Hinweis
Gehen Sie zum Ende, um den vollständigen Beispielcode herunterzuladen oder dieses Beispiel über JupyterLite oder Binder in Ihrem Browser auszuführen.
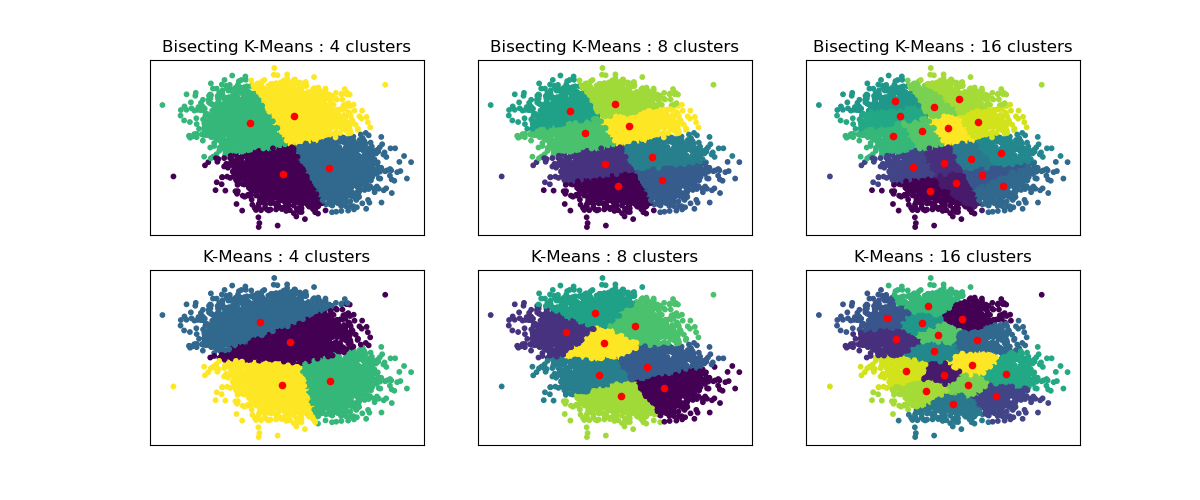
Leistungsvergleich zwischen Bisecting K-Means und regulärem K-Means#
Dieses Beispiel zeigt Unterschiede zwischen dem regulären K-Means-Algorithmus und Bisecting K-Means.
Während sich K-Means-Clusterierungen beim Erhöhen von n_clusters unterscheiden, baut die Bisecting K-Means-Clusterierung auf den vorherigen auf. Infolgedessen neigt sie dazu, Cluster zu erstellen, die eine regelmäßigere groß angelegte Struktur aufweisen. Dieser Unterschied ist visuell erkennbar: Für alle Clusterzahlen gibt es eine Trennlinie, die die gesamte Datenwolke bei BisectingKMeans in zwei Teile teilt, was bei regulärem K-Means nicht vorhanden ist.
# Authors: The scikit-learn developers
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
from sklearn.cluster import BisectingKMeans, KMeans
from sklearn.datasets import make_blobs
# Generate sample data
n_samples = 10000
random_state = 0
X, _ = make_blobs(n_samples=n_samples, centers=2, random_state=random_state)
# Number of cluster centers for KMeans and BisectingKMeans
n_clusters_list = [4, 8, 16]
# Algorithms to compare
clustering_algorithms = {
"Bisecting K-Means": BisectingKMeans,
"K-Means": KMeans,
}
# Make subplots for each variant
fig, axs = plt.subplots(
len(clustering_algorithms), len(n_clusters_list), figsize=(12, 5)
)
axs = axs.T
for i, (algorithm_name, Algorithm) in enumerate(clustering_algorithms.items()):
for j, n_clusters in enumerate(n_clusters_list):
algo = Algorithm(n_clusters=n_clusters, random_state=random_state, n_init=3)
algo.fit(X)
centers = algo.cluster_centers_
axs[j, i].scatter(X[:, 0], X[:, 1], s=10, c=algo.labels_)
axs[j, i].scatter(centers[:, 0], centers[:, 1], c="r", s=20)
axs[j, i].set_title(f"{algorithm_name} : {n_clusters} clusters")
# Hide x labels and tick labels for top plots and y ticks for right plots.
for ax in axs.flat:
ax.label_outer()
ax.set_xticks([])
ax.set_yticks([])
plt.show()
Gesamtlaufzeit des Skripts: (0 Minuten 1,053 Sekunden)
Verwandte Beispiele
Vergleich der K-Means und MiniBatchKMeans Clustering-Algorithmen
Empirische Auswertung des Einflusses der K-Means Initialisierung