Hinweis
Zum Ende, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Early Stopping in Gradient Boosting#
Gradient Boosting ist eine Ensemble-Technik, die mehrere schwache Lerner, typischerweise Entscheidungsbäume, kombiniert, um ein robustes und leistungsstarkes prädiktives Modell zu erstellen. Dies geschieht iterativ, wobei jede neue Stufe (Baum) die Fehler der vorherigen korrigiert.
Early Stopping ist eine Technik im Gradient Boosting, die es uns ermöglicht, die optimale Anzahl von Iterationen zu finden, die erforderlich sind, um ein Modell zu erstellen, das gut auf ungesehene Daten generalisiert und Overfitting vermeidet. Das Konzept ist einfach: Wir reservieren einen Teil unseres Datensatzes als Validierungsdatensatz (angegeben durch validation_fraction), um die Leistung des Modells während des Trainings zu bewerten. Während das Modell iterativ mit zusätzlichen Stufen (Bäumen) aufgebaut wird, wird seine Leistung auf dem Validierungsdatensatz als Funktion der Anzahl der Schritte überwacht.
Early Stopping wird wirksam, wenn sich die Leistung des Modells auf dem Validierungsdatensatz über eine bestimmte Anzahl aufeinanderfolgender Stufen (angegeben durch n_iter_no_change) stabilisiert oder verschlechtert (innerhalb der durch tol angegebenen Abweichungen). Dies signalisiert, dass das Modell einen Punkt erreicht hat, an dem weitere Iterationen zu Overfitting führen können und es Zeit ist, das Training zu beenden.
Die Anzahl der Schätzer (Bäume) im endgültigen Modell kann bei Anwendung von Early Stopping über das Attribut n_estimators_ abgerufen werden. Insgesamt ist Early Stopping ein wertvolles Werkzeug, um ein Gleichgewicht zwischen Modellleistung und Effizienz beim Gradient Boosting zu finden.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Datenvorbereitung#
Zuerst laden und bereiten wir den California Housing Prices Datensatz für das Training und die Auswertung vor. Er teilt den Datensatz auf und teilt ihn in Trainings- und Validierungsdatensätze auf.
import time
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
data = fetch_california_housing()
X, y = data.data[:600], data.target[:600]
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
Modelltraining und -vergleich#
Zwei GradientBoostingRegressor Modelle werden trainiert: eines mit und eines ohne Early Stopping. Der Zweck ist, ihre Leistung zu vergleichen. Außerdem werden die Trainingszeit und die von beiden Modellen verwendeten n_estimators_ berechnet.
params = dict(n_estimators=1000, max_depth=5, learning_rate=0.1, random_state=42)
gbm_full = GradientBoostingRegressor(**params)
gbm_early_stopping = GradientBoostingRegressor(
**params,
validation_fraction=0.1,
n_iter_no_change=10,
)
start_time = time.time()
gbm_full.fit(X_train, y_train)
training_time_full = time.time() - start_time
n_estimators_full = gbm_full.n_estimators_
start_time = time.time()
gbm_early_stopping.fit(X_train, y_train)
training_time_early_stopping = time.time() - start_time
estimators_early_stopping = gbm_early_stopping.n_estimators_
Fehlerberechnung#
Der Code berechnet den mean_squared_error für die Trainings- und Validierungsdatensätze für die im vorherigen Abschnitt trainierten Modelle. Er berechnet die Fehler für jede Boosting-Iteration. Der Zweck ist die Bewertung der Leistung und Konvergenz der Modelle.
train_errors_without = []
val_errors_without = []
train_errors_with = []
val_errors_with = []
for i, (train_pred, val_pred) in enumerate(
zip(
gbm_full.staged_predict(X_train),
gbm_full.staged_predict(X_val),
)
):
train_errors_without.append(mean_squared_error(y_train, train_pred))
val_errors_without.append(mean_squared_error(y_val, val_pred))
for i, (train_pred, val_pred) in enumerate(
zip(
gbm_early_stopping.staged_predict(X_train),
gbm_early_stopping.staged_predict(X_val),
)
):
train_errors_with.append(mean_squared_error(y_train, train_pred))
val_errors_with.append(mean_squared_error(y_val, val_pred))
Vergleich visualisieren#
Es werden drei Unterdiagramme erstellt
Plotten der Trainingsfehler beider Modelle über die Boosting-Iterationen.
Plotten der Validierungsfehler beider Modelle über die Boosting-Iterationen.
Erstellen eines Balkendiagramms zum Vergleich der Trainingszeiten und der verwendeten Schätzer der Modelle mit und ohne Early Stopping.
fig, axes = plt.subplots(ncols=3, figsize=(12, 4))
axes[0].plot(train_errors_without, label="gbm_full")
axes[0].plot(train_errors_with, label="gbm_early_stopping")
axes[0].set_xlabel("Boosting Iterations")
axes[0].set_ylabel("MSE (Training)")
axes[0].set_yscale("log")
axes[0].legend()
axes[0].set_title("Training Error")
axes[1].plot(val_errors_without, label="gbm_full")
axes[1].plot(val_errors_with, label="gbm_early_stopping")
axes[1].set_xlabel("Boosting Iterations")
axes[1].set_ylabel("MSE (Validation)")
axes[1].set_yscale("log")
axes[1].legend()
axes[1].set_title("Validation Error")
training_times = [training_time_full, training_time_early_stopping]
labels = ["gbm_full", "gbm_early_stopping"]
bars = axes[2].bar(labels, training_times)
axes[2].set_ylabel("Training Time (s)")
for bar, n_estimators in zip(bars, [n_estimators_full, estimators_early_stopping]):
height = bar.get_height()
axes[2].text(
bar.get_x() + bar.get_width() / 2,
height + 0.001,
f"Estimators: {n_estimators}",
ha="center",
va="bottom",
)
plt.tight_layout()
plt.show()
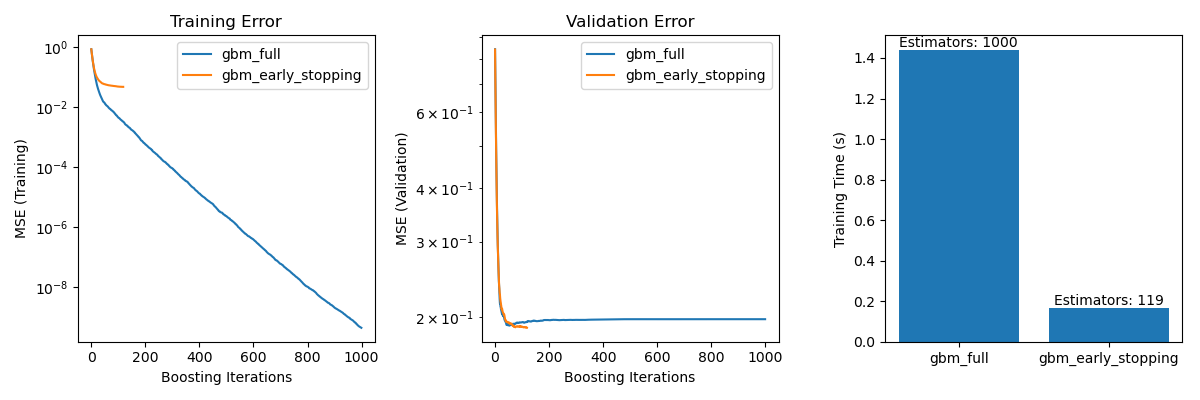
Der Unterschied im Trainingsfehler zwischen gbm_full und gbm_early_stopping ergibt sich aus der Tatsache, dass gbm_early_stopping validation_fraction der Trainingsdaten als internen Validierungsdatensatz zurückstellt. Das Early Stopping wird basierend auf diesem internen Validierungs-Score entschieden.
Zusammenfassung#
In unserem Beispiel mit dem Modell GradientBoostingRegressor auf dem California Housing Prices Datensatz haben wir die praktischen Vorteile von Early Stopping demonstriert
Vermeidung von Overfitting: Wir haben gezeigt, wie sich der Validierungsfehler nach einem bestimmten Punkt stabilisiert oder zu steigen beginnt, was darauf hindeutet, dass das Modell besser auf ungesehene Daten generalisiert. Dies wird erreicht, indem der Trainingsprozess gestoppt wird, bevor Overfitting auftritt.
Verbesserung der Trainingseffizienz: Wir haben die Trainingszeiten von Modellen mit und ohne Early Stopping verglichen. Das Modell mit Early Stopping erreichte vergleichbare Genauigkeit, benötigte aber deutlich weniger Schätzer, was zu einem schnelleren Training führte.
Gesamtlaufzeit des Skripts: (0 Minuten 2,422 Sekunden)
Verwandte Beispiele

Vergleich von Random Forests und Histogram Gradient Boosting Modellen