Hinweis
Zum Ende springen, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
Multilabel-Klassifizierung mit einer Classifier Chain#
Dieses Beispiel zeigt, wie ClassifierChain zur Lösung eines Multilabel-Klassifizierungsproblems verwendet wird.
Die naheliegendste Strategie zur Lösung einer solchen Aufgabe besteht darin, für jedes Label (d.h. jede Spalte der Zielvariablen) unabhängig einen binären Klassifikator zu trainieren. Zur Vorhersagezeit wird das Ensemble von binären Klassifikatoren verwendet, um eine Multitask-Vorhersage zusammenzustellen.
Diese Strategie erlaubt es nicht, Beziehungen zwischen verschiedenen Aufgaben zu modellieren. ClassifierChain ist der Meta-Estimator (d.h. ein Estimator, der einen inneren Estimator aufnimmt), der eine fortgeschrittenere Strategie implementiert. Das Ensemble binärer Klassifikatoren wird als Kette verwendet, bei der die Vorhersage eines Klassifikators in der Kette als Merkmal für das Training des nächsten Klassifikators für ein neues Label verwendet wird. Daher können diese zusätzlichen Merkmale jeder Kette Korrelationen zwischen den Labels nutzen.
Der Jaccard-Ähnlichkeits-Score für die Kette tendiert dazu, größer zu sein als der von den unabhängigen Basismodellen.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
Laden eines Datensatzes#
Für dieses Beispiel verwenden wir den Hefe-Datensatz, der 2.417 Datenpunkte mit jeweils 103 Merkmalen und 14 möglichen Labels enthält. Jeder Datenpunkt hat mindestens ein Label. Als Baseline trainieren wir zunächst für jedes der 14 Labels einen logistischen Regressionsklassifikator. Um die Leistung dieser Klassifikatoren zu bewerten, machen wir Vorhersagen auf einem zurückgehaltenen Testdatensatz und berechnen die Jaccard-Ähnlichkeit für jede Stichprobe.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
# Load a multi-label dataset from https://www.openml.org/d/40597
X, Y = fetch_openml("yeast", version=4, return_X_y=True)
Y = Y == "TRUE"
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=0)
Modelle anpassen#
Wir passen LogisticRegression, eingewickelt in OneVsRestClassifier, und ein Ensemble aus mehreren ClassifierChain an.
LogisticRegression eingewickelt in OneVsRestClassifier#
Da LogisticRegression standardmäßig keine Daten mit mehreren Zielen verarbeiten kann, müssen wir OneVsRestClassifier verwenden. Nach dem Anpassen des Modells berechnen wir die Jaccard-Ähnlichkeit.
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import jaccard_score
from sklearn.multiclass import OneVsRestClassifier
base_lr = LogisticRegression()
ovr = OneVsRestClassifier(base_lr)
ovr.fit(X_train, Y_train)
Y_pred_ovr = ovr.predict(X_test)
ovr_jaccard_score = jaccard_score(Y_test, Y_pred_ovr, average="samples")
Kette von binären Klassifikatoren#
Da die Modelle in jeder Kette zufällig angeordnet sind, gibt es erhebliche Leistungsschwankungen zwischen den Ketten. Vermutlich gibt es eine optimale Reihenfolge der Klassen in einer Kette, die die beste Leistung erzielt. Wir kennen diese Reihenfolge jedoch nicht a priori. Stattdessen können wir ein abstimmendes Ensemble von Classifier Chains erstellen, indem wir die binären Vorhersagen der Ketten mitteln und einen Schwellenwert von 0,5 anwenden. Der Jaccard-Ähnlichkeits-Score des Ensembles ist größer als der der unabhängigen Modelle und übertrifft tendenziell den Score jeder Kette im Ensemble (obwohl dies bei zufällig angeordneten Ketten nicht garantiert ist).
from sklearn.multioutput import ClassifierChain
chains = [ClassifierChain(base_lr, order="random", random_state=i) for i in range(10)]
for chain in chains:
chain.fit(X_train, Y_train)
Y_pred_chains = np.array([chain.predict_proba(X_test) for chain in chains])
chain_jaccard_scores = [
jaccard_score(Y_test, Y_pred_chain >= 0.5, average="samples")
for Y_pred_chain in Y_pred_chains
]
Y_pred_ensemble = Y_pred_chains.mean(axis=0)
ensemble_jaccard_score = jaccard_score(
Y_test, Y_pred_ensemble >= 0.5, average="samples"
)
Ergebnisse plotten#
Zeichne die Jaccard-Ähnlichkeits-Scores für das unabhängige Modell, jede der Ketten und das Ensemble (beachte, dass die vertikale Achse auf dieser Grafik nicht bei 0 beginnt).
model_scores = [ovr_jaccard_score] + chain_jaccard_scores + [ensemble_jaccard_score]
model_names = (
"Independent",
"Chain 1",
"Chain 2",
"Chain 3",
"Chain 4",
"Chain 5",
"Chain 6",
"Chain 7",
"Chain 8",
"Chain 9",
"Chain 10",
"Ensemble",
)
x_pos = np.arange(len(model_names))
fig, ax = plt.subplots(figsize=(7, 4))
ax.grid(True)
ax.set_title("Classifier Chain Ensemble Performance Comparison")
ax.set_xticks(x_pos)
ax.set_xticklabels(model_names, rotation="vertical")
ax.set_ylabel("Jaccard Similarity Score")
ax.set_ylim([min(model_scores) * 0.9, max(model_scores) * 1.1])
colors = ["r"] + ["b"] * len(chain_jaccard_scores) + ["g"]
ax.bar(x_pos, model_scores, alpha=0.5, color=colors)
plt.tight_layout()
plt.show()
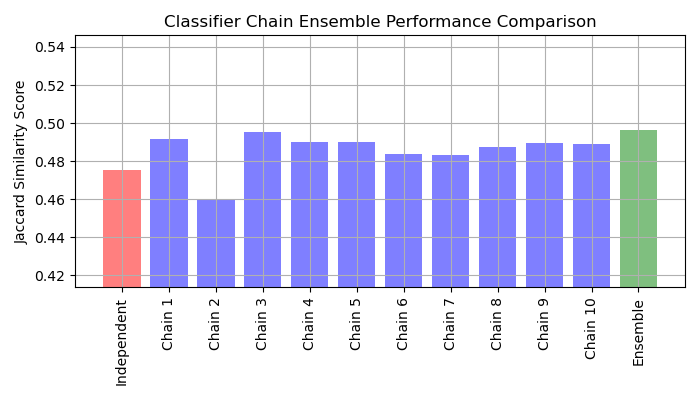
Interpretation der Ergebnisse#
Aus dieser Grafik lassen sich drei Hauptschlussfolgerungen ziehen:
Das unabhängige Modell, das von
OneVsRestClassifierumschlossen wird, schneidet schlechter ab als das Ensemble der Classifier Chains und einige der einzelnen Ketten. Dies liegt daran, dass die logistische Regression keine Beziehungen zwischen den Labels modelliert.ClassifierChainnutzt Korrelationen zwischen Labels aus, kann aber aufgrund der zufälligen Reihenfolge der Labels schlechtere Ergebnisse als ein unabhängiges Modell liefern.Ein Ensemble von Ketten erzielt bessere Ergebnisse, da es nicht nur Beziehungen zwischen den Labels erfasst, sondern auch keine starken Annahmen über deren korrekte Reihenfolge macht.
Gesamtlaufzeit des Skripts: (0 Minuten 1,655 Sekunden)
Verwandte Beispiele
Übersicht über Multiklassen-Training Meta-Estimator
Statistischer Vergleich von Modellen mittels Gitter-Suche
Vorhersagen von einzelnen und abstimmenden Regressionsmodellen plotten