Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
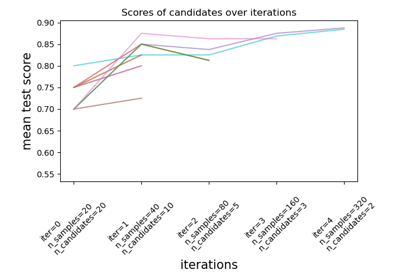
Vergleich von Zufallssuche und Gittersuche zur Schätzung von Hyperparametern#
Vergleicht Zufallssuche und Gittersuche zur Optimierung der Hyperparameter eines linearen SVM mit SGD-Training. Alle Parameter, die das Lernen beeinflussen, werden gleichzeitig durchsucht (mit Ausnahme der Anzahl der Schätzer, die einen Zeit-/Qualitätskompromiss darstellt).
Die Zufallssuche und die Gittersuche untersuchen exakt denselben Parameterraum. Die Ergebnisse bei den Parametereinstellungen sind ziemlich ähnlich, während die Laufzeit für die Zufallssuche drastisch geringer ist.
Die Leistung ist bei der Zufallssuche möglicherweise geringfügig schlechter, was wahrscheinlich auf einen Rauscheffekt zurückzuführen ist und sich nicht auf einen zurückgehaltenen Testdatensatz übertragen würde.
Beachten Sie, dass in der Praxis nicht so viele verschiedene Parameter gleichzeitig mit der Gittersuche durchsucht würden, sondern nur diejenigen ausgewählt würden, die als am wichtigsten erachtet werden.
RandomizedSearchCV took 5.84 seconds for 15 candidates parameter settings.
Model with rank: 1
Mean validation score: 0.993 (std: 0.007)
Parameters: {'alpha': np.float64(0.024655519784127337), 'average': False, 'l1_ratio': np.float64(0.18864053243980072)}
Model with rank: 2
Mean validation score: 0.983 (std: 0.018)
Parameters: {'alpha': np.float64(0.29696409452126926), 'average': False, 'l1_ratio': np.float64(0.19632366925404443)}
Model with rank: 3
Mean validation score: 0.981 (std: 0.013)
Parameters: {'alpha': np.float64(0.08370746697519009), 'average': False, 'l1_ratio': np.float64(0.5855634246868421)}
GridSearchCV took 22.18 seconds for 60 candidate parameter settings.
Model with rank: 1
Mean validation score: 0.998 (std: 0.004)
Parameters: {'alpha': np.float64(0.01), 'average': False, 'l1_ratio': np.float64(0.2222222222222222)}
Model with rank: 2
Mean validation score: 0.998 (std: 0.004)
Parameters: {'alpha': np.float64(0.1), 'average': False, 'l1_ratio': np.float64(0.1111111111111111)}
Model with rank: 3
Mean validation score: 0.994 (std: 0.005)
Parameters: {'alpha': np.float64(0.01), 'average': False, 'l1_ratio': np.float64(0.3333333333333333)}
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
from time import time
import numpy as np
import scipy.stats as stats
from sklearn.datasets import load_digits
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
# get some data
X, y = load_digits(return_X_y=True, n_class=3)
# build a classifier
clf = SGDClassifier(loss="hinge", penalty="elasticnet", fit_intercept=True)
# Utility function to report best scores
def report(results, n_top=3):
for i in range(1, n_top + 1):
candidates = np.flatnonzero(results["rank_test_score"] == i)
for candidate in candidates:
print("Model with rank: {0}".format(i))
print(
"Mean validation score: {0:.3f} (std: {1:.3f})".format(
results["mean_test_score"][candidate],
results["std_test_score"][candidate],
)
)
print("Parameters: {0}".format(results["params"][candidate]))
print("")
# specify parameters and distributions to sample from
param_dist = {
"average": [True, False],
"l1_ratio": stats.uniform(0, 1),
"alpha": stats.loguniform(1e-2, 1e0),
}
# run randomized search
n_iter_search = 15
random_search = RandomizedSearchCV(
clf, param_distributions=param_dist, n_iter=n_iter_search
)
start = time()
random_search.fit(X, y)
print(
"RandomizedSearchCV took %.2f seconds for %d candidates parameter settings."
% ((time() - start), n_iter_search)
)
report(random_search.cv_results_)
# use a full grid over all parameters
param_grid = {
"average": [True, False],
"l1_ratio": np.linspace(0, 1, num=10),
"alpha": np.power(10, np.arange(-2, 1, dtype=float)),
}
# run grid search
grid_search = GridSearchCV(clf, param_grid=param_grid)
start = time()
grid_search.fit(X, y)
print(
"GridSearchCV took %.2f seconds for %d candidate parameter settings."
% (time() - start, len(grid_search.cv_results_["params"]))
)
report(grid_search.cv_results_)
Gesamtlaufzeit des Skripts: (0 Minuten 28,031 Sekunden)
Verwandte Beispiele

Benutzerdefinierte Refit-Strategie einer Gitter-Suche mit Kreuzvalidierung
Pipelining: Verkettung einer PCA und einer logistischen Regression
