DBSCAN#
- class sklearn.cluster.DBSCAN(eps=0.5, *, min_samples=5, metric='euclidean', metric_params=None, algorithm='auto', leaf_size=30, p=None, n_jobs=None)[Quelle]#
Führt DBSCAN-Clustering aus einer Vektor- oder Distanzmatrix durch.
DBSCAN - Dichte-basierte räumliche Clusterbildung von Anwendungen mit Rauschen. Findet Kernstichproben mit hoher Dichte und erweitert Cluster von ihnen aus. Dieser Algorithmus eignet sich besonders gut für Daten, die Cluster ähnlicher Dichte enthalten, und kann Cluster beliebiger Form finden.
Im Gegensatz zu K-Means erfordert DBSCAN nicht die Angabe der Anzahl der Cluster im Voraus und kann Ausreißer als Rauschpunkte identifizieren.
Diese Implementierung hat eine Speicherkomplexität im Worst Case von \(O({n}^2)\), die auftreten kann, wenn der Parameter
epsgroß undmin_samplesklein ist, während das ursprüngliche DBSCAN nur linearen Speicher verwendet. Weitere Details finden Sie in den Hinweisen unten.Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- epsfloat, Standard=0.5
Der maximale Abstand zwischen zwei Stichproben, damit eine als Nachbar der anderen betrachtet wird. Dies ist keine Obergrenze für die Abstände von Punkten innerhalb eines Clusters. Dies ist der wichtigste Parameter von DBSCAN, der für Ihren Datensatz und Ihre Distanzfunktion richtig gewählt werden muss. Kleinere Werte führen im Allgemeinen zu mehr Clustern.
- min_samplesint, Standard=5
Die Anzahl der Stichproben (oder das Gesamtgewicht) in einer Nachbarschaft, damit ein Punkt als Kernpunkt betrachtet wird. Dies schließt den Punkt selbst ein. Wenn
min_samplesauf einen höheren Wert gesetzt wird, findet DBSCAN dichtere Cluster, während bei einem niedrigeren Wert die gefundenen Cluster spärlicher sind.- metricstr, oder aufrufbar, Standard=’euclidean’
Die Metrik, die bei der Berechnung des Abstands zwischen Instanzen in einem Merkmalsarray verwendet werden soll. Wenn metric ein String oder aufrufbar ist, muss es eine der Optionen sein, die von
sklearn.metrics.pairwise_distancesfür seinen metric-Parameter zulässig sind. Wenn metric "precomputed" ist, wird X als Distanzmatrix angenommen und muss quadratisch sein. X kann ein spärlicher Graph sein, in diesem Fall dürfen nur "nonzero" Elemente als Nachbarn für DBSCAN berücksichtigt werden.Hinzugefügt in Version 0.17: metric precomputed zur Annahme von vorberechneten spärlichen Matrizen.
- metric_paramsdict, Standard=None
Zusätzliche Schlüsselwortargumente für die Metrikfunktion.
Hinzugefügt in Version 0.19.
- algorithm{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, Standard=’auto’
Der Algorithmus, der vom NearestNeighbors-Modul verwendet werden soll, um punktweise Abstände zu berechnen und die nächsten Nachbarn zu finden. "auto" versucht, den am besten geeigneten Algorithmus basierend auf den an die
fitMethode übergebenen Werten zu bestimmen. Siehe die Dokumentation zuNearestNeighborsfür Details.- leaf_sizeint, Standard=30
Blattgröße, die an BallTree oder cKDTree übergeben wird. Dies kann die Geschwindigkeit der Konstruktion und Abfrage sowie den für die Speicherung des Baumes erforderlichen Speicher beeinflussen. Der optimale Wert hängt von der Natur des Problems ab.
- pfloat, Standard=None
Die Potenz der Minkowski-Metrik, die zur Berechnung des Abstands zwischen Punkten verwendet werden soll. Wenn None, dann
p=2(entspricht dem Euklidischen Abstand). Wenn p=1, entspricht dies dem Manhattan-Abstand.- n_jobsint, default=None
Die Anzahl der parallelen Jobs, die ausgeführt werden sollen.
Nonebedeutet 1, es sei denn, Sie befinden sich in einemjoblib.parallel_backend-Kontext.-1bedeutet die Verwendung aller Prozessoren. Siehe Glossar für weitere Details.
- Attribute:
- core_sample_indices_ndarray der Form (n_core_samples,)
Indizes der Kernstichproben.
- components_ndarray der Form (n_core_samples, n_features)
Kopie jeder vom Training gefundenen Kernstichprobe.
- labels_ndarray der Form (n_samples,)
Cluster-Beschriftungen für jeden Punkt im an fit übergebenen Datensatz. Rauschstichproben erhalten die Beschriftung -1. Nicht-negative ganze Zahlen geben die Cluster-Mitgliedschaft an.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
Siehe auch
OPTICSEine ähnliche Clusterbildung bei mehreren Werten von eps. Unsere Implementierung ist auf Speicherverbrauch optimiert.
Anmerkungen
Diese Implementierung führt alle Nachbarschaftsabfragen gebündelt durch, was die Speicherkomplexität auf O(n.d) erhöht, wobei d die durchschnittliche Anzahl von Nachbarn ist, während das ursprüngliche DBSCAN eine Speicherkomplexität von O(n) hatte. Sie kann eine höhere Speicherkomplexität bei der Abfrage dieser nächsten Nachbarschaften aufweisen, abhängig vom
algorithm.Eine Möglichkeit, die Abfragekomplexität zu vermeiden, ist die Vorab-Berechnung spärlicher Nachbarschaften in Blöcken mithilfe von
NearestNeighbors.radius_neighbors_graphmitmode='distance'und anschließender Verwendung vonmetric='precomputed'hier.Eine weitere Möglichkeit, Speicher und Berechnungszeit zu reduzieren, ist das Entfernen von (nahezu) doppelten Punkten und die Verwendung von
sample_weightanstelle dessen.OPTICSbietet eine ähnliche Clusterbildung mit geringerem Speicherverbrauch.Referenzen
Ester, M., H. P. Kriegel, J. Sander und X. Xu, „A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise“. In: Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Portland, OR, AAAI Press, S. 226-231. 1996
Schubert, E., Sander, J., Ester, M., Kriegel, H. P. & Xu, X. (2017). „DBSCAN revisited, revisited: why and how you should (still) use DBSCAN.“ ACM Transactions on Database Systems (TODS), 42(3), 19.
Beispiele
>>> from sklearn.cluster import DBSCAN >>> import numpy as np >>> X = np.array([[1, 2], [2, 2], [2, 3], ... [8, 7], [8, 8], [25, 80]]) >>> clustering = DBSCAN(eps=3, min_samples=2).fit(X) >>> clustering.labels_ array([ 0, 0, 0, 1, 1, -1]) >>> clustering DBSCAN(eps=3, min_samples=2)
Ein Beispiel finden Sie unter Demo des DBSCAN-Cluster-Algorithmus.
Einen Vergleich von DBSCAN mit anderen Clustering-Algorithmen finden Sie unter Vergleich verschiedener Clustering-Algorithmen auf einfachen Datensätzen
- fit(X, y=None, sample_weight=None)[Quelle]#
Führen Sie die DBSCAN-Clusterbildung aus Merkmalen oder einer Distanzmatrix durch.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features), oder (n_samples, n_samples)
Trainingsinstanzen zum Clustern oder Abstände zwischen Instanzen, wenn
metric='precomputed'ist. Wenn eine spärliche Matrix bereitgestellt wird, wird sie in eine spärlichecsr_matrixkonvertiert.- yIgnoriert
Nicht verwendet, hier zur API-Konsistenz durch Konvention vorhanden.
- sample_weightarray-like der Form (n_samples,), Standardwert=None
Gewicht jeder Stichprobe, so dass eine Stichprobe mit einem Gewicht von mindestens
min_samplesselbst eine Kernstichprobe ist; eine Stichprobe mit negativem Gewicht kann verhindern, dass ihr epsilon-Nachbar ein Kernpunkt wird. Beachten Sie, dass Gewichte absolut sind und standardmäßig 1 betragen.
- Gibt zurück:
- selfobject
Gibt eine angepasste Instanz von self zurück.
- fit_predict(X, y=None, sample_weight=None)[Quelle]#
Cluster aus einer Daten- oder Distanzmatrix berechnen und Beschriftungen vorhersagen.
Diese Methode passt das Modell an und gibt die Cluster-Beschriftungen in einem Schritt zurück. Sie ist äquivalent zum Aufruf von fit(X).labels_.
- Parameter:
- X{array-like, sparse matrix} der Form (n_samples, n_features), oder (n_samples, n_samples)
Trainingsinstanzen zum Clustern oder Abstände zwischen Instanzen, wenn
metric='precomputed'ist. Wenn eine spärliche Matrix bereitgestellt wird, wird sie in eine spärlichecsr_matrixkonvertiert.- yIgnoriert
Nicht verwendet, hier zur API-Konsistenz durch Konvention vorhanden.
- sample_weightarray-like der Form (n_samples,), Standardwert=None
Gewicht jeder Stichprobe, so dass eine Stichprobe mit einem Gewicht von mindestens
min_samplesselbst eine Kernstichprobe ist; eine Stichprobe mit negativem Gewicht kann verhindern, dass ihr epsilon-Nachbar ein Kernpunkt wird. Beachten Sie, dass Gewichte absolut sind und standardmäßig 1 betragen.
- Gibt zurück:
- labelsndarray der Form (n_samples,)
Cluster-Beschriftungen. Rauschstichproben erhalten die Beschriftung -1. Nicht-negative ganze Zahlen geben die Cluster-Mitgliedschaft an.
- get_metadata_routing()[Quelle]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[Quelle]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- set_fit_request(*, sample_weight: bool | None | str = '$UNCHANGED$') DBSCAN[Quelle]#
Konfiguriert, ob Metadaten für die
fit-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anfitübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anfit.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinfit.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_params(**params)[Quelle]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
Galeriebeispiele#
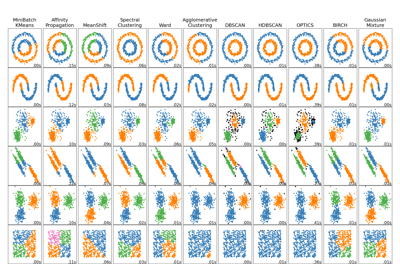
Vergleich verschiedener Clustering-Algorithmen auf Toy-Datensätzen