AgglomerativeClustering#
- class sklearn.cluster.AgglomerativeClustering(n_clusters=2, *, metric='euclidean', memory=None, connectivity=None, compute_full_tree='auto', linkage='ward', distance_threshold=None, compute_distances=False)[Quelle]#
Agglomeratives Clustering.
Fügt Paare von Clustern von Stichprobendaten rekursiv zusammen; verwendet die Linkage-Distanz.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- n_clustersint oder None, Standard=2
Die Anzahl der zu findenden Cluster. Muss
Nonesein, wenndistance_thresholdnichtNoneist.- metricstr oder aufrufbar, Standard=”euclidean”
Metrik zur Berechnung der Verknüpfung. Kann „euclidean“, „l1“, „l2“, „manhattan“, „cosine“ oder „precomputed“ sein. Wenn die Verknüpfung „ward“ ist, wird nur „euclidean“ akzeptiert. Wenn „precomputed“, wird eine Distanzmatrix als Eingabe für die fit-Methode benötigt. Wenn connectivity None ist, ist linkage „single“ und affinity ist nicht „precomputed“, jede gültige paarweise Distanzmetrik kann zugewiesen werden.
Ein Beispiel für agglomeratives Clustering mit verschiedenen Metriken finden Sie unter Agglomeratives Clustering mit verschiedenen Metriken.
Hinzugefügt in Version 1.2.
- memoryString oder Objekt mit dem joblib.Memory-Interface, Standard=None
Wird verwendet, um die Ausgabe der Berechnung des Baumes zu cachen. Standardmäßig erfolgt kein Caching. Wenn ein String angegeben wird, ist dies der Pfad zum Cache-Verzeichnis.
- connectivityarray-ähnlich, dünne Matrix oder aufrufbar, Standard=None
Konnektivitätsmatrix. Definiert für jede Stichprobe die benachbarten Stichproben gemäß einer bestimmten Datenstruktur. Dies kann eine Konnektivitätsmatrix selbst sein oder eine aufrufbare Funktion, die die Daten in eine Konnektivitätsmatrix umwandelt, wie sie z. B. von
kneighbors_graphabgeleitet wird. Standard istNone, d. h. der hierarchische Clustering-Algorithmus ist unstrukturiert.Ein Beispiel für eine Konnektivitätsmatrix mit
kneighbors_graphfinden Sie unter Hierarchisches Clustering mit und ohne Struktur.- compute_full_tree„auto“ oder bool, Standard=”auto”
Beendet den Aufbau des Baumes bei
n_clustersfrühzeitig. Dies ist nützlich, um die Rechenzeit zu verkürzen, wenn die Anzahl der Cluster im Vergleich zur Anzahl der Stichproben nicht klein ist. Diese Option ist nur nützlich, wenn eine Konnektivitätsmatrix angegeben wird. Beachten Sie auch, dass es bei variierender Clusteranzahl und Verwendung von Caching vorteilhaft sein kann, den vollständigen Baum zu berechnen. MussTruesein, wenndistance_thresholdnichtNoneist. Standardmäßig istcompute_full_tree„auto“, wasTrueentspricht, wenndistance_thresholdnichtNoneist odern_clusterskleiner als das Maximum von 100 oder0.02 * n_samplesist. Andernfalls entspricht „auto“False.- linkage{‘ward’, ‘complete’, ‘average’, ‘single’}, Standard=’ward’
Welches Verknüpfungskriterium verwendet werden soll. Das Verknüpfungskriterium bestimmt, welche Distanz zwischen Beobachtungsgruppen verwendet wird. Der Algorithmus fügt die Clusterpaare zusammen, die dieses Kriterium minimieren.
„ward“ minimiert die Varianz der zusammengeführten Cluster.
„average“ verwendet den Durchschnitt der Distanzen jeder Beobachtung der beiden Gruppen.
„complete“ oder „maximum“ Verknüpfung verwendet die maximalen Distanzen zwischen allen Beobachtungen der beiden Gruppen.
„single“ verwendet das Minimum der Distanzen zwischen allen Beobachtungen der beiden Gruppen.
Hinzugefügt in Version 0.20: Die Option „single“ wurde hinzugefügt
Beispiele, die verschiedene
linkage-Kriterien vergleichen, finden Sie unter Vergleich verschiedener hierarchischer Verknüpfungsmethoden auf Beispiel-Datensätzen.- distance_thresholdfloat, Standard=None
Die Verknüpfungsdistanzschwelle, bei oder über der Cluster nicht mehr zusammengeführt werden. Wenn nicht
None, mussn_clustersNonesein undcompute_full_treemussTruesein.Hinzugefügt in Version 0.21.
- compute_distancesbool, Standard=False
Berechnet Distanzen zwischen Clustern, auch wenn
distance_thresholdnicht verwendet wird. Dies kann für die Visualisierung von Dendrogrammen verwendet werden, verursacht jedoch einen Rechen- und Speicheraufwand.Hinzugefügt in Version 0.24.
Ein Beispiel für die Visualisierung von Dendrogrammen finden Sie unter Plot Hierarchisches Clustering Dendrogramm.
- Attribute:
- n_clusters_int
Die vom Algorithmus gefundene Anzahl von Clustern. Wenn
distance_threshold=None, ist sie gleich dem angegebenenn_clusters.- labels_ndarray der Form (n_samples)
Cluster-Labels für jeden Punkt.
- n_leaves_int
Anzahl der Blätter im hierarchischen Baum.
- n_connected_components_int
Die geschätzte Anzahl von verbundenen Komponenten im Graphen.
Hinzugefügt in Version 0.21:
n_connected_components_wurde hinzugefügt, umn_components_zu ersetzen.- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
- children_array-ähnlich der Form (n_samples-1, 2)
Die Kinder jedes Nicht-Blatt-Knotens. Werte kleiner als
n_samplesentsprechen den Blättern des Baumes, die die ursprünglichen Stichproben sind. Ein Knotenigrößer oder gleichn_samplesist ein Nicht-Blatt-Knoten und hat die Kinderchildren_[i - n_samples]. Alternativ werden bei der i-ten Iteration children[i][0] und children[i][1] zusammengeführt, um den Knotenn_samples + izu bilden.- distances_array-ähnlich der Form (n_nodes-1,)
Distanzen zwischen Knoten an der entsprechenden Stelle in
children_. Nur berechnet, wenndistance_thresholdverwendet wird odercompute_distancesaufTruegesetzt ist.
Siehe auch
FeatureAgglomerationAgglomeratives Clustering, aber für Merkmale anstelle von Stichproben.
ward_treeHierarchisches Clustering mit Ward-Verknüpfung.
Beispiele
>>> from sklearn.cluster import AgglomerativeClustering >>> import numpy as np >>> X = np.array([[1, 2], [1, 4], [1, 0], ... [4, 2], [4, 4], [4, 0]]) >>> clustering = AgglomerativeClustering().fit(X) >>> clustering AgglomerativeClustering() >>> clustering.labels_ array([1, 1, 1, 0, 0, 0])
Ein Vergleich von Agglomerativem Clustering mit anderen Clustering-Algorithmen finden Sie unter Vergleich verschiedener Clustering-Algorithmen auf Beispiel-Datensätzen
- fit(X, y=None)[Quelle]#
Fügt das hierarchische Clustering aus Merkmalen oder einer Distanzmatrix an.
- Parameter:
- Xarray-ähnlich, Form (n_samples, n_features) oder (n_samples, n_samples)
Trainingsinstanzen zum Clustern oder Distanzen zwischen Instanzen, wenn
metric='precomputed'.- yIgnoriert
Nicht verwendet, hier zur API-Konsistenz durch Konvention vorhanden.
- Gibt zurück:
- selfobject
Gibt die angepasste Instanz zurück.
- fit_predict(X, y=None)[Quelle]#
Passt die Ergebnisse der Clusterzuweisung für jede Stichprobe an und gibt sie zurück.
Zusätzlich zum Anpassen gibt diese Methode auch das Ergebnis der Clusterzuweisung für jede Stichprobe im Trainingssatz zurück.
- Parameter:
- Xarray-ähnlich der Form (n_samples, n_features) oder (n_samples, n_samples)
Trainingsinstanzen zum Clustern oder Distanzen zwischen Instanzen, wenn
affinity='precomputed'.- yIgnoriert
Nicht verwendet, hier zur API-Konsistenz durch Konvention vorhanden.
- Gibt zurück:
- labelsndarray der Form (n_samples,)
Cluster-Labels.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
Galeriebeispiele#
Agglomeratives Clustering mit verschiedenen Metriken
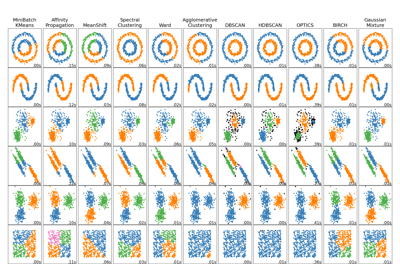
Vergleich verschiedener Clustering-Algorithmen auf Toy-Datensätzen

Eine Demo des strukturierten Ward Hierarchischen Clusterings auf einem Bild von Münzen
Verschiedenes Agglomeratives Clustering auf einer 2D-Einbettung von Ziffern
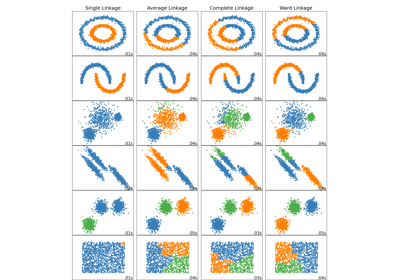
Vergleich verschiedener hierarchischer Linkage-Methoden auf Toy-Datensätzen