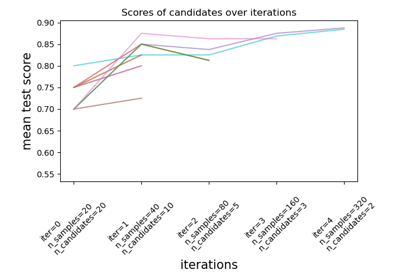
HalvingGridSearchCV#
- class sklearn.model_selection.HalvingGridSearchCV(estimator, param_grid, *, factor=3, resource='n_samples', max_resources='auto', min_resources='exhaust', aggressive_elimination=False, cv=5, scoring=None, refit=True, error_score=nan, return_train_score=True, random_state=None, n_jobs=None, verbose=0)[Quelle]#
Suche nach angegebenen Parameterwerten mit sukzessiver Halbierung.
Die Suchstrategie beginnt mit der Evaluierung aller Kandidaten mit einer geringen Menge an Ressourcen und wählt iterativ die besten Kandidaten aus, wobei mehr und mehr Ressourcen verwendet werden.
Lesen Sie mehr im Benutzerhandbuch.
Hinweis
Dieser Estimator ist derzeit noch experimentell: die Vorhersagen und die API können sich ohne einen Deprecation Cycle ändern. Um ihn zu verwenden, müssen Sie explizit
enable_halving_search_cvimportieren>>> # explicitly require this experimental feature >>> from sklearn.experimental import enable_halving_search_cv # noqa >>> # now you can import normally from model_selection >>> from sklearn.model_selection import HalvingGridSearchCV
- Parameter:
- estimatorEstimator-Objekt
Es wird angenommen, dass dies die scikit-learn-Estimator-Schnittstelle implementiert. Entweder muss der Estimator eine
scoreFunktion bereitstellen, oderscoringmuss übergeben werden.- param_griddict oder Liste von Dictionaries
Dictionary mit Parameternamen (String) als Schlüssel und Listen von Parameter-Einstellungen zum Ausprobieren als Werte, oder eine Liste solcher Dictionaries, in welchem Fall die von jedem Dictionary in der Liste aufgespannten Gitter durchsucht werden. Dies ermöglicht die Suche über jede Sequenz von Parameter-Einstellungen.
- factorint oder float, Standardwert=3
Der Parameter „Halving“, der den Anteil der Kandidaten bestimmt, die für jede nachfolgende Iteration ausgewählt werden. Zum Beispiel bedeutet
factor=3, dass nur ein Drittel der Kandidaten ausgewählt wird.- resource
'n_samples'oder str, Standardwert=’n_samples’ Definiert die Ressource, die mit jeder Iteration zunimmt. Standardmäßig ist die Ressource die Anzahl der Samples. Sie kann auch auf jeden Parameter des Basis-Estimators gesetzt werden, der positive ganzzahlige Werte akzeptiert, z. B. „n_iterations“ oder „n_estimators“ für einen Gradient Boosting Estimator. In diesem Fall kann
max_resourcesnicht „auto“ sein und muss explizit gesetzt werden.- max_resourcesint, Standardwert=’auto’
Die maximale Ressource, die jeder Kandidat für eine gegebene Iteration verwenden darf. Standardmäßig ist dies auf
n_samplesgesetzt, wennresource='n_samples'(Standard), andernfalls wird ein Fehler ausgelöst.- min_resources{‘exhaust’, ‘smallest’} oder int, Standardwert=’exhaust’
Die minimale Ressource, die jeder Kandidat für eine gegebene Iteration verwenden darf. Äquivalent dazu definiert dies die Ressourcengröße
r0, die jedem Kandidaten in der ersten Iteration zugewiesen wird.‘smallest’ ist eine Heuristik, die
r0auf einen kleinen Wert setztn_splits * 2wennresource='n_samples'für ein Regressionsproblemn_classes * n_splits * 2wennresource='n_samples'für ein Klassifizierungsproblem1wennresource != 'n_samples'
‘exhaust’ setzt
r0so, dass die letzte Iteration so viele Ressourcen wie möglich verwendet. Insbesondere verwendet die letzte Iteration den höchsten Wert, der kleiner alsmax_resourcesist und sowohl ein Vielfaches vonmin_resourcesals auch vonfactorist. Im Allgemeinen führt die Verwendung von 'exhaust' zu einem genaueren Estimator, ist aber etwas zeitaufwändiger.
Beachten Sie, dass die in jeder Iteration verwendete Ressourcengröße immer ein Vielfaches von
min_resourcesist.- aggressive_eliminationbool, Standardwert=False
Dies ist nur relevant, wenn nicht genügend Ressourcen vorhanden sind, um die verbleibenden Kandidaten nach der letzten Iteration auf maximal
factorzu reduzieren. WennTrue, dann wird der Suchprozess die erste Iteration so lange „wiederholen“, bis die Anzahl der Kandidaten klein genug ist. Dies ist standardmäßigFalse, was bedeutet, dass die letzte Iteration mehr alsfactorKandidaten auswerten kann. Weitere Details finden Sie unter Aggressive Eliminierung von Kandidaten.- cvint, Kreuzvalidierungsgenerator oder Iterable, Standardwert=5
Bestimmt die Strategie der Kreuzvalidierungsaufteilung. Mögliche Eingaben für cv sind
Ganzzahl, um die Anzahl der Folds in einem
(Stratified)KFoldanzugeben,Eine iterierbare Liste, die (Trainings-, Test-) Splits als Indizes-Arrays liefert.
Für Ganzzahl-/None-Eingaben, wenn der Schätzer ein Klassifikator ist und
yentweder binär oder multiklassig ist, wirdStratifiedKFoldverwendet. In allen anderen Fällen wirdKFoldverwendet. Diese Splitter werden mitshuffle=Falseinstanziiert, sodass die Splits bei jedem Aufruf gleich sind.Siehe Benutzerhandbuch für die verschiedenen Kreuzvalidierungsstrategien, die hier verwendet werden können.
Hinweis
Aus Implementierungsgründen müssen die von
cverzeugten Folds über mehrere Aufrufe voncv.split()hinweg gleich sein. Für eingebautescikit-learnIteratoren kann dies durch Deaktivieren des Shufflings (shuffle=False) oder durch Setzen desrandom_stateParameters voncvauf einen Integer erreicht werden.- scoringstr oder callable, Standardwert=None
Scoring-Methode, die zur Auswertung der Vorhersagen auf dem Testset verwendet wird.
str: siehe Zeichenkettennamen für Bewerter für Optionen.
callable: Ein Scorer-Callable-Objekt (z. B. Funktion) mit der Signatur
scorer(estimator, X, y). Siehe Callable Scorer für Details.None: das Standard-Bewertungskriterium desestimatorwird verwendet.
- refitbool oder callable, Standardwert=True
Refitt einen Estimator mit den besten gefundenen Parametern auf dem gesamten Datensatz.
Wenn bei der Auswahl eines besten Estimators andere Überlegungen als die maximale Punktzahl eine Rolle spielen, kann
refitauf eine Funktion gesetzt werden, die den ausgewähltenbest_index_basierend aufcv_results_zurückgibt. In diesem Fall werdenbest_estimator_undbest_params_entsprechend dem zurückgegebenenbest_index_gesetzt, während das Attributbest_score_nicht verfügbar ist.Der neu angepasste Estimator ist unter dem Attribut
best_estimator_verfügbar und ermöglicht die direkte Verwendung vonpredictauf dieserHalvingGridSearchCVInstanz.Siehe dieses Beispiel für ein Beispiel, wie
refit=callableverwendet wird, um Modellkomplexität und kreuzvalidierte Scores auszubalancieren.- error_score‘raise’ oder numeric
Wert, der dem Score zugewiesen wird, wenn ein Fehler bei der Anpassung des Estimators auftritt. Wenn auf 'raise' gesetzt, wird der Fehler ausgelöst. Wenn ein numerischer Wert angegeben wird, wird FitFailedWarning ausgelöst. Dieser Parameter beeinflusst nicht den Refit-Schritt, der immer den Fehler auslösen wird. Standard ist
np.nan.- return_train_scorebool, default=False
Wenn
False, enthält das Attributcv_results_keine Trainingsscores. Die Berechnung von Trainingsscores wird verwendet, um Einblicke zu gewinnen, wie sich verschiedene Parameter-Einstellungen auf den Kompromiss zwischen Überanpassung/Unteranpassung auswirken. Die Berechnung von Scores auf dem Trainingsdatensatz kann jedoch rechenintensiv sein und ist nicht unbedingt erforderlich, um die Parameter auszuwählen, die die beste Generalisierungsleistung erzielen.- random_stateint, RandomState-Instanz oder None, default=None
Pseudo-Zufallszahlengenerator-Zustand, der für das Subsampling des Datensatzes verwendet wird, wenn
resources != 'n_samples'. Andernfalls ignoriert. Übergeben Sie eine Ganzzahl für reproduzierbare Ausgaben über mehrere Funktionsaufrufe hinweg. Siehe Glossar.- n_jobsint oder None, default=None
Anzahl der parallel auszuführenden Jobs.
Nonebedeutet 1, es sei denn, es befindet sich in einemjoblib.parallel_backendKontext.-1bedeutet die Verwendung aller Prozessoren. Siehe Glossar für weitere Details.- verboseint
Steuert die Ausführlichkeit: je höher, desto mehr Meldungen.
- Attribute:
- n_resources_Liste von int
Die in jeder Iteration verwendete Ressourcengröße.
- n_candidates_Liste von int
Die Anzahl der Kandidatenparameter, die in jeder Iteration ausgewertet wurden.
- n_remaining_candidates_int
Die Anzahl der verbleibenden Kandidatenparameter nach der letzten Iteration. Dies entspricht
ceil(n_candidates[-1] / factor)- max_resources_int
Die maximale Anzahl von Ressourcen, die jeder Kandidat für eine gegebene Iteration verwenden darf. Beachten Sie, dass da die in jeder Iteration verwendete Ressourcengröße ein Vielfaches von
min_resources_sein muss, die tatsächliche Ressourcengröße in der letzten Iteration kleiner alsmax_resources_sein kann.- min_resources_int
Die Ressourcengröße, die jedem Kandidaten in der ersten Iteration zugewiesen wird.
- n_iterations_int
Die tatsächliche Anzahl der durchgeführten Iterationen. Dies ist gleich
n_required_iterations_wennaggressive_eliminationTrueist. Andernfalls ist dies gleichmin(n_possible_iterations_, n_required_iterations_).- n_possible_iterations_int
Die Anzahl der Iterationen, die möglich sind, beginnend mit
min_resources_Ressourcen und ohnemax_resources_zu überschreiten.- n_required_iterations_int
Die Anzahl der Iterationen, die benötigt werden, um mit weniger als
factorKandidaten in der letzten Iteration zu enden, beginnend mitmin_resources_Ressourcen. Dies wird kleiner alsn_possible_iterations_sein, wenn nicht genügend Ressourcen vorhanden sind.- cv_results_dict von numpy (masked) ndarrays
Ein Dictionary mit Spaltenüberschriften als Schlüssel und Spalten als Werte, das in einen Pandas
DataFrameimportiert werden kann. Es enthält viele Informationen zur Analyse der Ergebnisse einer Suche. Bitte beachten Sie das Benutzerhandbuch für Details. Ein Beispiel für die Analyse voncv_results_finden Sie unter Statistischer Vergleich von Modellen mittels Grid Search.- best_estimator_estimator oder dict
Estimator, der von der Suche ausgewählt wurde, d.h. der Estimator, der den höchsten Score (oder den kleinsten Verlust, falls angegeben) auf den zurückgelassenen Daten erzielte. Nicht verfügbar, wenn
refit=False.- best_score_float
Durchschnittliche kreuzvalidierte Punktzahl des `best_estimator`.
- best_params_dict
Parameter-Einstellung, die die besten Ergebnisse auf den zurückgelassenen Daten lieferte.
- best_index_int
Der Index (der
cv_results_Arrays), der der besten Kandidaten-Parameter-Einstellung entspricht.Das Dictionary unter
search.cv_results_['params'][search.best_index_]gibt die Parameter-Einstellung für das beste Modell an, das den höchsten mittleren Score (search.best_score_) erzielt.- scorer_function oder ein dict
Score-Funktion, die auf den zurückgelassenen Daten verwendet wird, um die besten Parameter für das Modell auszuwählen.
- n_splits_int
Die Anzahl der Kreuzvalidierungs-Splits (Falten/Iterationen).
- refit_time_float
Sekunden, die für das Refitten des besten Modells auf dem gesamten Datensatz aufgewendet wurden.
Dies ist nur verfügbar, wenn
refitnicht False ist.- multimetric_bool
Ob die Scorer mehrere Metriken berechnen oder nicht.
classes_ndarray der Form (n_classes,)Klassenbezeichnungen.
n_features_in_intAnzahl der während des fits gesehenen Merkmale.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Features. Nur definiert, wenn
best_estimator_definiert ist (siehe Dokumentation des Parametersrefitfür weitere Details) und wennbest_estimator_bei der Anpassungfeature_names_in_exponiert.Hinzugefügt in Version 1.0.
Siehe auch
HalvingRandomSearchCVZufällige Suche über einen Satz von Parametern mittels sukzessiver Halbierung.
Anmerkungen
Die ausgewählten Parameter sind diejenigen, die die Punktzahl der zurückgehaltenen Daten gemäß dem Scoring-Parameter maximieren.
Alle Parameterkombinationen, die mit einem NaN bewertet werden, teilen sich den niedrigsten Rang.
Beispiele
>>> from sklearn.datasets import load_iris >>> from sklearn.ensemble import RandomForestClassifier >>> from sklearn.experimental import enable_halving_search_cv # noqa >>> from sklearn.model_selection import HalvingGridSearchCV ... >>> X, y = load_iris(return_X_y=True) >>> clf = RandomForestClassifier(random_state=0) ... >>> param_grid = {"max_depth": [3, None], ... "min_samples_split": [5, 10]} >>> search = HalvingGridSearchCV(clf, param_grid, resource='n_estimators', ... max_resources=10, ... random_state=0).fit(X, y) >>> search.best_params_ {'max_depth': None, 'min_samples_split': 10, 'n_estimators': 9}
- decision_function(X)[Quelle]#
Ruft decision_function auf dem Estimator mit den besten gefundenen Parametern auf.
Nur verfügbar, wenn
refit=Trueund der zugrunde liegende Estimatordecision_functionunterstützt.- Parameter:
- Xindexierbar, Länge n_samples
Muss die Eingabeannahmen des zugrunde liegenden Estimators erfüllen.
- Gibt zurück:
- y_scorendarray der Form (n_samples,) oder (n_samples, n_classes) oder (n_samples, n_classes * (n_classes-1) / 2)
Ergebnis der Entscheidungsfunktion für
Xbasierend auf dem Estimator mit den besten gefundenen Parametern.
- fit(X, y=None, **params)[Quelle]#
Führt fit mit allen Parameter-Sätzen aus.
- Parameter:
- Xarray-ähnlich, Form (n_samples, n_features)
Trainingsvektor, wobei
n_samplesdie Anzahl der Stichproben undn_featuresdie Anzahl der Merkmale ist.- yarray-like, Form (n_samples,) oder (n_samples, n_output), optional
Ziel relativ zu X für Klassifikation oder Regression; None für unüberwachtes Lernen.
- **paramsDict von String -> Objekt
Parameter, die an die
fitMethode des Estimators übergeben werden.
- Gibt zurück:
- selfobject
Instanz des angepassten Estimators.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
Hinzugefügt in Version 1.4.
- Gibt zurück:
- routingMetadataRouter
Ein
MetadataRouter, der die Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- inverse_transform(X)[Quelle]#
Ruft inverse_transform auf dem Estimator mit den besten gefundenen Parametern auf.
Nur verfügbar, wenn der zugrunde liegende Estimator
inverse_transformimplementiert undrefit=True.- Parameter:
- Xindexierbar, Länge n_samples
Muss die Eingabeannahmen des zugrunde liegenden Estimators erfüllen.
- Gibt zurück:
- X_original{ndarray, sparse matrix} der Form (n_samples, n_features)
Ergebnis der
inverse_transformFunktion fürXbasierend auf dem Estimator mit den besten gefundenen Parametern.
- predict(X)[Quelle]#
Ruft predict auf dem Estimator mit den besten gefundenen Parametern auf.
Nur verfügbar, wenn
refit=Trueund der zugrunde liegende Estimatorpredictunterstützt.- Parameter:
- Xindexierbar, Länge n_samples
Muss die Eingabeannahmen des zugrunde liegenden Estimators erfüllen.
- Gibt zurück:
- y_predndarray von Form (n_samples,)
Die vorhergesagten Labels oder Werte für
Xbasierend auf dem Estimator mit den besten gefundenen Parametern.
- predict_log_proba(X)[Quelle]#
Ruft predict_log_proba auf dem Estimator mit den besten gefundenen Parametern auf.
Nur verfügbar, wenn
refit=Trueund der zugrunde liegende Estimatorpredict_log_probaunterstützt.- Parameter:
- Xindexierbar, Länge n_samples
Muss die Eingabeannahmen des zugrunde liegenden Estimators erfüllen.
- Gibt zurück:
- y_predndarray der Form (n_samples,) oder (n_samples, n_classes)
Vorhergesagte Log-Wahrscheinlichkeiten der Klassen für
Xbasierend auf dem Estimator mit den besten gefundenen Parametern. Die Reihenfolge der Klassen entspricht der im angepassten Attribut classes_.
- predict_proba(X)[Quelle]#
Ruft predict_proba auf dem Estimator mit den besten gefundenen Parametern auf.
Nur verfügbar, wenn
refit=Trueund der zugrunde liegende Estimatorpredict_probaunterstützt.- Parameter:
- Xindexierbar, Länge n_samples
Muss die Eingabeannahmen des zugrunde liegenden Estimators erfüllen.
- Gibt zurück:
- y_predndarray der Form (n_samples,) oder (n_samples, n_classes)
Vorhergesagte Klassentwahrscheinlichkeiten für
Xbasierend auf dem Estimator mit den besten gefundenen Parametern. Die Reihenfolge der Klassen entspricht der im angepassten Attribut classes_.
- score(X, y=None, **params)[Quelle]#
Gibt den Score auf den gegebenen Daten zurück, wenn der Estimator refittet wurde.
Dies verwendet den durch
scoringdefinierten Score, sofern angegeben, andernfalls diebest_estimator_.scoreMethode.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Eingabedaten, wobei
n_samplesdie Anzahl der Stichproben undn_featuresdie Anzahl der Merkmale ist.- yarray-ähnlich der Form (n_samples, n_output) oder (n_samples,), default=None
Ziel relativ zu X für Klassifikation oder Regression; None für unüberwachtes Lernen.
- **paramsdict
An den zugrunde liegenden Scorer(-s) zu übergebende Parameter.
Hinzugefügt in Version 1.4: Nur verfügbar, wenn
enable_metadata_routing=True. Siehe Benutzerhandbuch zur Metadaten-Weiterleitung für weitere Details.
- Gibt zurück:
- scorefloat
Der durch
scoringdefinierte Score, sofern angegeben, andernfalls diebest_estimator_.scoreMethode.
- score_samples(X)[Quelle]#
Ruft score_samples auf dem Estimator mit den besten gefundenen Parametern auf.
Nur verfügbar, wenn
refit=Trueund der zugrunde liegende Estimatorscore_samplesunterstützt.Hinzugefügt in Version 0.24.
- Parameter:
- XIterable
Daten, auf denen vorhergesagt werden soll. Muss die Eingabevoraussetzungen des zugrunde liegenden Estimators erfüllen.
- Gibt zurück:
- y_scorendarray der Form (n_samples,)
Die
best_estimator_.score_samplesMethode.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- transform(X)[Quelle]#
Ruft transform auf dem Estimator mit den besten gefundenen Parametern auf.
Nur verfügbar, wenn der zugrunde liegende Estimator
transformunterstützt undrefit=True.- Parameter:
- Xindexierbar, Länge n_samples
Muss die Eingabeannahmen des zugrunde liegenden Estimators erfüllen.
- Gibt zurück:
- Xt{ndarray, sparse matrix} der Form (n_samples, n_features)
Xtransformiert in den neuen Raum basierend auf dem Estimator mit den besten gefundenen Parametern.
Galeriebeispiele#
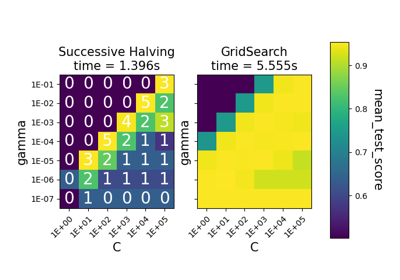
Vergleich zwischen Gitter-Suche und sukzessiver Halbierung