Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Induktives Clustering#
Clustering kann teuer sein, besonders wenn unser Datensatz Millionen von Datenpunkten enthält. Viele Clustering-Algorithmen sind nicht induktiv und können daher nicht direkt auf neue Datenproben angewendet werden, ohne das Clustering neu zu berechnen, was unhandlich sein kann. Stattdessen können wir Clustering verwenden, um dann mit einem Klassifikator ein induktives Modell zu lernen, was mehrere Vorteile hat:
es ermöglicht den Clustern, auf neue Daten skaliert und angewendet zu werden
im Gegensatz zur erneuten Anpassung der Cluster an neue Stichproben stellt es sicher, dass das Labeling-Verfahren über die Zeit konsistent ist
es ermöglicht uns, die inferenziellen Fähigkeiten des Klassifikators zu nutzen, um die Cluster zu beschreiben oder zu erklären
Dieses Beispiel veranschaulicht eine generische Implementierung eines Meta-Estimators, der Clustering durch Induktion eines Klassifikators aus den Cluster-Labels erweitert.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
from sklearn.base import BaseEstimator, clone
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier
from sklearn.inspection import DecisionBoundaryDisplay
from sklearn.utils.metaestimators import available_if
from sklearn.utils.validation import check_is_fitted
N_SAMPLES = 5000
RANDOM_STATE = 42
def _classifier_has(attr):
"""Check if we can delegate a method to the underlying classifier.
First, we check the first fitted classifier if available, otherwise we
check the unfitted classifier.
"""
return lambda estimator: (
hasattr(estimator.classifier_, attr)
if hasattr(estimator, "classifier_")
else hasattr(estimator.classifier, attr)
)
class InductiveClusterer(BaseEstimator):
def __init__(self, clusterer, classifier):
self.clusterer = clusterer
self.classifier = classifier
def fit(self, X, y=None):
self.clusterer_ = clone(self.clusterer)
self.classifier_ = clone(self.classifier)
y = self.clusterer_.fit_predict(X)
self.classifier_.fit(X, y)
return self
@available_if(_classifier_has("predict"))
def predict(self, X):
check_is_fitted(self)
return self.classifier_.predict(X)
@available_if(_classifier_has("decision_function"))
def decision_function(self, X):
check_is_fitted(self)
return self.classifier_.decision_function(X)
def plot_scatter(X, color, alpha=0.5):
return plt.scatter(X[:, 0], X[:, 1], c=color, alpha=alpha, edgecolor="k")
# Generate some training data from clustering
X, y = make_blobs(
n_samples=N_SAMPLES,
cluster_std=[1.0, 1.0, 0.5],
centers=[(-5, -5), (0, 0), (5, 5)],
random_state=RANDOM_STATE,
)
# Train a clustering algorithm on the training data and get the cluster labels
clusterer = AgglomerativeClustering(n_clusters=3)
cluster_labels = clusterer.fit_predict(X)
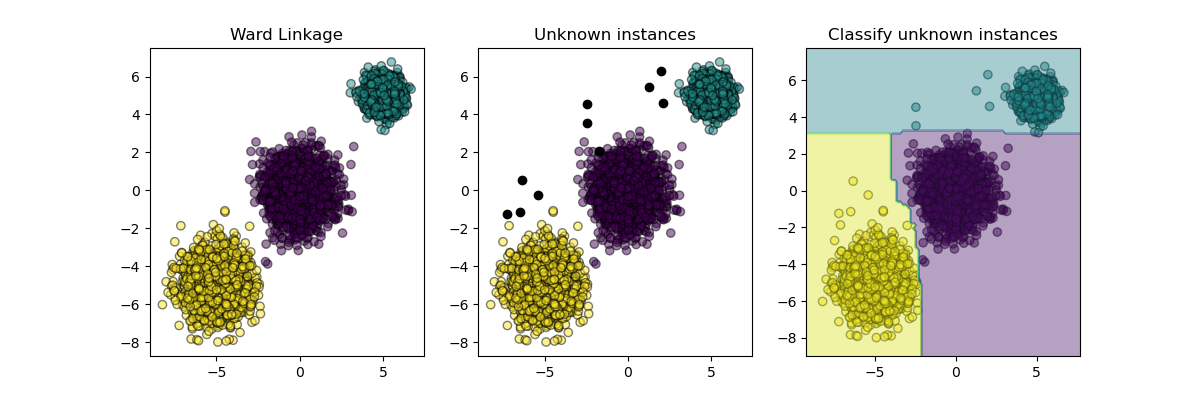
plt.figure(figsize=(12, 4))
plt.subplot(131)
plot_scatter(X, cluster_labels)
plt.title("Ward Linkage")
# Generate new samples and plot them along with the original dataset
X_new, y_new = make_blobs(
n_samples=10, centers=[(-7, -1), (-2, 4), (3, 6)], random_state=RANDOM_STATE
)
plt.subplot(132)
plot_scatter(X, cluster_labels)
plot_scatter(X_new, "black", 1)
plt.title("Unknown instances")
# Declare the inductive learning model that it will be used to
# predict cluster membership for unknown instances
classifier = RandomForestClassifier(random_state=RANDOM_STATE)
inductive_learner = InductiveClusterer(clusterer, classifier).fit(X)
probable_clusters = inductive_learner.predict(X_new)
ax = plt.subplot(133)
plot_scatter(X, cluster_labels)
plot_scatter(X_new, probable_clusters)
# Plotting decision regions
DecisionBoundaryDisplay.from_estimator(
inductive_learner, X, response_method="predict", alpha=0.4, ax=ax
)
plt.title("Classify unknown instances")
plt.show()
Gesamtlaufzeit des Skripts: (0 Minuten 1,972 Sekunden)
Verwandte Beispiele


Eine Demo des strukturierten Ward Hierarchischen Clusterings auf einem Bild von Münzen
Verschiedenes Agglomeratives Clustering auf einer 2D-Einbettung von Ziffern
Vergleich verschiedener hierarchischer Linkage-Methoden auf Toy-Datensätzen