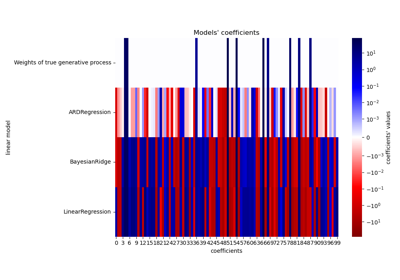
ARDRegression#
- class sklearn.linear_model.ARDRegression(*, max_iter=300, tol=0.001, alpha_1=1e-06, alpha_2=1e-06, lambda_1=1e-06, lambda_2=1e-06, compute_score=False, threshold_lambda=10000.0, fit_intercept=True, copy_X=True, verbose=False)[Quelle]#
Bayes'sche ARD-Regression.
Trainiert die Gewichte eines Regressionsmodells mit einem ARD-Prior. Die Gewichte des Regressionsmodells werden als Gauß-Verteilungen angenommen. Schätzt auch die Parameter lambda (Präzision der Verteilungen der Gewichte) und alpha (Präzision der Verteilung des Rauschens). Die Schätzung erfolgt durch ein iteratives Verfahren (Evidenzmaximierung).
Mehr dazu im Benutzerhandbuch.
- Parameter:
- max_iterint, Standard=300
Maximale Anzahl von Iterationen.
Geändert in Version 1.3.
- tolfloat, Standard=1e-3
Stoppt den Algorithmus, wenn w konvergiert ist.
- alpha_1float, default=1e-6
Hyperparameter: Formparameter für die Gamma-Verteilungs-Prior über den alpha-Parameter.
- alpha_2float, default=1e-6
Hyperparameter: Skalenparameter (Rate-Parameter) für die Gamma-Verteilungs-Prior über den alpha-Parameter.
- lambda_1float, default=1e-6
Hyperparameter: Formparameter für die Gamma-Verteilungs-Prior über den lambda-Parameter.
- lambda_2float, default=1e-6
Hyperparameter: Skalenparameter (Rate-Parameter) für die Gamma-Verteilungs-Prior über den lambda-Parameter.
- compute_scorebool, default=False
Wenn True, wird die Zielfunktion bei jedem Schritt des Modells berechnet.
- threshold_lambdafloat, default=10 000
Schwellenwert zum Entfernen (Pruning) von Gewichten mit hoher Präzision aus der Berechnung.
- fit_interceptbool, Standardwert=True
Ob für dieses Modell ein Achsenabschnitt berechnet werden soll. Wenn auf False gesetzt, wird kein Achsenabschnitt in Berechnungen verwendet (d.h. die Daten werden als zentriert erwartet).
- copy_Xbool, Standardwert=True
Wenn True, wird X kopiert; andernfalls kann es überschrieben werden.
- verbosebool, default=False
Verbose-Modus beim Anpassen des Modells.
- Attribute:
- coef_array-ähnlich der Form (n_features,)
Koeffizienten des Regressionsmodells (Mittelwert der Verteilung)
- alpha_float
geschätzte Präzision des Rauschens.
- lambda_array-like von Shape (n_features,)
geschätzte Präzisionen der Gewichte.
- sigma_array-like von Shape (n_features, n_features)
geschätzte Varianz-Kovarianz-Matrix der Gewichte
- scores_float
falls berechnet, Wert der Zielfunktion (zu maximieren)
- n_iter_int
Die tatsächliche Anzahl der Iterationen, um das Abbruchkriterium zu erreichen.
Hinzugefügt in Version 1.3.
- intercept_float
Unabhängiger Term in der Entscheidungsfunktion. Auf 0.0 gesetzt, wenn
fit_intercept = False.- X_offset_float
Wenn
fit_intercept=True, wird der Offset subtrahiert, um die Daten auf einen Mittelwert von Null zu zentrieren. Andernfalls auf np.zeros(n_features) gesetzt.- X_scale_float
Auf np.ones(n_features) gesetzt.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
Siehe auch
BayesianRidgeBayes'sche Ridge-Regression.
Referenzen
D. J. C. MacKay, Bayesian nonlinear modeling for the prediction competition, ASHRAE Transactions, 1994.
R. Salakhutdinov, Lecture notes on Statistical Machine Learning, http://www.utstat.toronto.edu/~rsalakhu/sta4273/notes/Lecture2.pdf#page=15 Ihr beta ist unser
self.alpha_Ihr alpha ist unserself.lambda_ARD unterscheidet sich geringfügig von den Folien: Nur Dimensionen/Merkmale, für dieself.lambda_ < self.threshold_lambdagilt, werden beibehalten und die restlichen verworfen.Beispiele
>>> from sklearn import linear_model >>> clf = linear_model.ARDRegression() >>> clf.fit([[0,0], [1, 1], [2, 2]], [0, 1, 2]) ARDRegression() >>> clf.predict([[1, 1]]) array([1.])
Vergleich linearer Bayes'scher Regressoren demonstriert ARD Regression.
L1-basierte Modelle für Sparse Signale zeigt ARD Regression neben Lasso und Elastic-Net für sparse, korrelierte Signale, in Anwesenheit von Rauschen.
- fit(X, y)[Quelle]#
Trainiert das Modell entsprechend den gegebenen Trainingsdaten und Parametern.
Iteratives Verfahren zur Maximierung der Evidenz
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Trainingsvektor, wobei
n_samplesdie Anzahl der Stichproben undn_featuresdie Anzahl der Merkmale ist.- yarray-like von Form (n_samples,)
Zielwerte (ganzzahlig). Werden bei Bedarf in den Datentyp von X umgewandelt.
- Gibt zurück:
- selfobject
Angepasster Schätzer.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X, return_std=False)[Quelle]#
Vorhersage mit dem linearen Modell.
Zusätzlich zum Mittelwert der prädiktiven Verteilung kann auch dessen Standardabweichung zurückgegeben werden.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features)
Stichproben.
- return_stdbool, Standard=False
Ob die Standardabweichung der Posterior-Vorhersage zurückgegeben werden soll.
- Gibt zurück:
- y_meanarray-like von Shape (n_samples,)
Mittelwert der prädiktiven Verteilung von Abfragepunkten.
- y_stdarray-like von Shape (n_samples,)
Standardabweichung der Vorhersageverteilung von Abfragepunkten.
- score(X, y, sample_weight=None)[Quelle]#
Gibt den Bestimmtheitskoeffizienten auf Testdaten zurück.
Der Bestimmungskoeffizient, \(R^2\), ist definiert als \((1 - \frac{u}{v})\), wobei \(u\) die Summe der quadrierten Residuen ist
((y_true - y_pred)** 2).sum()und \(v\) die totale Summe der Quadrate ist((y_true - y_true.mean()) ** 2).sum(). Der beste mögliche Score ist 1,0 und er kann negativ sein (da das Modell beliebig schlechter sein kann). Ein konstantes Modell, das immer den erwarteten Wert vonyvorhersagt, ohne die Eingabemerkmale zu berücksichtigen, würde einen \(R^2\)-Score von 0,0 erhalten.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben. Für einige Schätzer kann dies eine vorab berechnete Kernelmatrix oder eine Liste von generischen Objekten sein, stattdessen mit der Form
(n_samples, n_samples_fitted), wobein_samples_fitteddie Anzahl der für die Anpassung des Schätzers verwendeten Stichproben ist.- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Werte für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
\(R^2\) von
self.predict(X)bezogen aufy.
Anmerkungen
Der \(R^2\)-Score, der beim Aufruf von
scorefür einen Regressor verwendet wird, verwendetmultioutput='uniform_average'ab Version 0.23, um konsistent mit dem Standardwert vonr2_scorezu bleiben. Dies beeinflusst diescore-Methode aller Multioutput-Regressoren (mit Ausnahme vonMultiOutputRegressor).
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_predict_request(*, return_std: bool | None | str = '$UNCHANGED$') ARDRegression[Quelle]#
Konfiguriert, ob Metadaten für die
predict-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anpredictweitergegeben. Die Anforderung wird ignoriert, wenn keine Metadaten bereitgestellt werden.False: Metadaten werden nicht angefordert und die Meta-Schätzung übergibt sie nicht anpredict.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- return_stdstr, True, False oder None, Standard=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
return_stdinpredict.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') ARDRegression[Quelle]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.