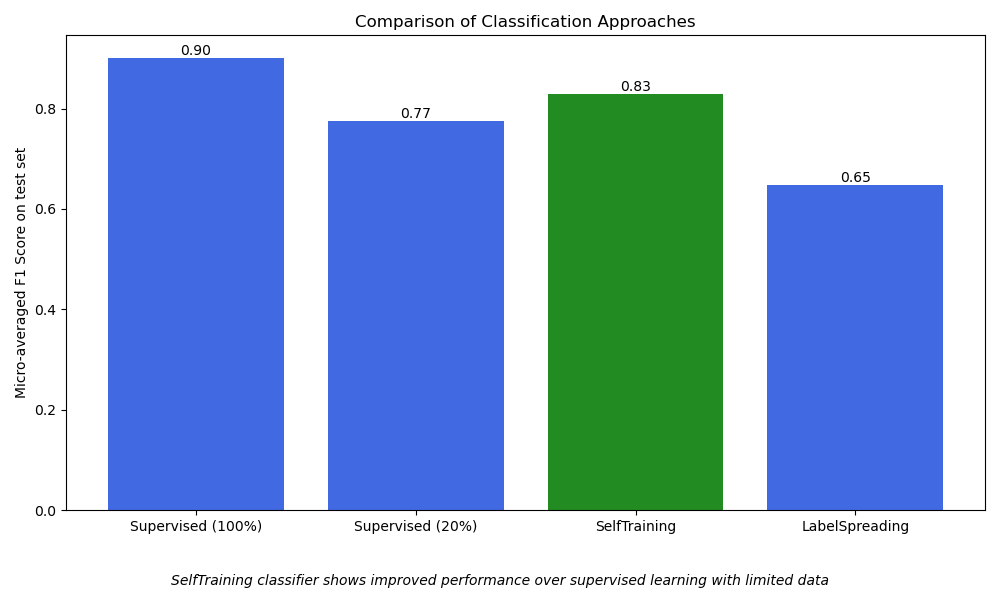
1. Bewerten Sie einen supervised SGDClassifier unter Verwendung von 100 % des (gelabelten) Trainingsdatensatzes. Dies stellt die Best-Case-Leistung dar, wenn das Modell vollen Zugriff auf alle gelabelten Beispiele hat.
f1_scores = {}
print("1. Supervised SGDClassifier on 100% of the data:")
f1_scores["Supervised (100%)"] = eval_and_get_f1(
pipeline, X_train, y_train, X_test, y_test
)
1. Supervised SGDClassifier on 100% of the data:
Number of training samples: 2117
Unlabeled samples in training set: 0
Micro-averaged F1 score on test set: 0.901
2. Bewerten Sie einen supervised SGDClassifier, der nur auf 20 % der Daten trainiert wurde. Dies dient als Baseline, um den Leistungsabfall zu illustrieren, der durch die Einschränkung der Trainingssamples verursacht wird.
import numpy as np
print("2. Supervised SGDClassifier on 20% of the training data:")
rng = np.random.default_rng(42)
y_mask = rng.random(len(y_train)) < 0.2
# X_20 and y_20 are the subset of the train dataset indicated by the mask
X_20, y_20 = map(list, zip(*((x, y) for x, y, m in zip(X_train, y_train, y_mask) if m)))
f1_scores["Supervised (20%)"] = eval_and_get_f1(pipeline, X_20, y_20, X_test, y_test)
2. Supervised SGDClassifier on 20% of the training data:
Number of training samples: 434
Unlabeled samples in training set: 0
Micro-averaged F1 score on test set: 0.775
3. Bewerten Sie einen semi-supervised SelfTrainingClassifier unter Verwendung von 20 % gelabelten und 80 % ungelabelten Daten. Die restlichen 80 % der Trainingslabels werden als ungelabelt (-1) maskiert, was es dem Modell ermöglicht, diese iterativ zu labeln und daraus zu lernen.
print(
"3. SelfTrainingClassifier (semi-supervised) using 20% labeled "
"+ 80% unlabeled data):"
)
y_train_semi = y_train.copy()
y_train_semi[~y_mask] = -1
f1_scores["SelfTraining"] = eval_and_get_f1(
st_pipeline, X_train, y_train_semi, X_test, y_test
)
3. SelfTrainingClassifier (semi-supervised) using 20% labeled + 80% unlabeled data):
Number of training samples: 2117
Unlabeled samples in training set: 1683
Micro-averaged F1 score on test set: 0.829
4. Bewerten Sie ein semi-supervised LabelSpreading-Modell unter Verwendung von 20 % gelabelten und 80 % ungelabelten Daten. Wie SelfTraining leitet das Modell Labels für den ungelabelten Teil der Daten ab, um die Leistung zu verbessern.
print("4. LabelSpreading (semi-supervised) using 20% labeled + 80% unlabeled data:")
f1_scores["LabelSpreading"] = eval_and_get_f1(
ls_pipeline, X_train, y_train_semi, X_test, y_test
)
4. LabelSpreading (semi-supervised) using 20% labeled + 80% unlabeled data:
Number of training samples: 2117
Unlabeled samples in training set: 1683
Micro-averaged F1 score on test set: 0.647
Ergebnisse plotten#
Visualisieren Sie die Leistung verschiedener Klassifizierungsansätze mithilfe eines Balkendiagramms. Dies hilft beim Vergleich der Leistung jeder Methode basierend auf dem mikro-gemittelten f1_score. Mikro-Mittelung berechnet Metriken global über alle Klassen hinweg, was ein einzelnes Gesamtmaß für die Leistung liefert und einen fairen Vergleich zwischen den verschiedenen Ansätzen ermöglicht, auch bei Vorhandensein von Klassenungleichgewichten.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 6))
models = list(f1_scores.keys())
scores = list(f1_scores.values())
colors = ["royalblue", "royalblue", "forestgreen", "royalblue"]
bars = plt.bar(models, scores, color=colors)
plt.title("Comparison of Classification Approaches")
plt.ylabel("Micro-averaged F1 Score on test set")
plt.xticks()
for bar in bars:
height = bar.get_height()
plt.text(
bar.get_x() + bar.get_width() / 2.0,
height,
f"{height:.2f}",
ha="center",
va="bottom",
)
plt.figtext(
0.5,
0.02,
"SelfTraining classifier shows improved performance over "
"supervised learning with limited data",
ha="center",
va="bottom",
fontsize=10,
style="italic",
)
plt.tight_layout()
plt.subplots_adjust(bottom=0.15)
plt.show()
Gesamtlaufzeit des Skripts: (0 Minuten 4,771 Sekunden)
Verwandte Beispiele
Entscheidungsgrenze semi-überwachter Klassifikatoren vs. SVM auf dem Iris-Datensatz

Auswirkung der Änderung des Schwellenwerts für Self-Training