MeanShift#
- class sklearn.cluster.MeanShift(*, bandwidth=None, seeds=None, bin_seeding=False, min_bin_freq=1, cluster_all=True, n_jobs=None, max_iter=300)[source]#
Mean Shift Clustering mit einem flachen Kernel.
Mean-Shift-Clustering zielt darauf ab, „Blobs“ in einer glatten Dichte von Stichproben zu entdecken. Es ist ein zentroidbasierter Algorithmus, der Kandidaten für Zentroiden aktualisiert, indem er den Mittelwert der Punkte innerhalb eines bestimmten Bereichs ermittelt. Diese Kandidaten werden dann in einer Nachbearbeitungsphase gefiltert, um nahegelegene Duplikate zu eliminieren und die endgültige Menge von Zentroiden zu bilden.
Die Initialisierung (Seeding) erfolgt durch eine Binning-Technik zur Skalierbarkeit.
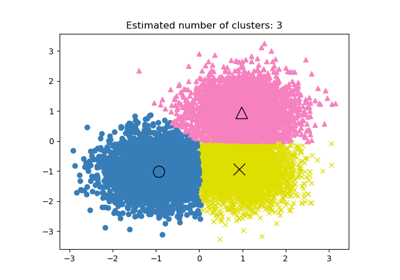
Ein Beispiel für die Verwendung von MeanShift-Clustering finden Sie unter: Eine Demo des Mean-Shift-Clustering-Algorithmus.
Lesen Sie mehr im Benutzerhandbuch.
- Parameter:
- bandwidthfloat, default=None
Bandbreite, die im flachen Kernel verwendet wird.
Wenn nicht angegeben, wird die Bandbreite mithilfe von sklearn.cluster.estimate_bandwidth geschätzt. Hinweise zur Skalierbarkeit finden Sie in der Dokumentation dieser Funktion (siehe auch die Hinweise unten).
- seedsarray-like von Form (n_samples, n_features), default=None
Seeds zur Initialisierung der Kernel. Wenn nicht gesetzt, werden die Seeds durch clustering.get_bin_seeds mit der Bandbreite als Rastergröße und Standardwerten für andere Parameter berechnet.
- bin_seedingbool, default=False
Wenn wahr, sind die anfänglichen Kernelpositionen nicht die Positionen aller Punkte, sondern die Position der diskretisierten Version von Punkten, wobei Punkte in ein Raster eingeteilt werden, dessen Grobheit der Bandbreite entspricht. Das Setzen dieser Option auf True beschleunigt den Algorithmus, da weniger Seeds initialisiert werden. Der Standardwert ist False. Wird ignoriert, wenn das Argument seeds nicht None ist.
- min_bin_freqint, default=1
Zur Beschleunigung des Algorithmus werden nur die Bins mit mindestens min_bin_freq Punkten als Seeds akzeptiert.
- cluster_allbool, default=True
Wenn wahr, werden alle Punkte geclustert, auch die Waisen, die nicht innerhalb eines Kernels liegen. Waisen werden dem nächstgelegenen Kernel zugeordnet. Wenn falsch, erhalten Waisen die Cluster-Beschriftung -1.
- n_jobsint, default=None
Die Anzahl der Jobs, die für die Berechnung verwendet werden. Die folgenden Aufgaben profitieren von der Parallelisierung
Die Suche nach den nächsten Nachbarn für die Bandbreitenschätzung und die Labelzuweisung. Details finden Sie in der Docstring-Beschreibung der Klasse
NearestNeighbors.Hill-Climbing-Optimierung für alle Seeds.
Siehe Glossar für weitere Details.
Nonebedeutet 1, außer in einemjoblib.parallel_backendKontext.-1bedeutet die Verwendung aller Prozessoren. Siehe Glossar für weitere Details.- max_iterint, Standard=300
Maximale Anzahl von Iterationen pro Seedpunkt, bevor die Clustering-Operation (für diesen Seedpunkt) beendet wird, wenn noch keine Konvergenz erreicht wurde.
Hinzugefügt in Version 0.22.
- Attribute:
- cluster_centers_ndarray von Form (n_clusters, n_features)
Koordinaten der Clusterzentren.
- labels_ndarray der Form (n_samples,)
Beschriftungen jedes Punkts.
- n_iter_int
Maximale Anzahl von Iterationen, die auf jedem Seed durchgeführt werden.
Hinzugefügt in Version 0.22.
- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
Siehe auch
KMeansK-Means-Clustering.
Anmerkungen
Skalierbarkeit
Da diese Implementierung einen flachen Kernel und einen Ball Tree zur Suche nach Mitgliedern jedes Kernels verwendet, tendiert die Komplexität in niedrigeren Dimensionen gegen O(T*n*log(n)), wobei n die Anzahl der Stichproben und T die Anzahl der Punkte ist. In höheren Dimensionen tendiert die Komplexität gegen O(T*n^2).
Die Skalierbarkeit kann durch die Verwendung von weniger Seeds verbessert werden, z. B. durch einen höheren Wert für min_bin_freq in der Funktion get_bin_seeds.
Beachten Sie, dass die Funktion estimate_bandwidth wesentlich weniger skalierbar ist als der Mean-Shift-Algorithmus und zum Flaschenhals wird, wenn sie verwendet wird.
Referenzen
Dorin Comaniciu und Peter Meer, „Mean Shift: A robust approach toward feature space analysis“. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2002. S. 603-619.
Beispiele
>>> from sklearn.cluster import MeanShift >>> import numpy as np >>> X = np.array([[1, 1], [2, 1], [1, 0], ... [4, 7], [3, 5], [3, 6]]) >>> clustering = MeanShift(bandwidth=2).fit(X) >>> clustering.labels_ array([1, 1, 1, 0, 0, 0]) >>> clustering.predict([[0, 0], [5, 5]]) array([1, 0]) >>> clustering MeanShift(bandwidth=2)
Für einen Vergleich von Mean-Shift-Clustering mit anderen Clustering-Algorithmen siehe Vergleich verschiedener Clustering-Algorithmen auf Beispiel-Datensätzen
- fit(X, y=None)[source]#
Führt die Clusterbildung durch.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Zu clusternde Stichproben.
- yIgnoriert
Wird nicht verwendet, ist aber aus Gründen der API-Konsistenz per Konvention vorhanden.
- Gibt zurück:
- selfobject
Angepasste Instanz.
- fit_predict(X, y=None, **kwargs)[source]#
Führt Clustering auf
Xdurch und gibt Cluster-Labels zurück.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Eingabedaten.
- yIgnoriert
Wird nicht verwendet, ist aber aus Gründen der API-Konsistenz per Konvention vorhanden.
- **kwargsdict
Argumente, die an
fitübergeben werden sollen.Hinzugefügt in Version 1.4.
- Gibt zurück:
- labelsndarray der Form (n_samples,), dtype=np.int64
Clusterbeschriftungen.
- get_metadata_routing()[source]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[source]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- predict(X)[source]#
Sagt den nächstgelegenen Cluster voraus, zu dem jede Stichprobe in X gehört.
- Parameter:
- Xarray-like der Form (n_samples, n_features)
Neue Daten zur Vorhersage.
- Gibt zurück:
- labelsndarray der Form (n_samples,)
Index des Clusters, zu dem jede Stichprobe gehört.
- set_params(**params)[source]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
Galeriebeispiele#
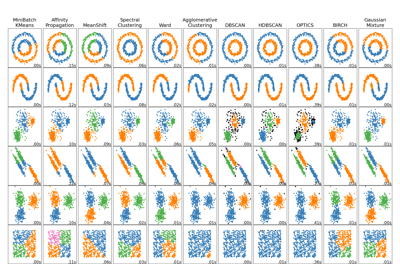
Vergleich verschiedener Clustering-Algorithmen auf Toy-Datensätzen