Hinweis
Zum Ende gehen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Release Highlights für scikit-learn 1.0#
Wir freuen uns sehr, die Veröffentlichung von scikit-learn 1.0 bekannt zu geben! Die Bibliothek ist seit einiger Zeit stabil, und die Veröffentlichung der Version 1.0 erkennt dies an und signalisiert es unseren Nutzern. Diese Version enthält keine abwärtskompatiblen Änderungen, abgesehen vom üblichen Deprecation-Zyklus von zwei Releases. Für die Zukunft bemühen wir uns, dieses Muster beizubehalten.
Diese Version enthält einige neue Schlüsselfunktionen sowie viele Verbesserungen und Fehlerkorrekturen. Nachfolgend erläutern wir einige der wichtigsten Funktionen dieser Version. **Eine vollständige Liste aller Änderungen** finden Sie in den Release Notes.
Um die neueste Version zu installieren (mit pip)
pip install --upgrade scikit-learn
oder mit conda
conda install -c conda-forge scikit-learn
Schlüsselwort- und Positionsargumente#
Die scikit-learn API stellt viele Funktionen und Methoden mit zahlreichen Eingabeparametern bereit. Beispielsweise konnte man vor dieser Version ein HistGradientBoostingRegressor wie folgt instanziieren:
HistGradientBoostingRegressor("squared_error", 0.1, 100, 31, None,
20, 0.0, 255, None, None, False, "auto", "loss", 0.1, 10, 1e-7,
0, None)
Das Verständnis des obigen Codes erfordert, dass der Leser die API-Dokumentation aufruft und jeden Parameter auf seine Position und Bedeutung prüft. Um die Lesbarkeit von Code, der auf scikit-learn basiert, zu verbessern, müssen Benutzer nun die meisten Parameter mit ihren Namen als Schlüsselwortargumente und nicht als Positionsargumente angeben. Beispielsweise wäre der obige Code:
HistGradientBoostingRegressor(
loss="squared_error",
learning_rate=0.1,
max_iter=100,
max_leaf_nodes=31,
max_depth=None,
min_samples_leaf=20,
l2_regularization=0.0,
max_bins=255,
categorical_features=None,
monotonic_cst=None,
warm_start=False,
early_stopping="auto",
scoring="loss",
validation_fraction=0.1,
n_iter_no_change=10,
tol=1e-7,
verbose=0,
random_state=None,
)
was wesentlich lesbarer ist. Positionsargumente wurden seit Version 0.23 als veraltet markiert und lösen nun einen TypeError aus. Eine begrenzte Anzahl von Positionsargumenten ist in einigen Fällen weiterhin zulässig, beispielsweise bei PCA, wo PCA(10) weiterhin zulässig ist, aber PCA(10, False) nicht mehr.
Spline-Transformatoren#
Eine Möglichkeit, nichtlineare Terme zum Feature-Set eines Datensatzes hinzuzufügen, ist die Generierung von Spline-Basis-Funktionen für kontinuierliche/numerische Features mit dem neuen SplineTransformer. Splines sind stückweise Polynome, die durch ihren Polynomgrad und die Positionen der Knoten parametrisiert sind. Der SplineTransformer implementiert eine B-Spline-Basis.

Der folgende Code zeigt Splines in Aktion. Weitere Informationen finden Sie im Benutzerhandbuch.
import numpy as np
from sklearn.preprocessing import SplineTransformer
X = np.arange(5).reshape(5, 1)
spline = SplineTransformer(degree=2, n_knots=3)
spline.fit_transform(X)
array([[0.5 , 0.5 , 0. , 0. ],
[0.125, 0.75 , 0.125, 0. ],
[0. , 0.5 , 0.5 , 0. ],
[0. , 0.125, 0.75 , 0.125],
[0. , 0. , 0.5 , 0.5 ]])
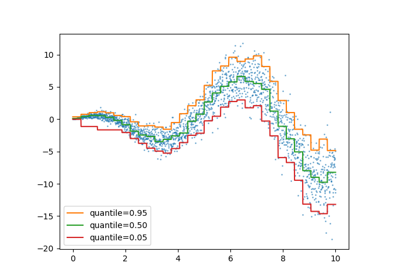
Quantil-Regressor#
Die Quantilregression schätzt den Median oder andere Quantile von \(y\) bedingt auf \(X\), während die gewöhnliche kleinste Quadrate (OLS) den bedingten Mittelwert schätzt.
Als lineares Modell gibt der neue QuantileRegressor lineare Vorhersagen \(\hat{y}(w, X) = Xw\) für das \(q\)-te Quantil, \(q \in (0, 1)\). Die Gewichte oder Koeffizienten \(w\) werden dann durch das folgende Minimierungsproblem gefunden:
Dies besteht aus dem Pinball-Verlust (auch bekannt als linearer Verlust), siehe auch mean_pinball_loss,
und der L1-Strafe, die durch den Parameter alpha gesteuert wird, ähnlich wie bei linear_model.Lasso.
Bitte sehen Sie sich das folgende Beispiel an, um zu sehen, wie es funktioniert, und das Benutzerhandbuch für weitere Details.

Unterstützung für Feature-Namen#
Wenn einem Schätzer während des fit ein pandas DataFrame übergeben wird, setzt der Schätzer ein Attribut feature_names_in_, das die Feature-Namen enthält. Dies ist Teil von SLEP007. Beachten Sie, dass die Unterstützung für Feature-Namen nur aktiviert ist, wenn die Spaltennamen im DataFrame alle Zeichenketten sind. feature_names_in_ wird verwendet, um zu überprüfen, ob die Spaltennamen des im Nicht-fit übergebenen DataFrames, wie z. B. bei predict, mit den Features im fit konsistent sind.
import pandas as pd
from sklearn.preprocessing import StandardScaler
X = pd.DataFrame([[1, 2, 3], [4, 5, 6]], columns=["a", "b", "c"])
scalar = StandardScaler().fit(X)
scalar.feature_names_in_
array(['a', 'b', 'c'], dtype=object)
Die Unterstützung für get_feature_names_out ist für Transformatoren verfügbar, die bereits get_feature_names hatten, und für Transformatoren mit einer Eins-zu-Eins-Entsprechung zwischen Eingabe und Ausgabe, wie z. B. StandardScaler. Die Unterstützung für get_feature_names_out wird in zukünftigen Versionen zu allen anderen Transformatoren hinzugefügt. Darüber hinaus ist compose.ColumnTransformer.get_feature_names_out verfügbar, um die Feature-Namen seiner Transformatoren zu kombinieren.
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
X = pd.DataFrame({"pet": ["dog", "cat", "fish"], "age": [3, 7, 1]})
preprocessor = ColumnTransformer(
[
("numerical", StandardScaler(), ["age"]),
("categorical", OneHotEncoder(), ["pet"]),
],
verbose_feature_names_out=False,
).fit(X)
preprocessor.get_feature_names_out()
array(['age', 'pet_cat', 'pet_dog', 'pet_fish'], dtype=object)
Wenn dieser preprocessor mit einer Pipeline verwendet wird, werden die vom Klassifikator verwendeten Feature-Namen durch Slicing und Aufruf von get_feature_names_out erhalten.
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
y = [1, 0, 1]
pipe = make_pipeline(preprocessor, LogisticRegression())
pipe.fit(X, y)
pipe[:-1].get_feature_names_out()
array(['age', 'pet_cat', 'pet_dog', 'pet_fish'], dtype=object)
Eine flexiblere Plotting-API#
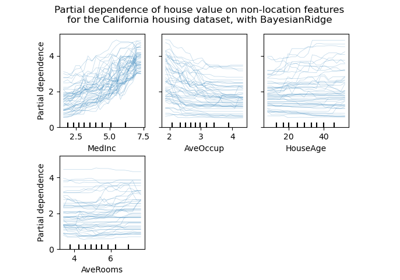
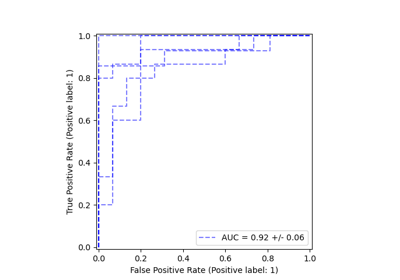
metrics.ConfusionMatrixDisplay, metrics.PrecisionRecallDisplay, metrics.DetCurveDisplay und inspection.PartialDependenceDisplay stellen nun zwei Klassenmethoden bereit: from_estimator und from_predictions, die es Benutzern ermöglichen, ein Plot basierend auf den Vorhersagen oder einem Schätzer zu erstellen. Dies bedeutet, dass die entsprechenden plot_* Funktionen veraltet sind. Bitte sehen Sie sich Beispiel eins und Beispiel zwei an, um zu erfahren, wie die neuen Plotting-Funktionen verwendet werden.
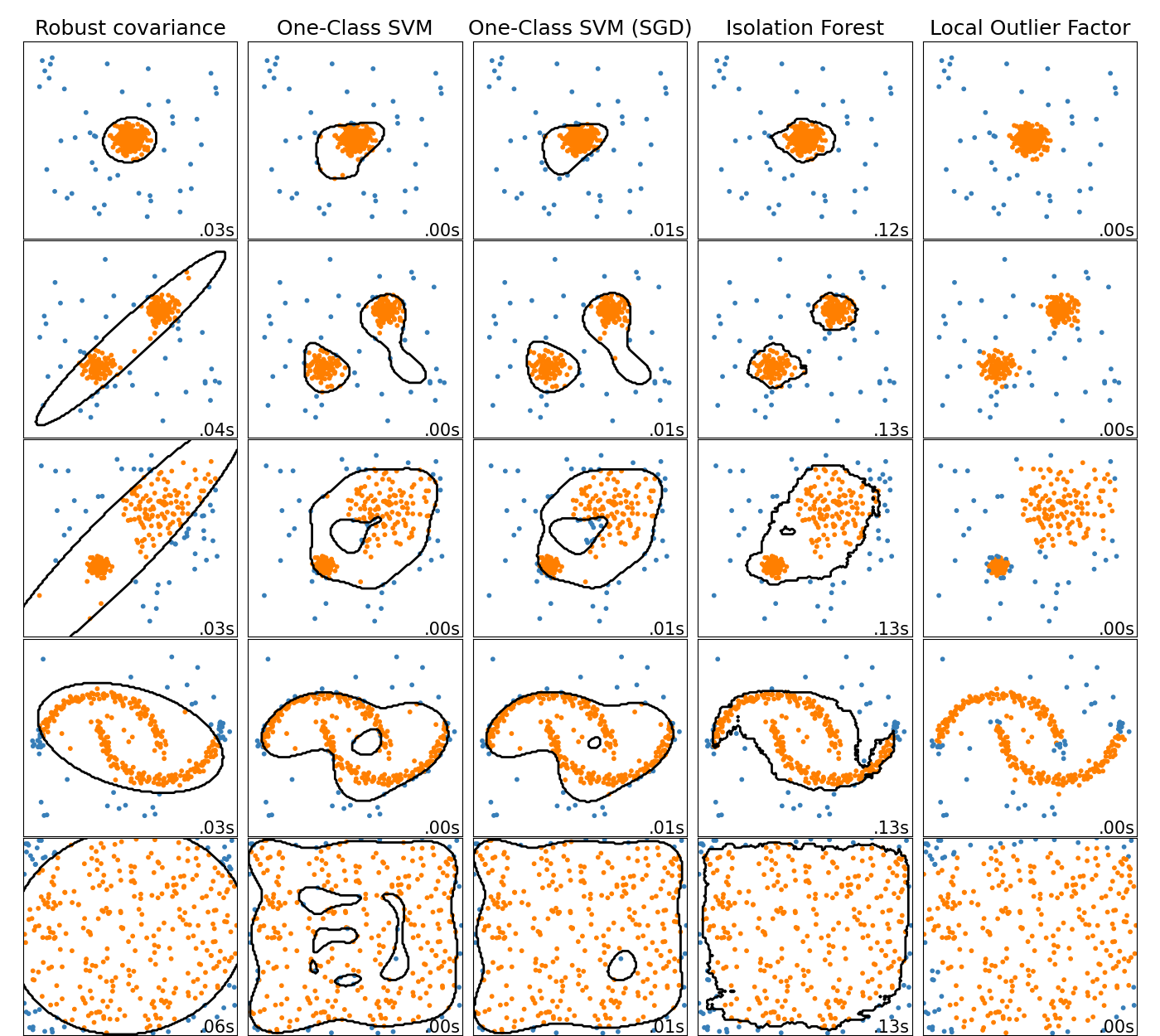
Online One-Class SVM#
Die neue Klasse SGDOneClassSVM implementiert eine Online-Lineare-Version der One-Class SVM unter Verwendung eines stochastischen Gradientenabstiegs. In Kombination mit Kernel-Approximationstechniken kann SGDOneClassSVM verwendet werden, um die Lösung einer kernelisierten One-Class SVM, implementiert in OneClassSVM, mit einer Fit-Zeitkomplexität, die linear zur Anzahl der Samples ist, anzunähern. Beachten Sie, dass die Komplexität einer kernelisierten One-Class SVM bestenfalls quadratisch zur Anzahl der Samples ist. SGDOneClassSVM eignet sich somit gut für Datensätze mit einer großen Anzahl von Trainingssamples (> 10.000), für die die SGD-Variante um mehrere Größenordnungen schneller sein kann. Bitte sehen Sie sich dieses Beispiel an, um zu sehen, wie es verwendet wird, und das Benutzerhandbuch für weitere Details.
Histogramm-basierte Gradient Boosting Modelle sind jetzt stabil#
HistGradientBoostingRegressor und HistGradientBoostingClassifier sind nicht mehr experimentell und können einfach importiert und wie folgt verwendet werden:
from sklearn.ensemble import HistGradientBoostingClassifier
Neue Dokumentationsverbesserungen#
Diese Version enthält viele Dokumentationsverbesserungen. Von über 2100 zusammengeführten Pull-Requests sind etwa 800 Verbesserungen an unserer Dokumentation.
Gesamtlaufzeit des Skripts: (0 Minuten 0.014 Sekunden)
Verwandte Beispiele