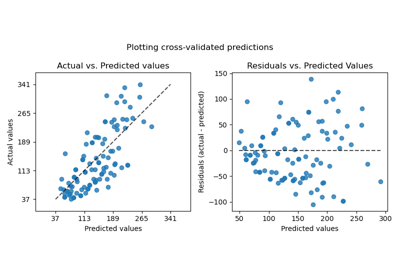
PredictionErrorDisplay#
- class sklearn.metrics.PredictionErrorDisplay(*, y_true, y_pred)[Quelle]#
Visualisierung des Vorhersagefehlers eines Regressionsmodells.
Dieses Werkzeug kann „Residuen vs. Vorhersagen“ oder „Tatsächlich vs. Vorhersagen“ mithilfe von Streudiagrammen anzeigen, um das Verhalten eines Regressors qualitativ zu bewerten, vorzugsweise an gehaltenen Datenpunkten.
Einzelheiten finden Sie in den Docstrings von
from_estimatoroderfrom_predictionszum Erstellen eines Visualisierers. Alle Parameter werden als Attribute gespeichert.Allgemeine Informationen zu den Visualisierungswerkzeugen von
scikit-learnfinden Sie im Visualisierungsleitfaden. Details zur Interpretation dieser Diagramme finden Sie im Modellbewertungsleitfaden.Hinzugefügt in Version 1.2.
- Parameter:
- y_truendarray mit Form (n_samples,)
Wahre Werte.
- y_predndarray von Form (n_samples,)
Vorhersagewerte.
- Attribute:
- line_matplotlib Artist
Optimale Linie, die
y_true == y_preddarstellt. Daher ist es eine diagonale Linie fürkind="predictions"und eine horizontale Linie fürkind="residuals".- errors_lines_matplotlib Artist oder None
Residuenlinien. Wenn
with_errors=False, wird es aufNonegesetzt.- scatter_matplotlib Artist
Streudatenpunkte.
- ax_matplotlib Axes
Achsen mit den verschiedenen matplotlib-Achsen.
- figure_matplotlib Figure
Figur, die den Streuplot und die Linien enthält.
Siehe auch
PredictionErrorDisplay.from_estimatorVorhersagefehlervisualisierung gegeben einen Schätzer und einige Daten.
PredictionErrorDisplay.from_predictionsVorhersagefehlervisualisierung gegeben die wahren und vorhergesagten Ziele.
Beispiele
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import load_diabetes >>> from sklearn.linear_model import Ridge >>> from sklearn.metrics import PredictionErrorDisplay >>> X, y = load_diabetes(return_X_y=True) >>> ridge = Ridge().fit(X, y) >>> y_pred = ridge.predict(X) >>> display = PredictionErrorDisplay(y_true=y, y_pred=y_pred) >>> display.plot() <...> >>> plt.show()
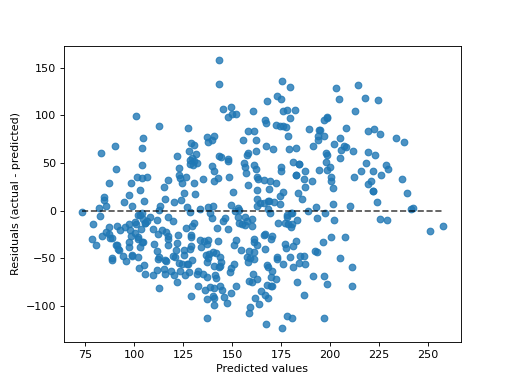
- classmethod from_estimator(estimator, X, y, *, kind='residual_vs_predicted', subsample=1000, random_state=None, ax=None, scatter_kwargs=None, line_kwargs=None)[Quelle]#
Zeichnen Sie den Vorhersagefehler gegeben einen Regressor und einige Daten.
Allgemeine Informationen zu den Visualisierungswerkzeugen von
scikit-learnfinden Sie im Visualisierungsleitfaden. Details zur Interpretation dieser Diagramme finden Sie im Modellbewertungsleitfaden.Hinzugefügt in Version 1.2.
- Parameter:
- estimatorSchätzer-Instanz
Angepasster Regressor oder eine angepasste
Pipeline, bei der der letzte Schätzer ein Regressor ist.- X{array-like, sparse matrix} der Form (n_samples, n_features)
Eingabewerte.
- yarray-like von Form (n_samples,)
Zielwerte.
- kind{„actual_vs_predicted“, „residual_vs_predicted“}, Standardwert=„residual_vs_predicted“
Die Art des zu zeichnenden Diagramms.
„actual_vs_predicted“ zeichnet die beobachteten Werte (y-Achse) gegen die vorhergesagten Werte (x-Achse).
„residual_vs_predicted“ zeichnet die Residuen, d. h. die Differenz zwischen beobachteten und vorhergesagten Werten, (y-Achse) gegen die vorhergesagten Werte (x-Achse).
- subsamplefloat, int oder None, Standardwert=1_000
Stichprobennahme der anzuzeigenden Stichproben im Streudiagramm. Wenn
float, sollte es zwischen 0 und 1 liegen und den Anteil des ursprünglichen Datensatzes darstellen. Wennint, repräsentiert es die Anzahl der im Streudiagramm angezeigten Stichproben. WennNone, wird keine Stichprobennahme angewendet. Standardmäßig werden 1000 oder weniger Stichproben angezeigt.- random_stateint oder RandomState, Standardwert=None
Steuert die Zufälligkeit, wenn
subsamplenichtNoneist. Einzelheiten finden Sie unter Glossar.- axmatplotlib axes, Standardwert=None
Axes-Objekt, auf dem geplottet werden soll. Wenn
None, wird eine neue Figur und Achse erstellt.- scatter_kwargsdict, Standardwert=None
Wörterbuch mit Schlüsselwörtern, die an den
matplotlib.pyplot.scatter-Aufruf übergeben werden.- line_kwargsdict, Standardwert=None
Wörterbuch mit Schlüsselwörtern, die an den
matplotlib.pyplot.plot-Aufruf übergeben werden, um die optimale Linie zu zeichnen.
- Gibt zurück:
- display
PredictionErrorDisplay Objekt, das die berechneten Werte speichert.
- display
Siehe auch
PredictionErrorDisplayVorhersagefehlervisualisierung für Regression.
PredictionErrorDisplay.from_predictionsVorhersagefehlervisualisierung gegeben die wahren und vorhergesagten Ziele.
Beispiele
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import load_diabetes >>> from sklearn.linear_model import Ridge >>> from sklearn.metrics import PredictionErrorDisplay >>> X, y = load_diabetes(return_X_y=True) >>> ridge = Ridge().fit(X, y) >>> disp = PredictionErrorDisplay.from_estimator(ridge, X, y) >>> plt.show()
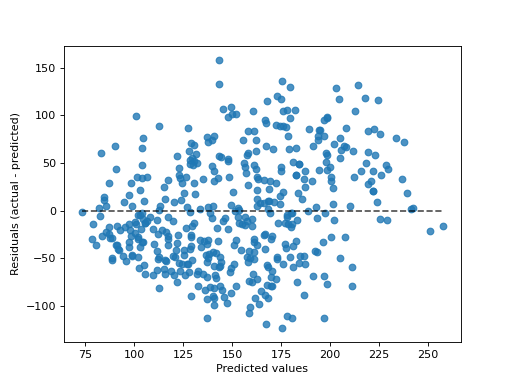
- classmethod from_predictions(y_true, y_pred, *, kind='residual_vs_predicted', subsample=1000, random_state=None, ax=None, scatter_kwargs=None, line_kwargs=None)[Quelle]#
Zeichnen Sie den Vorhersagefehler gegeben die wahren und vorhergesagten Ziele.
Allgemeine Informationen zu den Visualisierungswerkzeugen von
scikit-learnfinden Sie im Visualisierungsleitfaden. Details zur Interpretation dieser Diagramme finden Sie im Modellbewertungsleitfaden.Hinzugefügt in Version 1.2.
- Parameter:
- y_truearray-ähnlich mit Form (n_samples,)
Wahre Zielwerte.
- y_predarray-ähnlich mit Form (n_samples,)
Vorhergesagte Zielwerte.
- kind{„actual_vs_predicted“, „residual_vs_predicted“}, Standardwert=„residual_vs_predicted“
Die Art des zu zeichnenden Diagramms.
„actual_vs_predicted“ zeichnet die beobachteten Werte (y-Achse) gegen die vorhergesagten Werte (x-Achse).
„residual_vs_predicted“ zeichnet die Residuen, d. h. die Differenz zwischen beobachteten und vorhergesagten Werten, (y-Achse) gegen die vorhergesagten Werte (x-Achse).
- subsamplefloat, int oder None, Standardwert=1_000
Stichprobennahme der anzuzeigenden Stichproben im Streudiagramm. Wenn
float, sollte es zwischen 0 und 1 liegen und den Anteil des ursprünglichen Datensatzes darstellen. Wennint, repräsentiert es die Anzahl der im Streudiagramm angezeigten Stichproben. WennNone, wird keine Stichprobennahme angewendet. Standardmäßig werden 1000 oder weniger Stichproben angezeigt.- random_stateint oder RandomState, Standardwert=None
Steuert die Zufälligkeit, wenn
subsamplenichtNoneist. Einzelheiten finden Sie unter Glossar.- axmatplotlib axes, Standardwert=None
Axes-Objekt, auf dem geplottet werden soll. Wenn
None, wird eine neue Figur und Achse erstellt.- scatter_kwargsdict, Standardwert=None
Wörterbuch mit Schlüsselwörtern, die an den
matplotlib.pyplot.scatter-Aufruf übergeben werden.- line_kwargsdict, Standardwert=None
Wörterbuch mit Schlüsselwörtern, die an den
matplotlib.pyplot.plot-Aufruf übergeben werden, um die optimale Linie zu zeichnen.
- Gibt zurück:
- display
PredictionErrorDisplay Objekt, das die berechneten Werte speichert.
- display
Siehe auch
PredictionErrorDisplayVorhersagefehlervisualisierung für Regression.
PredictionErrorDisplay.from_estimatorVorhersagefehlervisualisierung gegeben einen Schätzer und einige Daten.
Beispiele
>>> import matplotlib.pyplot as plt >>> from sklearn.datasets import load_diabetes >>> from sklearn.linear_model import Ridge >>> from sklearn.metrics import PredictionErrorDisplay >>> X, y = load_diabetes(return_X_y=True) >>> ridge = Ridge().fit(X, y) >>> y_pred = ridge.predict(X) >>> disp = PredictionErrorDisplay.from_predictions(y_true=y, y_pred=y_pred) >>> plt.show()
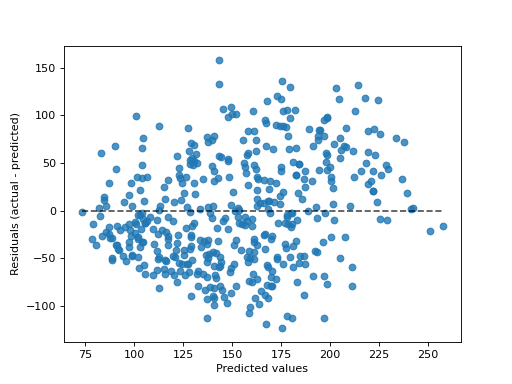
- plot(ax=None, *, kind='residual_vs_predicted', scatter_kwargs=None, line_kwargs=None)[Quelle]#
Visualisierung plotten.
Zusätzliche Schlüsselwortargumente werden an
plotvon matplotlib übergeben.- Parameter:
- axmatplotlib axes, Standardwert=None
Axes-Objekt, auf dem geplottet werden soll. Wenn
None, wird eine neue Figur und Achse erstellt.- kind{„actual_vs_predicted“, „residual_vs_predicted“}, Standardwert=„residual_vs_predicted“
Die Art des zu zeichnenden Diagramms.
„actual_vs_predicted“ zeichnet die beobachteten Werte (y-Achse) gegen die vorhergesagten Werte (x-Achse).
„residual_vs_predicted“ zeichnet die Residuen, d. h. die Differenz zwischen beobachteten und vorhergesagten Werten, (y-Achse) gegen die vorhergesagten Werte (x-Achse).
- scatter_kwargsdict, Standardwert=None
Wörterbuch mit Schlüsselwörtern, die an den
matplotlib.pyplot.scatter-Aufruf übergeben werden.- line_kwargsdict, Standardwert=None
Wörterbuch mit Schlüsselwörtern, die an den
matplotlib.pyplot.plot-Aufruf übergeben werden, um die optimale Linie zu zeichnen.
- Gibt zurück:
- display
PredictionErrorDisplay Objekt, das berechnete Werte speichert.
- display
Galeriebeispiele#
Auswirkung der Transformation der Ziele in einem Regressionsmodell
Häufige Fallstricke bei der Interpretation von Koeffizienten linearer Modelle