adjusted_mutual_info_score#
- sklearn.metrics.adjusted_mutual_info_score(labels_true, labels_pred, *, average_method='arithmetic')[Quelle]#
Adjustierte gegenseitige Information zwischen zwei Clusterings.
Die Adjusted Mutual Information (AMI) ist eine Anpassung des Mutual Information (MI) Scores, um den Zufall zu berücksichtigen. Sie berücksichtigt die Tatsache, dass die MI im Allgemeinen für zwei Clusterings mit einer größeren Anzahl von Clustern höher ist, unabhängig davon, ob tatsächlich mehr Informationen geteilt werden. Für zwei Clusterings \(U\) und \(V\) ist die AMI gegeben durch
AMI(U, V) = [MI(U, V) - E(MI(U, V))] / [avg(H(U), H(V)) - E(MI(U, V))]
Diese Metrik ist unabhängig von den absoluten Werten der Labels: eine Permutation der Klassen- oder Cluster-Labelwerte ändert den Score-Wert in keiner Weise.
Diese Metrik ist außerdem symmetrisch: Das Vertauschen von \(U\) (
label_true) mit \(V\) (labels_pred) gibt denselben Score-Wert zurück. Dies kann nützlich sein, um die Übereinstimmung zweier unabhängiger Label-Zuweisungsstrategien auf demselben Datensatz zu messen, wenn die tatsächliche Grundwahrheit nicht bekannt ist.Beachten Sie, dass diese Funktion um eine Größenordnung langsamer ist als andere Metriken wie der Adjusted Rand Index.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- labels_trueint array-like von Shape (n_samples,)
Ein Clustering der Daten in disjunkte Teilmengen, genannt \(U\) in der obigen Formel.
- labels_predint array-like von Shape (n_samples,)
Ein Clustering der Daten in disjunkte Teilmengen, genannt \(V\) in der obigen Formel.
- average_method{‘min’, ‘geometric’, ‘arithmetic’, ‘max’}, Standardwert=’arithmetic’
Wie der Normalisator im Nenner berechnet wird.
Hinzugefügt in Version 0.20.
Geändert in Version 0.22: Der Standardwert von
average_methodwurde von ‘max’ zu ‘arithmetic’ geändert.
- Gibt zurück:
- ami: float (obere Grenze bei 1,0)
Die AMI gibt einen Wert von 1 zurück, wenn die beiden Partitionen identisch sind (d.h. perfekt übereinstimmen). Zufällige Partitionen (unabhängige Labellings) haben im Durchschnitt eine erwartete AMI um 0, daher kann sie negativ sein. Der Wert liegt in angepassten Nats (basierend auf dem natürlichen Logarithmus).
Siehe auch
adjusted_rand_scoreAdjusted Rand Index.
mutual_info_scoreMutual Information (nicht für Zufall angepasst).
Referenzen
Beispiele
Perfekte Labellings sind sowohl homogen als auch vollständig, daher haben sie einen Score von 1,0
>>> from sklearn.metrics.cluster import adjusted_mutual_info_score >>> adjusted_mutual_info_score([0, 0, 1, 1], [0, 0, 1, 1]) 1.0 >>> adjusted_mutual_info_score([0, 0, 1, 1], [1, 1, 0, 0]) 1.0
Wenn Klassenmitglieder vollständig über verschiedene Cluster aufgeteilt sind, ist die Zuweisung völlig unvollständig, daher ist die AMI null.
>>> adjusted_mutual_info_score([0, 0, 0, 0], [0, 1, 2, 3]) 0.0
Galeriebeispiele#
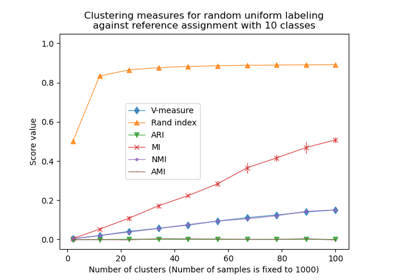
Anpassung für Zufälligkeit in der Clusterleistungsbewertung
Demo des Affinity Propagation Clustering Algorithmus
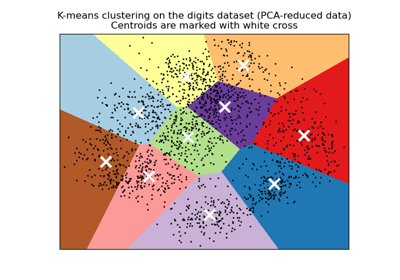
Eine Demo des K-Means Clusterings auf den handschriftlichen Zifferndaten