Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Release Highlights für scikit-learn 0.24#
Wir freuen uns, die Veröffentlichung von scikit-learn 0.24 bekannt zu geben! Viele Fehlerbehebungen und Verbesserungen wurden hinzugefügt, ebenso wie einige neue Hauptfunktionen. Nachfolgend stellen wir einige der wichtigsten Funktionen dieser Veröffentlichung im Detail vor. **Eine vollständige Liste aller Änderungen** finden Sie in den Release Notes.
Um die neueste Version zu installieren (mit pip)
pip install --upgrade scikit-learn
oder mit conda
conda install -c conda-forge scikit-learn
Successive Halving-Schätzer zur Abstimmung von Hyperparametern#
Successive Halving, eine moderne Methode, steht nun zur Erkundung des Parameterraums und zur Identifizierung der besten Kombination zur Verfügung. HalvingGridSearchCV und HalvingRandomSearchCV können als Drop-in-Ersatz für GridSearchCV und RandomizedSearchCV verwendet werden. Successive Halving ist ein iterativer Auswahlprozess, der in der folgenden Abbildung dargestellt ist. Die erste Iteration wird mit geringen Ressourcen durchgeführt, wobei die Ressource typischerweise der Anzahl der Trainingsstichproben entspricht, aber auch ein beliebiger ganzzahliger Parameter wie n_estimators in einem Random Forest sein kann. Nur eine Teilmenge der Kandidatenparameter wird für die nächste Iteration ausgewählt, die mit einer zunehmenden Menge an zugewiesenen Ressourcen durchgeführt wird. Nur eine Teilmenge der Kandidaten übersteht den gesamten Iterationsprozess, und der beste Kandidat ist derjenige mit der höchsten Punktzahl in der letzten Iteration.
Lesen Sie mehr im Benutzerhandbuch (Hinweis: Die Successive Halving-Schätzer sind noch experimentell).

import numpy as np
from scipy.stats import randint
from sklearn.datasets import make_classification
from sklearn.ensemble import RandomForestClassifier
from sklearn.experimental import enable_halving_search_cv # noqa: F401
from sklearn.model_selection import HalvingRandomSearchCV
rng = np.random.RandomState(0)
X, y = make_classification(n_samples=700, random_state=rng)
clf = RandomForestClassifier(n_estimators=10, random_state=rng)
param_dist = {
"max_depth": [3, None],
"max_features": randint(1, 11),
"min_samples_split": randint(2, 11),
"bootstrap": [True, False],
"criterion": ["gini", "entropy"],
}
rsh = HalvingRandomSearchCV(
estimator=clf, param_distributions=param_dist, factor=2, random_state=rng
)
rsh.fit(X, y)
rsh.best_params_
{'bootstrap': True, 'criterion': 'gini', 'max_depth': None, 'max_features': 10, 'min_samples_split': 10}
Native Unterstützung für kategorische Merkmale in HistGradientBoosting-Schätzern#
HistGradientBoostingClassifier und HistGradientBoostingRegressor haben jetzt native Unterstützung für kategorische Merkmale: Sie können Teilungen auf nicht-geordnete, kategorische Daten berücksichtigen. Lesen Sie mehr im Benutzerhandbuch.
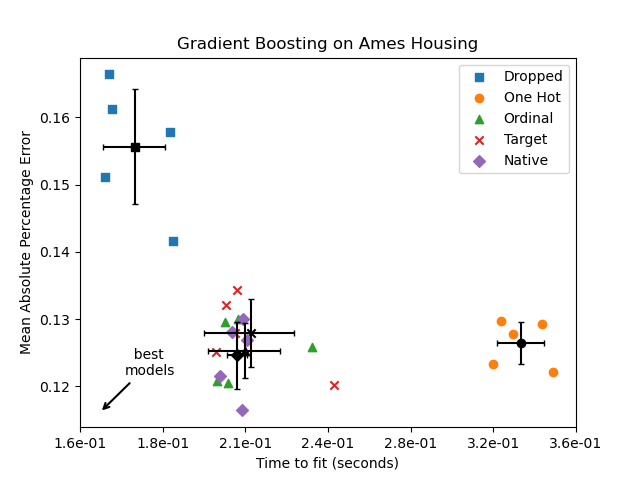
Der Plot zeigt, dass die neue native Unterstützung für kategorische Merkmale zu Trainingszeiten führt, die mit Modellen vergleichbar sind, bei denen die Kategorien als geordnete Größen behandelt werden, d. h. einfach ordinal kodiert. Die native Unterstützung ist auch ausdrucksstärker als sowohl One-Hot-Encoding als auch Ordinal-Encoding. Um den neuen Parameter categorical_features zu verwenden, ist es jedoch immer noch erforderlich, die Daten innerhalb einer Pipeline vorzuverarbeiten, wie in diesem Beispiel gezeigt.
Verbesserte Leistung von HistGradientBoosting-Schätzern#
Der Speicherbedarf von ensemble.HistGradientBoostingRegressor und ensemble.HistGradientBoostingClassifier wurde während der Aufrufe von fit erheblich verbessert. Darüber hinaus erfolgt die Histogramminitialisierung jetzt parallel, was zu leichten Geschwindigkeitsverbesserungen führt. Mehr dazu auf der Benchmark-Seite.
Neuer Self-Training Meta-Schätzer#
Eine neue Self-Training-Implementierung, basierend auf Yarowskis Algorithmus, kann nun mit jedem Klassifikator verwendet werden, der predict_proba implementiert. Der Unterklassifikator verhält sich als semi-überwachter Klassifikator und ermöglicht es ihm, aus unbeschrifteten Daten zu lernen. Lesen Sie mehr im Benutzerhandbuch.
import numpy as np
from sklearn import datasets
from sklearn.semi_supervised import SelfTrainingClassifier
from sklearn.svm import SVC
rng = np.random.RandomState(42)
iris = datasets.load_iris()
random_unlabeled_points = rng.rand(iris.target.shape[0]) < 0.3
iris.target[random_unlabeled_points] = -1
svc = SVC(probability=True, gamma="auto")
self_training_model = SelfTrainingClassifier(svc)
self_training_model.fit(iris.data, iris.target)
Neuer SequentialFeatureSelector-Transformer#
Ein neuer iterativer Transformer zur Auswahl von Merkmalen ist verfügbar: SequentialFeatureSelector. Sequential Feature Selection kann Merkmale einzeln hinzufügen (Vorwärtsselektion) oder Merkmale aus der Liste der verfügbaren Merkmale entfernen (Rückwärtsselektion), basierend auf einer Maximierung des kreuzvalidierten Scores. Sehen Sie im Benutzerhandbuch.
from sklearn.datasets import load_iris
from sklearn.feature_selection import SequentialFeatureSelector
from sklearn.neighbors import KNeighborsClassifier
X, y = load_iris(return_X_y=True, as_frame=True)
feature_names = X.columns
knn = KNeighborsClassifier(n_neighbors=3)
sfs = SequentialFeatureSelector(knn, n_features_to_select=2)
sfs.fit(X, y)
print(
"Features selected by forward sequential selection: "
f"{feature_names[sfs.get_support()].tolist()}"
)
Features selected by forward sequential selection: ['sepal length (cm)', 'petal width (cm)']
Neue PolynomialCountSketch-Kernel-Approximationsfunktion#
Der neue PolynomialCountSketch approximiert eine polynomiale Erweiterung eines Merkmalsraums bei Verwendung mit linearen Modellen, verbraucht aber deutlich weniger Speicher als PolynomialFeatures.
from sklearn.datasets import fetch_covtype
from sklearn.kernel_approximation import PolynomialCountSketch
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import MinMaxScaler
X, y = fetch_covtype(return_X_y=True)
pipe = make_pipeline(
MinMaxScaler(),
PolynomialCountSketch(degree=2, n_components=300),
LogisticRegression(max_iter=1000),
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, train_size=5000, test_size=10000, random_state=42
)
pipe.fit(X_train, y_train).score(X_test, y_test)
0.7361
Zum Vergleich ist hier die Punktzahl eines linearen Basismodells für dieselben Daten
linear_baseline = make_pipeline(MinMaxScaler(), LogisticRegression(max_iter=1000))
linear_baseline.fit(X_train, y_train).score(X_test, y_test)
0.7141
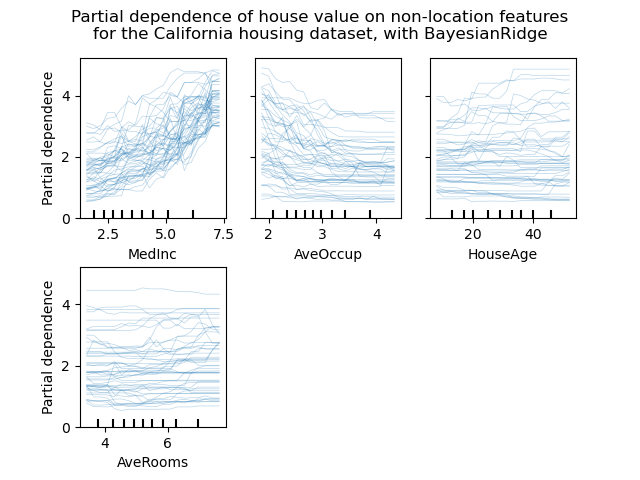
Individual Conditional Expectation Plots#
Eine neue Art von Partial Dependence Plot ist verfügbar: der Individual Conditional Expectation (ICE) Plot. ICE-Plots visualisieren die Abhängigkeit der Vorhersage von einem Merkmal für jede Stichprobe einzeln, mit einer Linie pro Stichprobe. Sehen Sie im Benutzerhandbuch
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import RandomForestRegressor
# from sklearn.inspection import plot_partial_dependence
from sklearn.inspection import PartialDependenceDisplay
X, y = fetch_california_housing(return_X_y=True, as_frame=True)
features = ["MedInc", "AveOccup", "HouseAge", "AveRooms"]
est = RandomForestRegressor(n_estimators=10)
est.fit(X, y)
# plot_partial_dependence has been removed in version 1.2. From 1.2, use
# PartialDependenceDisplay instead.
# display = plot_partial_dependence(
display = PartialDependenceDisplay.from_estimator(
est,
X,
features,
kind="individual",
subsample=50,
n_jobs=3,
grid_resolution=20,
random_state=0,
)
display.figure_.suptitle(
"Partial dependence of house value on non-location features\n"
"for the California housing dataset, with BayesianRidge"
)
display.figure_.subplots_adjust(hspace=0.3)
Neues Poisson-Splitting-Kriterium für DecisionTreeRegressor#
Die Integration der Poisson-Regressionsschätzung wird aus Version 0.23 fortgesetzt. DecisionTreeRegressor unterstützt nun ein neues Splitting-Kriterium 'poisson'. Die Einstellung von criterion="poisson" könnte eine gute Wahl sein, wenn Ihr Ziel eine Anzahl oder eine Frequenz ist.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
n_samples, n_features = 1000, 20
rng = np.random.RandomState(0)
X = rng.randn(n_samples, n_features)
# positive integer target correlated with X[:, 5] with many zeros:
y = rng.poisson(lam=np.exp(X[:, 5]) / 2)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=rng)
regressor = DecisionTreeRegressor(criterion="poisson", random_state=0)
regressor.fit(X_train, y_train)
Neue Verbesserungen der Dokumentation#
Neue Beispiele und Dokumentationsseiten wurden hinzugefügt, in einem kontinuierlichen Bestreben, das Verständnis von maschinellen Lernpraktiken zu verbessern
ein neuer Abschnitt über häufige Fallstricke und empfohlene Vorgehensweisen,
ein Beispiel, das veranschaulicht, wie die Leistung von Modellen statistisch verglichen wird, die mit
GridSearchCVausgewertet wurden,ein Beispiel, wie die Koeffizienten von linearen Modellen interpretiert werden,
ein Beispiel, das Principal Component Regression und Partial Least Squares vergleicht.
Gesamtlaufzeit des Skripts: (0 Minuten 14,909 Sekunden)
Verwandte Beispiele