IterativeImputer#
- class sklearn.impute.IterativeImputer(estimator=None, *, missing_values=nan, sample_posterior=False, max_iter=10, tol=0.001, n_nearest_features=None, initial_strategy='mean', fill_value=None, imputation_order='ascending', skip_complete=False, min_value=-inf, max_value=inf, verbose=0, random_state=None, add_indicator=False, keep_empty_features=False)[Quelle]#
Multivariater Imputer, der jedes Merkmal aus allen anderen schätzt.
Eine Strategie zum Imputieren fehlender Werte, indem jede Spalte mit fehlenden Werten als Funktion anderer Spalten im Round-Robin-Verfahren modelliert wird.
Mehr dazu im Benutzerhandbuch.
Hinzugefügt in Version 0.21.
Hinweis
Dieser Estimator ist derzeit noch experimentell: die Vorhersagen und die API können sich ohne Vorankündigungszeitraum ändern. Um ihn zu nutzen, müssen Sie explizit
enable_iterative_imputerimportieren>>> # explicitly require this experimental feature >>> from sklearn.experimental import enable_iterative_imputer # noqa >>> # now you can import normally from sklearn.impute >>> from sklearn.impute import IterativeImputer
- Parameter:
- estimatorEstimator-Objekt, Standardwert=BayesianRidge()
Der Estimator, der bei jedem Schritt der Round-Robin-Imputation verwendet wird. Wenn
sample_posterior=True, muss der Estimatorreturn_stdin seinerpredict-Methode unterstützen.- missing_valuesint oder np.nan, Standardwert=np.nan
Der Platzhalter für die fehlenden Werte. Alle Vorkommen von
missing_valueswerden imputiert. Für Pandas DataFrames mit nullbaren Integer-Datentypen mit fehlenden Werten solltemissing_valuesaufnp.nangesetzt werden, dapd.NAinnp.nankonvertiert wird.- sample_posteriorbool, Standardwert=False
Ob aus der (Gaußschen) prädiktiven Posterior des angepassten Estimators für jede Imputation gesampelt werden soll. Der Estimator muss
return_stdin seinerpredict-Methode unterstützen, wennTruegesetzt ist. AufTruesetzen, wennIterativeImputerfür multiple Imputationen verwendet wird.- max_iterint, Standardwert=10
Maximale Anzahl von Imputationsrunden, die durchgeführt werden, bevor die in der letzten Runde berechneten Imputationen zurückgegeben werden. Eine Runde ist eine einzelne Imputation jeder Spalte mit fehlenden Werten. Das Abbruchkriterium ist erreicht, wenn
max(abs(X_t - X_{t-1}))/max(abs(X[bekannte_werte])) < tol, wobeiX_tXzur Iterationtist. Beachten Sie, dass ein vorzeitiger Abbruch nur angewendet wird, wennsample_posterior=False.- tolfloat, Standard=1e-3
Toleranz der Abbruchbedingung.
- n_nearest_featuresint, Standardwert=None
Anzahl der anderen Merkmale, die verwendet werden, um die fehlenden Werte jeder Merkmalsspalte zu schätzen. Die Nähe zwischen den Merkmalen wird durch den absoluten Korrelationskoeffizienten zwischen jedem Merkmalspaar (nach anfänglicher Imputation) gemessen. Um die Abdeckung der Merkmale während des gesamten Imputationsprozesses zu gewährleisten, sind die benachbarten Merkmale nicht unbedingt die nächstgelegenen, sondern werden mit einer Wahrscheinlichkeit proportional zur Korrelation für jedes imputierte Zielmerkmal gezogen. Kann bei einer sehr großen Anzahl von Merkmalen eine erhebliche Beschleunigung bewirken. Wenn
None, werden alle Merkmale verwendet.- initial_strategy{‘mean’, ‘median’, ‘most_frequent’, ‘constant’}, Standardwert=’mean’
Welche Strategie zur Initialisierung der fehlenden Werte verwendet werden soll. Gleiche wie der
strategyParameter inSimpleImputer.- fill_valuestr oder numerischer Wert, Standardwert=None
Wenn
strategy="constant", wirdfill_valueverwendet, um alle Vorkommen von missing_values zu ersetzen. Für Zeichenketten- oder Objektdatentypen mussfill_valueeine Zeichenkette sein. WennNone, istfill_value0 bei der Imputation numerischer Daten und „missing_value“ für Zeichenketten oder Objektdatentypen.Hinzugefügt in Version 1.3.
- imputation_order{‘ascending’, ‘descending’, ‘roman’, ‘arabic’, ‘random’}, Standardwert=’ascending’
Die Reihenfolge, in der die Merkmale imputiert werden. Mögliche Werte
'ascending': Von Merkmalen mit den wenigsten fehlenden Werten zu den meisten.'descending': Von Merkmalen mit den meisten fehlenden Werten zu den wenigsten.'roman': Von links nach rechts.'arabic': Von rechts nach links.'random': Eine zufällige Reihenfolge für jede Runde.
- skip_completebool, Standardwert=False
Wenn
True, dann werden Merkmale mit fehlenden Werten währendtransform, die währendfitkeine fehlenden Werte hatten, nur mit der anfänglichen Imputationsmethode imputiert. AufTruesetzen, wenn Sie viele Merkmale ohne fehlende Werte sowohl zurfit- als auch zurtransform-Zeit haben, um Rechenzeit zu sparen.- min_valuefloat oder array-ähnlich, Form (n_features,), Standardwert=-np.inf
Mindestwert für imputierte Werte. Wird auf die Form
(n_features,)verbreitert, wenn skalar. Wenn array-ähnlich, erwartet die Form(n_features,), ein Minimalwert für jedes Merkmal. Der Standardwert ist-np.inf.Geändert in Version 0.23: Unterstützung für array-ähnliche hinzugefügt.
- max_valuefloat oder array-ähnlich, Form (n_features,), Standardwert=np.inf
Maximalwert für imputierte Werte. Wird auf die Form
(n_features,)verbreitert, wenn skalar. Wenn array-ähnlich, erwartet die Form(n_features,), ein Maximalwert für jedes Merkmal. Der Standardwert istnp.inf.Geändert in Version 0.23: Unterstützung für array-ähnliche hinzugefügt.
- verboseint, default=0
Verbositätsflag, steuert die Fehlermeldungen, die beim Auswerten von Funktionen ausgegeben werden. Je höher, desto ausführlicher. Kann 0, 1 oder 2 sein.
- random_stateint, RandomState-Instanz oder None, default=None
Der Seed des Pseudo-Zufallszahlengenerators, der verwendet werden soll. Randomisiert die Auswahl der Estimator-Merkmale, wenn
n_nearest_featuresnichtNoneist, dieimputation_order, wennrandom, und das Sampling aus der Posterior, wennsample_posterior=True. Verwenden Sie eine Ganzzahl für Determinismus. Siehe Glossar.- add_indicatorbool, Standardwert=False
Wenn
True, wird einMissingIndicator-Transformationsschritt an das Ergebnis der Imputer-Transformation angehängt. Dies ermöglicht es einem prädiktiven Estimator, fehlende Werte trotz Imputation zu berücksichtigen. Wenn ein Merkmal zur Fit-/Trainingszeit keine fehlenden Werte hat, erscheint das Merkmal nicht im fehlenden Indikator, auch wenn zur Transform-/Testzeit fehlende Werte vorhanden sind.- keep_empty_featuresbool, Standardwert=False
Wenn True, werden Merkmale, die zum Zeitpunkt des Aufrufs von
fitausschließlich aus fehlenden Werten bestehen, bei Aufruf vontransformin den Ergebnissen zurückgegeben. Der imputierte Wert ist immer0, es sei denn,initial_strategy="constant", in diesem Fall wird stattdessenfill_valueverwendet.Hinzugefügt in Version 1.2.
- Attribute:
- initial_imputer_Objekt vom Typ
SimpleImputer Imputer, der zur Initialisierung der fehlenden Werte verwendet wird.
- imputation_sequence_Liste von Tupeln
Jedes Tupel enthält
(feat_idx, neighbor_feat_idx, estimator), wobeifeat_idxdas aktuell zu imputierende Merkmal ist,neighbor_feat_idxdas Array der anderen Merkmale ist, die zur Imputation des aktuellen Merkmals verwendet werden, undestimatorder trainierte Estimator ist, der für die Imputation verwendet wird. Die Länge beträgtself.n_features_with_missing_ * self.n_iter_.- n_iter_int
Anzahl der aufgetretenen Iterationsrunden. Wird kleiner als
self.max_itersein, wenn das Kriterium für einen frühen Abbruch erreicht wurde.- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
- n_features_with_missing_int
Anzahl der Merkmale mit fehlenden Werten.
- indicator_
MissingIndicator Indikator, der verwendet wird, um binäre Indikatoren für fehlende Werte hinzuzufügen.
None, wennadd_indicator=False.- random_state_RandomState-Instanz
RandomState-Instanz, die entweder aus einem Seed, dem Zufallszahlengenerator oder
np.randomgeneriert wurde.
- initial_imputer_Objekt vom Typ
Siehe auch
SimpleImputerUnivariater Imputer zur Vervollständigung fehlender Werte mit einfachen Strategien.
KNNImputerMultivariater Imputer, der fehlende Merkmale mit den nächstgelegenen Stichproben schätzt.
Anmerkungen
Um die Imputation im induktiven Modus zu unterstützen, speichern wir den Estimator jedes Merkmals während der
fit-Phase und sagen ohne erneutes Anpassen (in Reihenfolge) während dertransform-Phase voraus.Merkmale, die zum Zeitpunkt von
fitausschließlich fehlende Werte enthalten, werden beitransformverworfen.Bei Verwendung der Standardeinstellungen skaliert der Imputer mit \(\mathcal{O}(knp^3\min(n,p))\), wobei \(k\) =
max_iter, \(n\) die Anzahl der Stichproben und \(p\) die Anzahl der Merkmale ist. Er wird daher bei zunehmender Anzahl von Merkmalen prohibitiv teuer. Das Setzen vonn_nearest_features << n_features,skip_complete=Trueoder das Erhöhen vontolkann helfen, seine Rechenkosten zu reduzieren.Abhängig von der Art der fehlenden Werte können einfache Imputer im Vorhersagekontext vorzuziehen sein.
Referenzen
Beispiele
>>> import numpy as np >>> from sklearn.experimental import enable_iterative_imputer >>> from sklearn.impute import IterativeImputer >>> imp_mean = IterativeImputer(random_state=0) >>> imp_mean.fit([[7, 2, 3], [4, np.nan, 6], [10, 5, 9]]) IterativeImputer(random_state=0) >>> X = [[np.nan, 2, 3], [4, np.nan, 6], [10, np.nan, 9]] >>> imp_mean.transform(X) array([[ 6.9584, 2. , 3. ], [ 4. , 2.6000, 6. ], [10. , 4.9999, 9. ]])
Ein detaillierteres Beispiel finden Sie unter Imputieren fehlender Werte vor dem Erstellen eines Estimators oder Imputieren fehlender Werte mit Varianten von IterativeImputer.
- fit(X, y=None, **fit_params)[Quelle]#
Passt den Imputer an
Xan und gibtselfzurück.- Parameter:
- Xarray-ähnlich, Form (n_samples, n_features)
Eingabedaten, wobei
n_samplesdie Anzahl der Stichproben undn_featuresdie Anzahl der Merkmale ist.- yIgnoriert
Wird nicht verwendet, ist aber aus Gründen der API-Konsistenz per Konvention vorhanden.
- **fit_paramsdict
Parameter, die über die Metadaten-Routing-API an die
fit-Methode des Unterestimators weitergeleitet werden.Hinzugefügt in Version 1.5: Nur verfügbar, wenn
sklearn.set_config(enable_metadata_routing=True)gesetzt ist. Siehe Metadaten-Routing-Benutzerhandbuch für weitere Details.
- Gibt zurück:
- selfobject
Angepasster Schätzer.
- fit_transform(X, y=None, **params)[Quelle]#
Passt den Imputer an
Xan und gibt das transformierteXzurück.- Parameter:
- Xarray-ähnlich, Form (n_samples, n_features)
Eingabedaten, wobei
n_samplesdie Anzahl der Stichproben undn_featuresdie Anzahl der Merkmale ist.- yIgnoriert
Wird nicht verwendet, ist aber aus Gründen der API-Konsistenz per Konvention vorhanden.
- **paramsdict
Parameter, die über die Metadaten-Routing-API an die
fit-Methode des Unterestimators weitergeleitet werden.Hinzugefügt in Version 1.5: Nur verfügbar, wenn
sklearn.set_config(enable_metadata_routing=True)gesetzt ist. Siehe Metadaten-Routing-Benutzerhandbuch für weitere Details.
- Gibt zurück:
- Xtarray-ähnlich, Form (n_samples, n_features)
Die imputierten Eingabedaten.
- get_feature_names_out(input_features=None)[Quelle]#
Holt die Ausgabemerkmale für die Transformation.
- Parameter:
- input_featuresarray-like von str oder None, default=None
Eingabemerkmale.
Wenn
input_featuresNoneist, werdenfeature_names_in_als Merkmalnamen verwendet. Wennfeature_names_in_nicht definiert ist, werden die folgenden Eingabemerkmalsnamen generiert:["x0", "x1", ..., "x(n_features_in_ - 1)"].Wenn
input_featuresein Array-ähnliches Objekt ist, mussinput_featuresmitfeature_names_in_übereinstimmen, wennfeature_names_in_definiert ist.
- Gibt zurück:
- feature_names_outndarray von str-Objekten
Transformierte Merkmalnamen.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
Hinzugefügt in Version 1.5.
- Gibt zurück:
- routingMetadataRouter
Ein
MetadataRouter, der die Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- set_output(*, transform=None)[Quelle]#
Ausgabecontainer festlegen.
Siehe Einführung in die set_output API für ein Beispiel zur Verwendung der API.
- Parameter:
- transform{“default”, “pandas”, “polars”}, default=None
Konfiguriert die Ausgabe von
transformundfit_transform."default": Standardausgabeformat eines Transformers"pandas": DataFrame-Ausgabe"polars": Polars-AusgabeNone: Die Transformationskonfiguration bleibt unverändert
Hinzugefügt in Version 1.4: Die Option
"polars"wurde hinzugefügt.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- transform(X)[Quelle]#
Imputiert alle fehlenden Werte in
X.Beachten Sie, dass dies stochastisch ist und dass bei nicht fixiertem
random_statewiederholte Aufrufe oder permutierte Eingaben zu unterschiedlichen Ergebnissen führen.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Die Eingabedaten, die vervollständigt werden sollen.
- Gibt zurück:
- Xtarray-ähnlich, Form (n_samples, n_features)
Die imputierten Eingabedaten.
Galeriebeispiele#
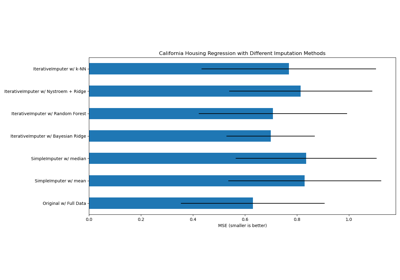
Fehlende Werte mit Varianten von IterativeImputer imputieren

Fehlende Werte imputieren, bevor ein Schätzer erstellt wird