fetch_20newsgroups_vectorized#
- sklearn.datasets.fetch_20newsgroups_vectorized(*, subset='train', remove=(), data_home=None, download_if_missing=True, return_X_y=False, normalize=True, as_frame=False, n_retries=3, delay=1.0)[Quelle]#
Lädt und vektorisiert den 20 newsgroups Datensatz (Klassifikation).
Bei Bedarf herunterladen.
Dies ist eine praktische Funktion; die Transformation erfolgt mit den Standardeinstellungen für
CountVectorizer. Für fortgeschrittenere Anwendungen (Filterung von Stoppwörtern, Extraktion von N-Grammen usw.) kombinieren Sie fetch_20newsgroups mit einem benutzerdefiniertenCountVectorizer,HashingVectorizer,TfidfTransformeroderTfidfVectorizer.Die resultierenden Zählungen werden mit
sklearn.preprocessing.normalizenormalisiert, es sei denn, normalize ist auf False gesetzt.Klassen
20
Gesamtanzahl Samples
18846
Dimensionalität
130107
Merkmale
real
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- subset{‘train’, ‘test’, ‘all’}, default=’train’
Wählen Sie den zu ladenden Datensatz aus: ‘train’ für den Trainingsdatensatz, ‘test’ für den Testdatensatz, ‘all’ für beide, mit gemischter Reihenfolge.
- removetuple, default=()
Kann eine beliebige Teilmenge von (‘headers’, ‘footers’, ‘quotes’) enthalten. Jede dieser Textarten wird aus den Newsgroups-Posts erkannt und entfernt, um zu verhindern, dass Klassifikatoren auf Metadaten überangepasst werden.
‘headers’ entfernt Newsgroups-Header, ‘footers’ entfernt Blöcke am Ende von Beiträgen, die wie Signaturen aussehen, und ‘quotes’ entfernt Zeilen, die offensichtlich einen anderen Beitrag zitieren.
- data_homestr oder path-like, Standard=None
Geben Sie einen Download- und Cache-Ordner für die Datensätze an. Wenn None, werden alle scikit-learn-Daten in Unterordnern von ‘~/scikit_learn_data’ gespeichert.
- download_if_missingbool, Standard=True
Wenn False, wird eine OSError ausgelöst, wenn die Daten nicht lokal verfügbar sind, anstatt zu versuchen, die Daten von der Quell-Website herunterzuladen.
- return_X_ybool, Standard=False
Wenn True, wird
(data.data, data.target)anstelle eines Bunch-Objekts zurückgegeben.Hinzugefügt in Version 0.20.
- normalizebool, default=True
Wenn True, normalisiert jeden Feature-Vektor eines Dokuments mit
sklearn.preprocessing.normalizeauf die Einheitsnorm.Hinzugefügt in Version 0.22.
- as_framebool, default=False
Wenn True, sind die Daten ein pandas DataFrame, das Spalten mit geeigneten Datentypen (numerisch, Zeichenkette oder kategorisch) enthält. Das Ziel ist ein pandas DataFrame oder eine Series, abhängig von der Anzahl der
target_columns.Hinzugefügt in Version 0.24.
- n_retriesint, Standard=3
Anzahl der Wiederholungsversuche bei HTTP-Fehlern.
Hinzugefügt in Version 1.5.
- delayfloat, Standard=1.0
Anzahl der Sekunden zwischen den Wiederholungsversuchen.
Hinzugefügt in Version 1.5.
- Gibt zurück:
- bunch
Bunch Dictionary-ähnliches Objekt mit den folgenden Attributen.
- data: {sparse matrix, dataframe} von Form (n_samples, n_features)
Die Eingabematrix. Wenn
as_frameTrueist, istdataein pandas DataFrame mit spärlichen Spalten.- target: {ndarray, series} von Form (n_samples,)
Die Ziel-Labels. Wenn
as_frameTrueist, isttargeteine pandas Series.- target_names: list von Form (n_classes,)
Die Namen der Zielklassen.
- DESCR: str
Die vollständige Beschreibung des Datensatzes.
- frame: dataframe von Form (n_samples, n_features + 1)
Nur vorhanden, wenn
as_frame=True. Pandas DataFrame mitdataundtarget.Hinzugefügt in Version 0.24.
- (data, target)tuple, wenn
return_X_yTrue ist dataundtargethätten das Format, das in derBunch-Beschreibung oben definiert ist.Hinzugefügt in Version 0.20.
- bunch
Beispiele
>>> from sklearn.datasets import fetch_20newsgroups_vectorized >>> newsgroups_vectorized = fetch_20newsgroups_vectorized(subset='test') >>> newsgroups_vectorized.data.shape (7532, 130107) >>> newsgroups_vectorized.target.shape (7532,)
Galeriebeispiele#
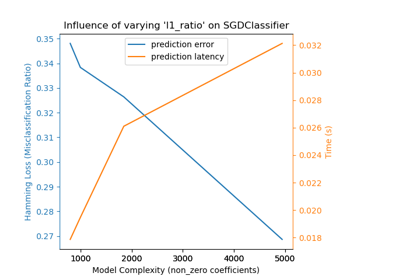
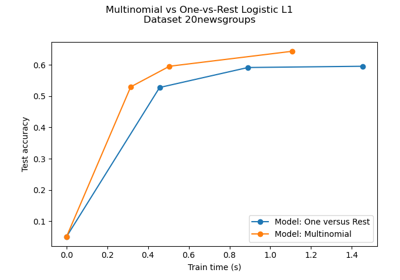
Multiklassen-Sparse-Logistische-Regression auf 20newgroups
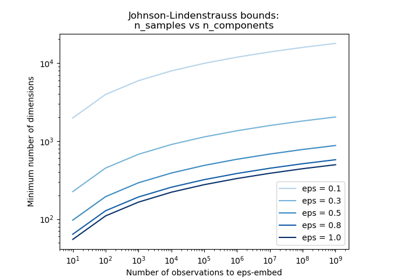
Die Johnson-Lindenstrauss-Schranke für Einbettung mit zufälligen Projektionen