Hinweis
Gehen Sie zum Ende, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Unterstützung kategorialer Merkmale in Gradient Boosting#
In diesem Beispiel vergleichen wir die Trainingszeiten und Vorhersageleistungen von HistGradientBoostingRegressor mit verschiedenen Kodierungsstrategien für kategoriale Merkmale. Insbesondere evaluieren wir
„Dropped“: Entfernen der kategorialen Merkmale;
„One Hot“: Verwendung eines
OneHotEncoder;„Ordinal“: Verwendung eines
OrdinalEncoderund Behandlung von Kategorien als geordnete, äquidistante Mengen;„Target“: Verwendung eines
TargetEncoder;„Native“: Verlassen auf die native Unterstützung für Kategorien des
HistGradientBoostingRegressor-Schätzers.
Zu diesem Zweck verwenden wir den Ames Iowa Housing Datensatz, der aus numerischen und kategorialen Merkmalen besteht, wobei das Ziel der Verkaufspreis des Hauses ist.
Siehe Merkmale in Histogramm-Gradient-Boosting-Bäumen für ein Beispiel, das einige andere Merkmale von HistGradientBoostingRegressor zeigt.
Siehe Vergleich von Target Encoder mit anderen Encodern für einen Vergleich von Kodierungsstrategien in Gegenwart von kategorialen Merkmalen mit hoher Kardinalität.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Laden des Ames Housing Datensatzes#
Zuerst laden wir die Ames Housing Daten als Pandas DataFrame. Die Merkmale sind entweder kategorial oder numerisch.
from sklearn.datasets import fetch_openml
X, y = fetch_openml(data_id=42165, as_frame=True, return_X_y=True)
# Select only a subset of features of X to make the example faster to run
categorical_columns_subset = [
"BldgType",
"GarageFinish",
"LotConfig",
"Functional",
"MasVnrType",
"HouseStyle",
"FireplaceQu",
"ExterCond",
"ExterQual",
"PoolQC",
]
numerical_columns_subset = [
"3SsnPorch",
"Fireplaces",
"BsmtHalfBath",
"HalfBath",
"GarageCars",
"TotRmsAbvGrd",
"BsmtFinSF1",
"BsmtFinSF2",
"GrLivArea",
"ScreenPorch",
]
X = X[categorical_columns_subset + numerical_columns_subset]
X[categorical_columns_subset] = X[categorical_columns_subset].astype("category")
categorical_columns = X.select_dtypes(include="category").columns
n_categorical_features = len(categorical_columns)
n_numerical_features = X.select_dtypes(include="number").shape[1]
print(f"Number of samples: {X.shape[0]}")
print(f"Number of features: {X.shape[1]}")
print(f"Number of categorical features: {n_categorical_features}")
print(f"Number of numerical features: {n_numerical_features}")
Number of samples: 1460
Number of features: 20
Number of categorical features: 10
Number of numerical features: 10
Gradient Boosting Schätzer mit entfernten kategorialen Merkmalen#
Als Basis erstellen wir einen Schätzer, bei dem die kategorialen Merkmale entfernt werden.
from sklearn.compose import make_column_selector, make_column_transformer
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.pipeline import make_pipeline
dropper = make_column_transformer(
("drop", make_column_selector(dtype_include="category")), remainder="passthrough"
)
hist_dropped = make_pipeline(dropper, HistGradientBoostingRegressor(random_state=42))
hist_dropped
Pipeline(steps=[('columntransformer',
ColumnTransformer(remainder='passthrough',
transformers=[('drop', 'drop',
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4a2b293d0>)])),
('histgradientboostingregressor',
HistGradientBoostingRegressor(random_state=42))])In einer Jupyter-Umgebung führen Sie diese Zelle bitte erneut aus, um die HTML-Darstellung anzuzeigen, oder vertrauen Sie dem Notebook.Auf GitHub kann die HTML-Darstellung nicht gerendert werden. Versuchen Sie bitte, diese Seite mit nbviewer.org zu laden.
Parameter
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4a2b293d0>
drop
passthrough
Parameter
Gradient Boosting Schätzer mit One-Hot-Kodierung#
Als nächstes erstellen wir eine Pipeline, um kategoriale Merkmale mittels One-Hot-Kodierung zu transformieren, während die verbleibenden Merkmale unverändert als "passthrough" behandelt werden.
from sklearn.preprocessing import OneHotEncoder
one_hot_encoder = make_column_transformer(
(
OneHotEncoder(sparse_output=False, handle_unknown="ignore"),
make_column_selector(dtype_include="category"),
),
remainder="passthrough",
)
hist_one_hot = make_pipeline(
one_hot_encoder, HistGradientBoostingRegressor(random_state=42)
)
hist_one_hot
Pipeline(steps=[('columntransformer',
ColumnTransformer(remainder='passthrough',
transformers=[('onehotencoder',
OneHotEncoder(handle_unknown='ignore',
sparse_output=False),
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4a2b28f50>)])),
('histgradientboostingregressor',
HistGradientBoostingRegressor(random_state=42))])In einer Jupyter-Umgebung führen Sie diese Zelle bitte erneut aus, um die HTML-Darstellung anzuzeigen, oder vertrauen Sie dem Notebook.Auf GitHub kann die HTML-Darstellung nicht gerendert werden. Versuchen Sie bitte, diese Seite mit nbviewer.org zu laden.
Parameter
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4a2b28f50>
Parameter
passthrough
Parameter
Gradient Boosting Schätzer mit ordinaler Kodierung#
Als nächstes erstellen wir eine Pipeline, die kategoriale Merkmale als geordnete Mengen behandelt, d.h. die Kategorien werden als 0, 1, 2 usw. kodiert und als kontinuierliche Merkmale behandelt.
import numpy as np
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = make_column_transformer(
(
OrdinalEncoder(handle_unknown="use_encoded_value", unknown_value=np.nan),
make_column_selector(dtype_include="category"),
),
remainder="passthrough",
)
hist_ordinal = make_pipeline(
ordinal_encoder, HistGradientBoostingRegressor(random_state=42)
)
hist_ordinal
Pipeline(steps=[('columntransformer',
ColumnTransformer(remainder='passthrough',
transformers=[('ordinalencoder',
OrdinalEncoder(handle_unknown='use_encoded_value',
unknown_value=nan),
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4a1b6f790>)])),
('histgradientboostingregressor',
HistGradientBoostingRegressor(random_state=42))])In einer Jupyter-Umgebung führen Sie diese Zelle bitte erneut aus, um die HTML-Darstellung anzuzeigen, oder vertrauen Sie dem Notebook.Auf GitHub kann die HTML-Darstellung nicht gerendert werden. Versuchen Sie bitte, diese Seite mit nbviewer.org zu laden.
Parameter
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4a1b6f790>
Parameter
passthrough
Parameter
Gradient Boosting Schätzer mit Target-Kodierung#
Eine weitere Möglichkeit ist die Verwendung des TargetEncoder, der die Kategorien basierend auf dem Mittelwert der (Trainings-)Zielvariable kodiert, wie er mit einem geglätteten np.mean(y, axis=0) berechnet wird, d.h.:
in der Regression wird der Mittelwert von
yverwendet;in der binären Klassifizierung die Rate der positiven Klasse;
in der Multiklassenklassifizierung ein Vektor von Klassenraten (eine pro Klasse).
Für jede Kategorie berechnet er diese Zielmittelwerte mithilfe von Cross Fitting, was bedeutet, dass die Trainingsdaten in Folds aufgeteilt werden: in jedem Fold werden die Mittelwerte nur auf einem Teil der Daten berechnet und dann auf den zurückgehaltenen Teil angewendet. Auf diese Weise wird jede Stichprobe mit Statistiken aus Daten kodiert, zu denen sie nicht gehörte, was Informationslecks aus dem Ziel verhindert.
from sklearn.preprocessing import TargetEncoder
target_encoder = make_column_transformer(
(
TargetEncoder(target_type="continuous", random_state=42),
make_column_selector(dtype_include="category"),
),
remainder="passthrough",
)
hist_target = make_pipeline(
target_encoder, HistGradientBoostingRegressor(random_state=42)
)
hist_target
Pipeline(steps=[('columntransformer',
ColumnTransformer(remainder='passthrough',
transformers=[('targetencoder',
TargetEncoder(random_state=42,
target_type='continuous'),
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4a1b6f2d0>)])),
('histgradientboostingregressor',
HistGradientBoostingRegressor(random_state=42))])In einer Jupyter-Umgebung führen Sie diese Zelle bitte erneut aus, um die HTML-Darstellung anzuzeigen, oder vertrauen Sie dem Notebook.Auf GitHub kann die HTML-Darstellung nicht gerendert werden. Versuchen Sie bitte, diese Seite mit nbviewer.org zu laden.
Parameter
Parameter
<sklearn.compose._column_transformer.make_column_selector object at 0x7fb4a1b6f2d0>
Parameter
passthrough
Parameter
Gradient Boosting Schätzer mit nativer kategorialer Unterstützung#
Nun erstellen wir einen HistGradientBoostingRegressor Schätzer, der kategoriale Merkmale nativ ohne explizite Kodierung verarbeiten kann. Diese Funktionalität kann durch Setzen von categorical_features="from_dtype", was automatisch Merkmale mit kategorialen Datentypen erkennt, oder expliziter durch categorical_features=categorical_columns_subset aktiviert werden.
Im Gegensatz zu früheren Kodierungsansätzen behandelt der Schätzer die kategorialen Merkmale nativ. Bei jeder Aufteilung partitioniert er die Kategorien eines solchen Merkmals in disjunkte Mengen, wobei eine Heuristik verwendet wird, die sie nach ihrer Auswirkung auf die Zielvariable sortiert. Siehe Split-Findung mit kategorialen Merkmalen für Details.
Während die ordinale Kodierung bei Merkmalen mit geringer Kardinalität gut funktionieren kann, auch wenn die Kategorien keine natürliche Reihenfolge haben, erfordert das Erreichen sinnvoller Aufteilungen tiefere Bäume, wenn die Kardinalität steigt. Die native kategoriale Unterstützung vermeidet dies, indem sie direkt mit ungeordneten Kategorien arbeitet. Der Vorteil gegenüber der One-Hot-Kodierung liegt in der ausgelassenen Vorverarbeitung und einer schnelleren Trainings- und Vorhersagezeit.
hist_native = HistGradientBoostingRegressor(
random_state=42, categorical_features="from_dtype"
)
hist_native
HistGradientBoostingRegressor(random_state=42)In einer Jupyter-Umgebung führen Sie diese Zelle bitte erneut aus, um die HTML-Darstellung anzuzeigen, oder vertrauen Sie dem Notebook.
Auf GitHub kann die HTML-Darstellung nicht gerendert werden. Versuchen Sie bitte, diese Seite mit nbviewer.org zu laden.
Parameter
Modellvergleich#
Hier verwenden wir Kreuzvalidierung, um die Modellleistung in Bezug auf mean_absolute_percentage_error und Trainingszeiten zu vergleichen. In den folgenden Diagrammen stellen die Fehlerbalken die 1-fache Standardabweichung dar, wie sie über die Kreuzvalidierung-Splits berechnet wurde.
from sklearn.model_selection import cross_validate
common_params = {"cv": 5, "scoring": "neg_mean_absolute_percentage_error", "n_jobs": -1}
dropped_result = cross_validate(hist_dropped, X, y, **common_params)
one_hot_result = cross_validate(hist_one_hot, X, y, **common_params)
ordinal_result = cross_validate(hist_ordinal, X, y, **common_params)
target_result = cross_validate(hist_target, X, y, **common_params)
native_result = cross_validate(hist_native, X, y, **common_params)
results = [
("Dropped", dropped_result),
("One Hot", one_hot_result),
("Ordinal", ordinal_result),
("Target", target_result),
("Native", native_result),
]
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
def plot_performance_tradeoff(results, title):
fig, ax = plt.subplots()
markers = ["s", "o", "^", "x", "D"]
for idx, (name, result) in enumerate(results):
test_error = -result["test_score"]
mean_fit_time = np.mean(result["fit_time"])
mean_score = np.mean(test_error)
std_fit_time = np.std(result["fit_time"])
std_score = np.std(test_error)
ax.scatter(
result["fit_time"],
test_error,
label=name,
marker=markers[idx],
)
ax.scatter(
mean_fit_time,
mean_score,
color="k",
marker=markers[idx],
)
ax.errorbar(
x=mean_fit_time,
y=mean_score,
yerr=std_score,
c="k",
capsize=2,
)
ax.errorbar(
x=mean_fit_time,
y=mean_score,
xerr=std_fit_time,
c="k",
capsize=2,
)
ax.set_xscale("log")
nticks = 7
x0, x1 = np.log10(ax.get_xlim())
ticks = np.logspace(x0, x1, nticks)
ax.set_xticks(ticks)
ax.xaxis.set_major_formatter(ticker.FormatStrFormatter("%1.1e"))
ax.minorticks_off()
ax.annotate(
" best\nmodels",
xy=(0.04, 0.04),
xycoords="axes fraction",
xytext=(0.09, 0.14),
textcoords="axes fraction",
arrowprops=dict(arrowstyle="->", lw=1.5),
)
ax.set_xlabel("Time to fit (seconds)")
ax.set_ylabel("Mean Absolute Percentage Error")
ax.set_title(title)
ax.legend()
plt.show()
plot_performance_tradeoff(results, "Gradient Boosting on Ames Housing")
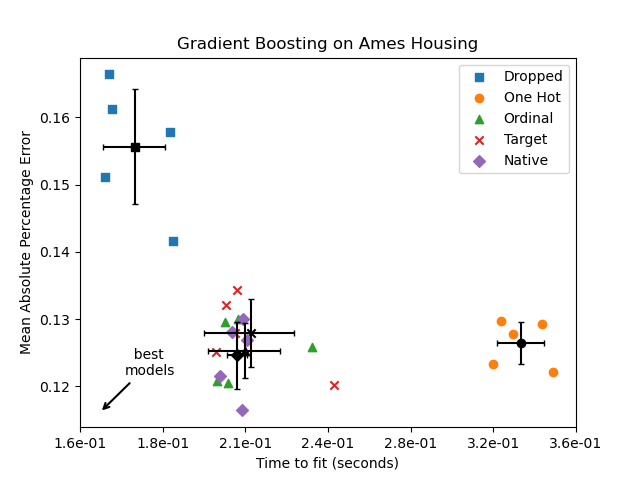
Im obigen Diagramm sind die „besten Modelle“ diejenigen, die sich näher an der unteren linken Ecke befinden, wie durch den Pfeil angezeigt. Diese Modelle würden tatsächlich schnelleres Training und geringere Fehler aufweisen.
Das Modell, das One-Hot-kodierte Daten verwendet, ist das langsamste. Dies ist zu erwarten, da die One-Hot-Kodierung eine zusätzliche Merkmalsspalte für jeden Kategorie-Wert jedes kategorialen Merkmals erstellt, was die Anzahl der Split-Kandidaten während des Trainings erheblich erhöht. Theoretisch erwarten wir, dass die native Verarbeitung kategorialer Merkmale geringfügig langsamer ist als die Behandlung von Kategorien als geordnete Mengen („Ordinal“), da die native Verarbeitung das Sortieren von Kategorien erfordert. Die Trainingszeiten sollten jedoch bei einer kleinen Anzahl von Kategorien nahe beieinander liegen, und dies spiegelt sich möglicherweise nicht immer in der Praxis wider.
Die Zeit, die für das Training mit dem TargetEncoder benötigt wird, hängt vom Parameter cv für Cross Fitting ab, da das Hinzufügen von Splits mit einem Rechenaufwand verbunden ist.
Hinsichtlich der Vorhersageleistung führt das Entfernen der kategorialen Merkmale zur schlechtesten Leistung. Die vier Modelle, die kategoriale Merkmale verwenden, haben vergleichbare Fehlerraten, wobei die native Verarbeitung einen leichten Vorteil hat.
Begrenzung der Anzahl von Splits#
Im Allgemeinen kann man schlechtere Vorhersagen von One-Hot-kodierten Daten erwarten, insbesondere wenn die Baumtiefe oder die Anzahl der Knoten begrenzt sind: Mit One-Hot-kodierten Daten benötigt man mehr Split-Punkte, d.h. mehr Tiefe, um einen äquivalenten Split wiederherzustellen, der mit nativen Mitteln in einem einzigen Split-Punkt erzielt werden könnte.
Dies gilt auch, wenn Kategorien als ordinale Mengen behandelt werden: Wenn die Kategorien A..F sind und der beste Split ACF - BDE ist, würde das One-Hot-Encoder-Modell 3 Split-Punkte benötigen (einen pro Kategorie im linken Knoten), und das ordinale Nicht-Native-Modell würde 4 Splits benötigen: 1 Split, um A zu isolieren, 1 Split, um F zu isolieren, und 2 Splits, um C von BCDE zu isolieren.
Wie stark sich die Leistungen der Modelle in der Praxis unterscheiden, hängt vom Datensatz und der Flexibilität der Bäume ab.
Um dies zu sehen, führen wir die gleiche Analyse mit Unter-Fitting-Modellen erneut durch, bei denen wir die Gesamtzahl der Splits künstlich begrenzen, indem wir sowohl die Anzahl der Bäume als auch die Tiefe jedes Baumes begrenzen.
for pipe in (hist_dropped, hist_one_hot, hist_ordinal, hist_target, hist_native):
if pipe is hist_native:
# The native model does not use a pipeline so, we can set the parameters
# directly.
pipe.set_params(max_depth=3, max_iter=15)
else:
pipe.set_params(
histgradientboostingregressor__max_depth=3,
histgradientboostingregressor__max_iter=15,
)
dropped_result = cross_validate(hist_dropped, X, y, **common_params)
one_hot_result = cross_validate(hist_one_hot, X, y, **common_params)
ordinal_result = cross_validate(hist_ordinal, X, y, **common_params)
target_result = cross_validate(hist_target, X, y, **common_params)
native_result = cross_validate(hist_native, X, y, **common_params)
results_underfit = [
("Dropped", dropped_result),
("One Hot", one_hot_result),
("Ordinal", ordinal_result),
("Target", target_result),
("Native", native_result),
]
plot_performance_tradeoff(
results_underfit, "Gradient Boosting on Ames Housing (few and shallow trees)"
)
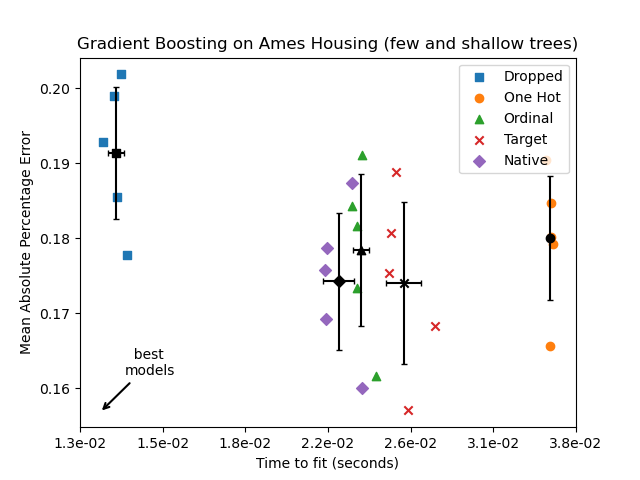
Die Ergebnisse für diese Unter-Fitting-Modelle bestätigen unsere bisherige Intuition: Die native kategoriale Handhabungsstrategie erzielt die besten Ergebnisse, wenn das Budget für Splits begrenzt ist. Die drei expliziten Kodierungsstrategien (One-Hot, Ordinal und Target-Kodierung) führen zu etwas größeren Fehlern als der Schätzer, der kategoriale Merkmale einfach ganz entfernt, aber immer noch besser als das Basismodell.
Gesamte Laufzeit des Skripts: (0 Minuten 4,379 Sekunden)
Verwandte Beispiele