brier_score_loss#
- sklearn.metrics.brier_score_loss(y_true, y_proba, *, sample_weight=None, pos_label=None, labels=None, scale_by_half='auto')[Quelle]#
Berechnet den Brier Score Verlust.
Je kleiner der Brier Score Verlust, desto besser, daher die Benennung mit „loss“ (Verlust). Der Brier Score misst die mittlere quadratische Differenz zwischen der vorhergesagten Wahrscheinlichkeit und dem tatsächlichen Ergebnis. Der Brier Score ist eine streng richtige Scoring-Regel.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- y_truearray-ähnlich mit Form (n_samples,)
Wahre Zielwerte.
- y_probaarray-like der Form (n_samples,) oder (n_samples, n_classes)
Vorhergesagte Wahrscheinlichkeiten. Wenn
y_proba.shape = (n_samples,), wird angenommen, dass die bereitgestellten Wahrscheinlichkeiten die der positiven Klasse sind. Wenny_proba.shape = (n_samples, n_classes), wird angenommen, dass die Spalten iny_probaden Labels in alphabetischer Reihenfolge entsprechen, wie esLabelBinarizertut.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- pos_labelint, float, bool oder str, Standardwert=None
Label der positiven Klasse, wenn
y_proba.shape = (n_samples,). Wenn nicht angegeben, wirdpos_labelwie folgt abgeleitet:wenn
y_truein {-1, 1} oder {0, 1} ist, istpos_labelstandardmäßig 1;andernfalls, wenn
y_trueZeichenketten enthält, wird ein Fehler ausgelöst undpos_labelsollte explizit angegeben werden;andernfalls ist
pos_labelstandardmäßig das größere Label, d. h.np.unique(y_true)[-1].
- labelsarray-like der Form (n_classes,), Standard=None
Klassenlabels, wenn
y_proba.shape = (n_samples, n_classes). Wenn nicht angegeben, werden Labels ausy_trueabgeleitet.Hinzugefügt in Version 1.7.
- scale_by_halfbool oder „auto“, Standard = „auto“
Wenn True, wird der Brier Score mit 1/2 skaliert, um im Bereich [0, 1] statt im Bereich [0, 2] zu liegen. Die Standardoption „auto“ implementiert die Skalierung auf [0, 1] nur für binäre Klassifizierung (wie üblich), behält aber für die multiklasse Klassifizierung den ursprünglichen Bereich [0, 2] bei.
Hinzugefügt in Version 1.7.
- Gibt zurück:
- scorefloat
Brier Score Verlust.
Anmerkungen
Für \(N\) Beobachtungen, die aus \(C\) möglichen Klassen gelabelt sind, ist der Brier Score definiert als
\[\frac{1}{N}\sum_{i=1}^{N}\sum_{c=1}^{C}(y_{ic} - \hat{p}_{ic})^{2}\]wobei \(y_{ic}\) 1 ist, wenn Beobachtung
izur Klassecgehört, andernfalls 0, und \(\hat{p}_{ic}\) die vorhergesagte Wahrscheinlichkeit ist, dass Beobachtungizur Klassecgehört. Der Brier Score liegt dann zwischen \([0, 2]\).Bei binären Klassifizierungsaufgaben wird der Brier Score normalerweise durch zwei geteilt und liegt dann zwischen \([0, 1]\). Er kann alternativ geschrieben werden als
\[\frac{1}{N}\sum_{i=1}^{N}(y_{i} - \hat{p}_{i})^{2}\]wobei \(y_{i}\) das binäre Ziel und \(\hat{p}_{i}\) die vorhergesagte Wahrscheinlichkeit der positiven Klasse ist.
Referenzen
Beispiele
>>> import numpy as np >>> from sklearn.metrics import brier_score_loss >>> y_true = np.array([0, 1, 1, 0]) >>> y_true_categorical = np.array(["spam", "ham", "ham", "spam"]) >>> y_prob = np.array([0.1, 0.9, 0.8, 0.3]) >>> brier_score_loss(y_true, y_prob) 0.0375 >>> brier_score_loss(y_true, 1-y_prob, pos_label=0) 0.0375 >>> brier_score_loss(y_true_categorical, y_prob, pos_label="ham") 0.0375 >>> brier_score_loss(y_true, np.array(y_prob) > 0.5) 0.0 >>> brier_score_loss(y_true, y_prob, scale_by_half=False) 0.075 >>> brier_score_loss( ... ["eggs", "ham", "spam"], ... [[0.8, 0.1, 0.1], [0.2, 0.7, 0.1], [0.2, 0.2, 0.6]], ... labels=["eggs", "ham", "spam"] ... ) 0.146
Galeriebeispiele#
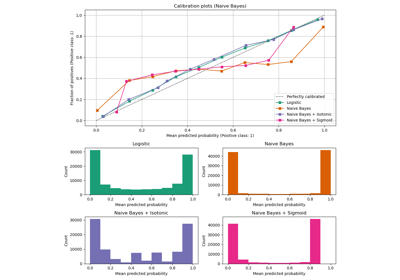
Wahrscheinlichkeitskalibrierung von Klassifikatoren
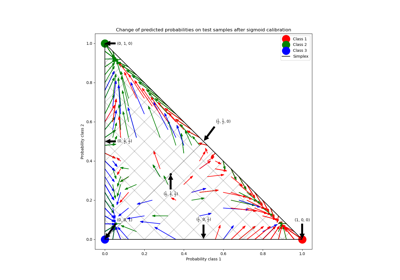
Wahrscheinlichkeitskalibrierung für 3-Klassen-Klassifikation
