KNeighborsClassifier#
- class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, *, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None)[Quelle]#
Klassifikator, der die k-nächste-Nachbarn-Abstimmung implementiert.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- n_neighborsint, Standard=5
Standardanzahl der für
kneighbors-Abfragen zu verwendenden Nachbarn.- weights{‘uniform’, ‘distance’}, aufrufbar oder None, Standard=’uniform’
Gewichtsfunktion, die bei der Vorhersage verwendet wird. Mögliche Werte
‘uniform’ : gleichmäßige Gewichte. Alle Punkte in jedem Nachbarschaftsbereich werden gleich gewichtet.
‘distance’ : Punkte werden nach dem Kehrwert ihrer Entfernung gewichtet. In diesem Fall haben nähere Nachbarn eines Anfragepunkts mehr Einfluss als weiter entfernte Nachbarn.
[aufrufbar] : eine benutzerdefinierte Funktion, die ein Array von Entfernungen akzeptiert und ein Array derselben Form mit den Gewichten zurückgibt.
Siehe das Beispiel mit dem Titel Nearest Neighbors Klassifizierung, das die Auswirkungen des Parameters
weightsauf die Entscheidungsgrenze zeigt.- algorithm{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, Standard=’auto’
Algorithmus zur Berechnung der nächsten Nachbarn
‘ball_tree’ verwendet
BallTree‘kd_tree’ verwendet
KDTree‘brute’ verwendet eine brute-force Suche.
‘auto’ versucht, den am besten geeigneten Algorithmus basierend auf den an die
fit-Methode übergebenen Werten zu bestimmen.
Hinweis: Das Anpassen an dünnbesetzte Eingaben überschreibt die Einstellung dieses Parameters und verwendet brute force.
- leaf_sizeint, Standard=30
Anzahl der Blätter, die an BallTree oder KDTree übergeben werden. Dies kann die Geschwindigkeit des Aufbaus und der Abfrage sowie den benötigten Speicherplatz für den Baum beeinflussen. Der optimale Wert hängt von der Art des Problems ab.
- pfloat, Standard=2
Potenzparameter für die Minkowski-Metrik. Wenn p = 1, ist dies äquivalent zur Verwendung der Manhattan-Distanz (l1) und der Euklidischen Distanz (l2) für p = 2. Für beliebiges p wird die Minkowski-Distanz (l_p) verwendet. Dieser Parameter muss positiv sein.
- metricstr oder aufrufbar, Standard=’minkowski’
Metrik zur Entfernungsberechnung. Standard ist „minkowski“, was bei p = 2 zur Standard-Euklidischen Distanz führt. Siehe die Dokumentation von scipy.spatial.distance und die unter
distance_metricsaufgeführten Metriken für gültige Metrikwerte.Wenn metric “precomputed” ist, wird davon ausgegangen, dass X eine Distanzmatrix ist und während des Anlernens quadratisch sein muss. X kann ein dünnbesetzter Graph sein, in diesem Fall können nur “nonzero” Elemente als Nachbarn betrachtet werden.
Wenn metric eine aufrufbare Funktion ist, nimmt sie zwei Arrays entgegen, die 1D-Vektoren darstellen, und muss einen Wert zurückgeben, der die Entfernung zwischen diesen Vektoren angibt. Dies funktioniert für Scipys Metriken, ist aber weniger effizient als die Übergabe des Metriknamens als String.
- metric_paramsdict, Standard=None
Zusätzliche Schlüsselwortargumente für die Metrikfunktion.
- n_jobsint, default=None
Die Anzahl der parallelen Jobs, die für die Nachbarschaftssuche ausgeführt werden.
Nonebedeutet 1, es sei denn, es befindet sich in einemjoblib.parallel_backend-Kontext.-1bedeutet die Verwendung aller Prozessoren. Siehe Glossar für weitere Details. Beeinflusst nicht diefit-Methode.
- Attribute:
- classes_array von Form (n_classes,)
Bekannte Klassenlabels des Klassifikators
- effective_metric_str oder aufrufbar
Die verwendete Distanzmetrik. Sie ist identisch mit dem Parameter
metricoder ein Synonym davon, z. B. ‘euclidean’, wenn der Parametermetricauf ‘minkowski’ und der Parameterpauf 2 gesetzt ist.- effective_metric_params_dict
Zusätzliche Schlüsselwortargumente für die Metrikfunktion. Für die meisten Metriken ist dies dasselbe wie der Parameter
metric_params, kann aber auch den Wert des Parameterspenthalten, wenn das Attributeffective_metric_auf ‘minkowski’ gesetzt ist.- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
- n_samples_fit_int
Anzahl der Samples in den angepassten Daten.
- outputs_2d_bool
False, wenn die Form von
y(n_samples, ) oder (n_samples, 1) während des Anlernens ist, ansonsten True.
Siehe auch
RadiusNeighborsClassifierKlassifikator basierend auf Nachbarn innerhalb eines festen Radius.
KNeighborsRegressorRegression basierend auf k-nächsten Nachbarn.
RadiusNeighborsRegressorRegression basierend auf Nachbarn innerhalb eines festen Radius.
NearestNeighborsUnüberwachter Lerner zur Implementierung von Nachbarschaftssuchen.
Anmerkungen
Siehe Nearest Neighbors in der Online-Dokumentation für eine Diskussion der Wahl von
algorithmundleaf_size.Warnung
Bezüglich der Nearest Neighbors-Algorithmen hängt das Ergebnis, wenn zwei Nachbarn, Nachbar
k+1undk, identische Entfernungen, aber unterschiedliche Labels haben, von der Reihenfolge der Trainingsdaten ab.https://en.wikipedia.org/wiki/K-nearest_neighbor_algorithm
Beispiele
>>> X = [[0], [1], [2], [3]] >>> y = [0, 0, 1, 1] >>> from sklearn.neighbors import KNeighborsClassifier >>> neigh = KNeighborsClassifier(n_neighbors=3) >>> neigh.fit(X, y) KNeighborsClassifier(...) >>> print(neigh.predict([[1.1]])) [0] >>> print(neigh.predict_proba([[0.9]])) [[0.666 0.333]]
- fit(X, y)[Quelle]#
Passt den k-nächsten Nachbarn-Klassifikator aus dem Trainingsdatensatz an.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features) oder (n_samples, n_samples), wenn metric=’precomputed’
Trainingsdaten.
- y{array-like, sparse matrix} der Form (n_samples,) oder (n_samples, n_outputs)
Zielwerte.
- Gibt zurück:
- selfKNeighborsClassifier
Der angepasste k-nächste Nachbarn-Klassifikator.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- kneighbors(X=None, n_neighbors=None, return_distance=True)[Quelle]#
Finde die K-Nachbarn eines Punktes.
Gibt Indizes von und Entfernungen zu den Nachbarn jedes Punktes zurück.
- Parameter:
- X{array-like, sparse matrix}, Form (n_queries, n_features) oder (n_queries, n_indexed), wenn metric == ‘precomputed’, Standard=None
Der Anfragepunkt oder die Anfragepunkte. Wenn nicht angegeben, werden die Nachbarn jedes indizierten Punktes zurückgegeben. In diesem Fall wird der Anfragepunkt nicht als sein eigener Nachbar betrachtet.
- n_neighborsint, Standard=None
Anzahl der für jede Stichprobe erforderlichen Nachbarn. Der Standardwert ist der Wert, der an den Konstruktor übergeben wurde.
- return_distancebool, Standard=True
Gibt zurück, ob die Entfernungen zurückgegeben werden sollen.
- Gibt zurück:
- neigh_distndarray der Form (n_queries, n_neighbors)
Array, das die Längen zu den Punkten darstellt, nur vorhanden, wenn return_distance=True.
- neigh_indndarray der Form (n_queries, n_neighbors)
Indizes der nächsten Punkte in der Populationsmatrix.
Beispiele
Im folgenden Beispiel konstruieren wir eine NearestNeighbors-Klasse aus einem Array, das unser Datensatz repräsentiert, und fragen, wer der nächste Punkt zu [1,1,1] ist.
>>> samples = [[0., 0., 0.], [0., .5, 0.], [1., 1., .5]] >>> from sklearn.neighbors import NearestNeighbors >>> neigh = NearestNeighbors(n_neighbors=1) >>> neigh.fit(samples) NearestNeighbors(n_neighbors=1) >>> print(neigh.kneighbors([[1., 1., 1.]])) (array([[0.5]]), array([[2]]))
Wie Sie sehen können, gibt es [[0.5]] und [[2]] zurück, was bedeutet, dass das Element in der Entfernung 0.5 liegt und das dritte Element von samples ist (Indizes beginnen bei 0). Sie können auch mehrere Punkte abfragen.
>>> X = [[0., 1., 0.], [1., 0., 1.]] >>> neigh.kneighbors(X, return_distance=False) array([[1], [2]]...)
- kneighbors_graph(X=None, n_neighbors=None, mode='connectivity')[Quelle]#
Berechnet den (gewichteten) Graphen von k-Nachbarn für Punkte in X.
- Parameter:
- X{array-like, sparse matrix} der Form (n_queries, n_features) oder (n_queries, n_indexed), wenn metric == ‘precomputed’, Standard=None
Der Anfragepunkt oder die Anfragepunkte. Wenn nicht angegeben, werden die Nachbarn jedes indizierten Punktes zurückgegeben. In diesem Fall wird der Anfragepunkt nicht als sein eigener Nachbar betrachtet. Für
metric='precomputed'sollte die Form (n_queries, n_indexed) sein. Andernfalls sollte die Form (n_queries, n_features) sein.- n_neighborsint, Standard=None
Anzahl der Nachbarn für jede Stichprobe. Der Standardwert ist der Wert, der an den Konstruktor übergeben wurde.
- mode{‘connectivity’, ‘distance’}, Standard=’connectivity’
Typ der zurückgegebenen Matrix: ‘connectivity’ gibt die Konnektivitätsmatrix mit Einsen und Nullen zurück, bei ‘distance’ sind die Kanten die Entfernungen zwischen den Punkten; die Art der Distanz hängt vom ausgewählten Metrikparameter in der NearestNeighbors-Klasse ab.
- Gibt zurück:
- Asparse-matrix der Form (n_queries, n_samples_fit)
n_samples_fitist die Anzahl der Samples in den angepassten Daten.A[i, j]gibt das Gewicht der Kante an, dieimitjverbindet. Die Matrix hat das CSR-Format.
Siehe auch
NearestNeighbors.radius_neighbors_graphBerechnet den (gewichteten) Graphen von Nachbarn für Punkte in X.
Beispiele
>>> X = [[0], [3], [1]] >>> from sklearn.neighbors import NearestNeighbors >>> neigh = NearestNeighbors(n_neighbors=2) >>> neigh.fit(X) NearestNeighbors(n_neighbors=2) >>> A = neigh.kneighbors_graph(X) >>> A.toarray() array([[1., 0., 1.], [0., 1., 1.], [1., 0., 1.]])
- predict(X)[Quelle]#
Prognostiziert die Klassenlabels für die bereitgestellten Daten.
- Parameter:
- X{array-like, sparse matrix} der Form (n_queries, n_features), oder (n_queries, n_indexed), wenn metric == ‘precomputed’, oder None
Teststichproben. Wenn
None, werden Vorhersagen für alle indizierten Punkte zurückgegeben; in diesem Fall werden Punkte nicht als ihre eigenen Nachbarn betrachtet.
- Gibt zurück:
- yndarray der Form (n_queries,) oder (n_queries, n_outputs)
Klassenlabels für jede Datenstichprobe.
- predict_proba(X)[Quelle]#
Gibt Wahrscheinlichkeitsschätzungen für die Testdaten X zurück.
- Parameter:
- X{array-like, sparse matrix} der Form (n_queries, n_features), oder (n_queries, n_indexed), wenn metric == ‘precomputed’, oder None
Teststichproben. Wenn
None, werden Vorhersagen für alle indizierten Punkte zurückgegeben; in diesem Fall werden Punkte nicht als ihre eigenen Nachbarn betrachtet.
- Gibt zurück:
- pndarray der Form (n_queries, n_classes) oder eine Liste von n_outputs solcher Arrays, wenn n_outputs > 1.
Die Klassenwahrscheinlichkeiten der Eingabestichproben. Klassen sind nach lexikographischer Reihenfolge geordnet.
- score(X, y, sample_weight=None)[Quelle]#
Gibt die durchschnittliche Genauigkeit auf den gegebenen Testdaten und Labels zurück.
Bei der Multi-Label-Klassifizierung ist dies die Subset-Genauigkeit, eine strenge Metrik, da für jede Stichprobe verlangt wird, dass jede Label-Menge korrekt vorhergesagt wird.
- Parameter:
- Xarray-like der Form (n_samples, n_features) oder None
Teststichproben. Wenn
None, werden Vorhersagen für alle indizierten Punkte verwendet; in diesem Fall werden Punkte nicht als ihre eigenen Nachbarn betrachtet. Das bedeutet, dassknn.fit(X, y).score(None, y)implizit ein Leave-one-out-Kreuzvalidierungsverfahren durchführt undcross_val_score(knn, X, y, cv=LeaveOneOut())entspricht, aber typischerweise viel schneller ist.- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Bezeichnungen für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
Mittlere Genauigkeit von
self.predict(X)in Bezug aufy.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') KNeighborsClassifier[Quelle]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
Galeriebeispiele#

Vergleich von Nächsten Nachbarn mit und ohne Neighborhood Components Analysis
Dimensionsreduktion mit Neighborhood Components Analysis

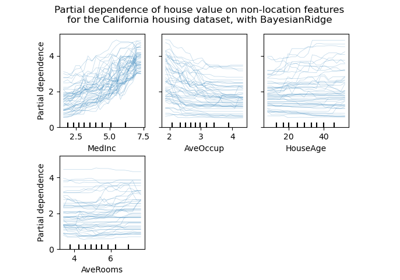
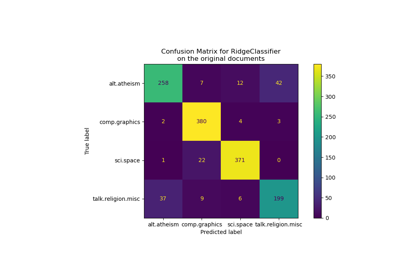
Klassifikation von Textdokumenten mit spärlichen Merkmalen