TfidfTransformer#
- class sklearn.feature_extraction.text.TfidfTransformer(*, norm='l2', use_idf=True, smooth_idf=True, sublinear_tf=False)[Quelle]#
Transformiert eine Zählmatrix in eine normalisierte TF- oder TF-IDF-Darstellung.
Tf steht für Term-Frequenz (Termhäufigkeit), während tf-idf für Term-Frequenz mal Inverse Document-Frequenz steht. Dies ist ein gängiges Schema zur Gewichtung von Termen in der Informationsrückgewinnung, das auch in der Dokumentenklassifizierung gute Dienste leistet.
Das Ziel der Verwendung von tf-idf anstelle der rohen Häufigkeiten des Vorkommens eines Tokens in einem bestimmten Dokument ist es, die Auswirkungen von Tokens zu reduzieren, die in einem gegebenen Korpus sehr häufig vorkommen und somit empirisch weniger informativ sind als Merkmale, die in einem kleinen Bruchteil des Trainingskorpus vorkommen.
Die Formel zur Berechnung des tf-idf für einen Term t eines Dokuments d in einer Dokumentensammlung lautet tf-idf(t, d) = tf(t, d) * idf(t), und das idf wird wie folgt berechnet: idf(t) = log [ n / df(t) ] + 1 (wenn
smooth_idf=False), wobei n die Gesamtzahl der Dokumente in der Dokumentensammlung und df(t) die Dokumentenhäufigkeit von t ist; die Dokumentenhäufigkeit ist die Anzahl der Dokumente in der Dokumentensammlung, die den Term t enthalten. Die Auswirkung des Hinzufügens von "1" zum idf in der obigen Gleichung ist, dass Terme mit einem idf von Null, d. h. Terme, die in allen Dokumenten eines Trainingssatzes vorkommen, nicht vollständig ignoriert werden. (Beachten Sie, dass sich die obige idf-Formel von der Standardnotation in Lehrbüchern unterscheidet, die das idf als idf(t) = log [ n / (df(t) + 1) ] definiert).Wenn
smooth_idf=True(Standard), wird die Konstante "1" zum Zähler und Nenner des idf addiert, als ob ein zusätzliches Dokument gesehen worden wäre, das jeden Term in der Sammlung genau einmal enthält, was Null-Divisionen verhindert: idf(t) = log [ (1 + n) / (1 + df(t)) ] + 1.Darüber hinaus hängen die zur Berechnung von tf und idf verwendeten Formeln von Parametereinstellungen ab, die den im IR verwendeten SMART-Notationen wie folgt entsprechen:
Tf ist standardmäßig "n" (natürlich), "l" (logarithmisch) bei
sublinear_tf=True. Idf ist "t", wenn use_idf angegeben ist, andernfalls "n" (keines). Normalisierung ist "c" (Kosinus) beinorm='l2', "n" (keines) beinorm=None.Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- norm{‘l1’, ‘l2’} oder None, Standard=’l2’
Jede Ausgabereihe hat eine Einheitsnorm, entweder
‘l2’: Die Summe der Quadrate der Vektorelemente ist 1. Die Kosinus-Ähnlichkeit zwischen zwei Vektoren ist ihr Skalarprodukt, wenn die l2-Norm angewendet wurde.
‘l1’: Die Summe der Absolutwerte der Vektorelemente ist 1. Siehe
normalize.None: Keine Normalisierung.
- use_idfbool, Standard=True
Inverse-Dokument-Frequenz-Neugewichtung aktivieren. Wenn False, ist idf(t) = 1.
- smooth_idfbool, Standard=True
Gleicht idf-Gewichte ab, indem zur Dokumentenhäufigkeit eins addiert wird, als ob ein zusätzliches Dokument gesehen worden wäre, das jeden Term der Sammlung genau einmal enthält. Verhindert Null-Divisionen.
- sublinear_tfbool, Standard=False
Wenden Sie sublineare tf-Skalierung an, d. h. ersetzen Sie tf durch 1 + log(tf).
- Attribute:
- idf_Array der Form (n_features)
Der Inverse-Dokument-Frequenz-Vektor (IDF); nur definiert, wenn
use_idfTrue ist.Hinzugefügt in Version 0.20.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 1.0.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
Siehe auch
CountVectorizerTransformiert Text in eine Sparse-Matrix von n-Gramm-Zählungen.
TfidfVectorizerKonvertiert eine Sammlung von Rohdokumenten in eine Matrix von TF-IDF-Merkmalen.
HashingVectorizerKonvertiert eine Sammlung von Textdokumenten in eine Matrix von Token-Vorkommen.
Referenzen
[Yates2011]R. Baeza-Yates und B. Ribeiro-Neto (2011). Modern Information Retrieval. Addison Wesley, S. 68-74.
[MRS2008]C.D. Manning, P. Raghavan und H. Schütze (2008). Introduction to Information Retrieval. Cambridge University Press, S. 118-120.
Beispiele
>>> from sklearn.feature_extraction.text import TfidfTransformer >>> from sklearn.feature_extraction.text import CountVectorizer >>> from sklearn.pipeline import Pipeline >>> corpus = ['this is the first document', ... 'this document is the second document', ... 'and this is the third one', ... 'is this the first document'] >>> vocabulary = ['this', 'document', 'first', 'is', 'second', 'the', ... 'and', 'one'] >>> pipe = Pipeline([('count', CountVectorizer(vocabulary=vocabulary)), ... ('tfid', TfidfTransformer())]).fit(corpus) >>> pipe['count'].transform(corpus).toarray() array([[1, 1, 1, 1, 0, 1, 0, 0], [1, 2, 0, 1, 1, 1, 0, 0], [1, 0, 0, 1, 0, 1, 1, 1], [1, 1, 1, 1, 0, 1, 0, 0]]) >>> pipe['tfid'].idf_ array([1. , 1.22314355, 1.51082562, 1. , 1.91629073, 1. , 1.91629073, 1.91629073]) >>> pipe.transform(corpus).shape (4, 8)
- fit(X, y=None)[Quelle]#
Lernt den idf-Vektor (globale Termgewichte).
- Parameter:
- Xspärliche Matrix der Form (n_samples, n_features)
Eine Matrix von Term-/Token-Zählungen.
- yNone
Dieser Parameter wird nicht benötigt, um tf-idf zu berechnen.
- Gibt zurück:
- selfobject
Gefitteter Transformer.
- fit_transform(X, y=None, **fit_params)[Quelle]#
An Daten anpassen, dann transformieren.
Passt den Transformer an
Xundymit optionalen Parameternfit_paramsan und gibt eine transformierte Version vonXzurück.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Eingabestichproben.
- yarray-like der Form (n_samples,) oder (n_samples, n_outputs), Standardwert=None
Zielwerte (None für unüberwachte Transformationen).
- **fit_paramsdict
Zusätzliche Fit-Parameter. Nur übergeben, wenn der Estimator zusätzliche Parameter in seiner
fit-Methode akzeptiert.
- Gibt zurück:
- X_newndarray array der Form (n_samples, n_features_new)
Transformiertes Array.
- get_feature_names_out(input_features=None)[Quelle]#
Holt die Ausgabemerkmale für die Transformation.
- Parameter:
- input_featuresarray-like von str oder None, default=None
Eingabemerkmale.
Wenn
input_featuresNoneist, werdenfeature_names_in_als Merkmalnamen verwendet. Wennfeature_names_in_nicht definiert ist, werden die folgenden Eingabemerkmalsnamen generiert:["x0", "x1", ..., "x(n_features_in_ - 1)"].Wenn
input_featuresein Array-ähnliches Objekt ist, mussinput_featuresmitfeature_names_in_übereinstimmen, wennfeature_names_in_definiert ist.
- Gibt zurück:
- feature_names_outndarray von str-Objekten
Gleich wie Eingabemerkmale.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- set_output(*, transform=None)[Quelle]#
Ausgabecontainer festlegen.
Siehe Einführung in die set_output API für ein Beispiel zur Verwendung der API.
- Parameter:
- transform{“default”, “pandas”, “polars”}, default=None
Konfiguriert die Ausgabe von
transformundfit_transform."default": Standardausgabeformat eines Transformers"pandas": DataFrame-Ausgabe"polars": Polars-AusgabeNone: Die Transformationskonfiguration bleibt unverändert
Hinzugefügt in Version 1.4: Die Option
"polars"wurde hinzugefügt.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_transform_request(*, copy: bool | None | str = '$UNCHANGED$') TfidfTransformer[Quelle]#
Konfiguriert, ob Metadaten für die
transform-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, antransformweitergegeben. Die Anforderung wird ignoriert, wenn keine Metadaten bereitgestellt werden.False: Metadaten werden nicht angefordert und die Meta-Schätzung übergibt sie nicht antransform.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- copystr, True, False oder None, Standard=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
copyintransform.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- transform(X, copy=True)[Quelle]#
Transformiert eine Zählmatrix in eine tf- oder tf-idf-Darstellung.
- Parameter:
- XSparse-Matrix von (n_samples, n_features)
Eine Matrix von Term-/Token-Zählungen.
- copybool, Standard=True
Ob X kopiert und auf der Kopie gearbeitet werden soll oder ob Operationen vor Ort ausgeführt werden sollen.
copy=Falseist nur bei CSR-Sparse-Matrizen wirksam.
- Gibt zurück:
- vectorsSparse-Matrix der Form (n_samples, n_features)
Tf-idf-gewichtete Dokument-Term-Matrix.
Galeriebeispiele#
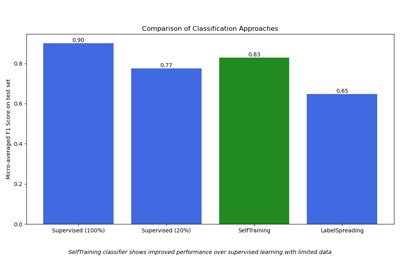
Semi-überwachte Klassifikation auf einem Textdatensatz