GaussianProcessRegressor#
- class sklearn.gaussian_process.GaussianProcessRegressor(kernel=None, *, alpha=1e-10, optimizer='fmin_l_bfgs_b', n_restarts_optimizer=0, normalize_y=False, copy_X_train=True, n_targets=None, random_state=None)[source]#
Gauß'sche Prozess-Regression (GPR).
Die Implementierung basiert auf Algorithmus 2.1 von [RW2006].
Zusätzlich zur Standard-API für scikit-learn-Schätzer erlaubt
GaussianProcessRegressorVorhersagen ohne vorheriges Anpassen (basierend auf dem GP-Prior)
bietet eine zusätzliche Methode
sample_y(X), die Stichproben aus dem GPR (Prior oder Posterior) an gegebenen Eingaben auswertetstellt eine Methode
log_marginal_likelihood(theta)zur Verfügung, die extern für andere Arten der Hyperparameter-Auswahl verwendet werden kann, z. B. mittels Markov-Ketten-Monte-Carlo.
Um den Unterschied zwischen einem Punkteschätzungsansatz und einem eher Bayes'schen Modellierungsansatz zu verstehen, siehe das Beispiel mit dem Titel Vergleich von Kernel-Ridge- und Gaußprozess-Regression.
Lesen Sie mehr im Benutzerhandbuch.
Hinzugefügt in Version 0.18.
- Parameter:
- kernelKernel-Instanz, Standard=None
Der Kernel, der die Kovarianzfunktion des GP spezifiziert. Wenn None übergeben wird, wird der Kernel
ConstantKernel(1.0, constant_value_bounds="fixed") * RBF(1.0, length_scale_bounds="fixed")als Standard verwendet. Beachten Sie, dass die Kernel-Hyperparameter während des Fits optimiert werden, es sei denn, die Grenzen sind als "fixed" markiert.- alphafloat oder ndarray der Form (n_samples,), Standard=1e-10
Wert, der zur Diagonalen der Kernelmatrix während des Fits hinzugefügt wird. Dies kann potenzielle numerische Probleme während des Fits verhindern, indem sichergestellt wird, dass die berechneten Werte eine positiv-definitive Matrix bilden. Es kann auch als die Varianz zusätzlicher Gaußscher Messrauschen bei den Trainingsbeobachtungen interpretiert werden. Beachten Sie, dass dies anders ist, als die Verwendung eines
WhiteKernel. Wenn ein Array übergeben wird, muss es die gleiche Anzahl von Einträgen wie die für den Fit verwendeten Daten haben und dient als datenpunktabhängige Rauschpegel. Das Zulassen der direkten Angabe des Rauschpegels als Parameter dient hauptsächlich der Bequemlichkeit und Konsistenz mitRidge. Ein Beispiel, das zeigt, wie der Alpha-Parameter die Rauschvarianz bei Gaußprozess-Regression steuert, finden Sie unter Gaußprozess-Regression: Einführendes Beispiel.- optimizer"fmin_l_bfgs_b", aufrufbar oder None, Standard="fmin_l_bfgs_b"
Kann entweder einer der intern unterstützten Optimierer zur Optimierung der Kernel-Parameter sein, angegeben durch einen String, oder ein extern definierter Optimierer, der als aufrufbar übergeben wird. Wenn eine aufrufbare Funktion übergeben wird, muss sie die Signatur haben
def optimizer(obj_func, initial_theta, bounds): # * 'obj_func': the objective function to be minimized, which # takes the hyperparameters theta as a parameter and an # optional flag eval_gradient, which determines if the # gradient is returned additionally to the function value # * 'initial_theta': the initial value for theta, which can be # used by local optimizers # * 'bounds': the bounds on the values of theta .... # Returned are the best found hyperparameters theta and # the corresponding value of the target function. return theta_opt, func_min
Standardmäßig wird der L-BFGS-B-Algorithmus von
scipy.optimize.minimizeverwendet. Wenn None übergeben wird, bleiben die Parameter des Kernels fixiert. Verfügbare interne Optimierer sind:{'fmin_l_bfgs_b'}.- n_restarts_optimizerint, Standard=0
Die Anzahl der Neustarts des Optimierers zur Suche nach den Kernel-Parametern, die die logarithmische marginale Likelihood maximieren. Der erste Lauf des Optimierers erfolgt von den anfänglichen Kernel-Parametern, die restlichen (falls vorhanden) von zufällig log-uniformen Thetas aus dem Raum der erlaubten Theta-Werte. Wenn größer als 0, müssen alle Grenzen endlich sein. Beachten Sie, dass
n_restarts_optimizer == 0einen Lauf impliziert.- normalize_ybool, Standard=False
Ob die Zielwerte
ydurch Entfernen des Mittels und Skalieren auf Einheitsvarianz normalisiert werden sollen oder nicht. Dies wird für Fälle empfohlen, in denen Priors mit Nullmittelwert und Einheitsvarianz verwendet werden. Beachten Sie, dass in dieser Implementierung die Normalisierung rückgängig gemacht wird, bevor die GP-Vorhersagen zurückgegeben werden.Geändert in Version 0.23.
- copy_X_trainbool, Standard=True
Wenn True, wird eine persistente Kopie der Trainingsdaten im Objekt gespeichert. Andernfalls wird nur eine Referenz auf die Trainingsdaten gespeichert, was dazu führen kann, dass sich Vorhersagen ändern, wenn die Daten extern modifiziert werden.
- n_targetsint, Standard=None
Die Anzahl der Dimensionen der Zielwerte. Wird verwendet, um die Anzahl der Ausgaben beim Ziehen von Stichproben aus den Prior-Verteilungen zu bestimmen (d.h. Aufruf von
sample_yvorfit). Dieser Parameter wird ignoriert, sobaldfitaufgerufen wurde.Hinzugefügt in Version 1.3.
- random_stateint, RandomState-Instanz oder None, default=None
Bestimmt die Zufallszahlengenerierung zur Initialisierung der Zentren. Übergeben Sie eine Ganzzahl für reproduzierbare Ergebnisse über mehrere Funktionsaufrufe hinweg. Siehe Glossar.
- Attribute:
- X_train_array-like der Form (n_samples, n_features) oder Liste von Objekten
Feature-Vektoren oder andere Darstellungen von Trainingsdaten (auch für Vorhersagen erforderlich).
- y_train_array-like der Form (n_samples,) oder (n_samples, n_targets)
Zielwerte in Trainingsdaten (auch für Vorhersagen erforderlich).
- kernel_Kernel-Instanz
Der für die Vorhersage verwendete Kernel. Die Struktur des Kernels ist dieselbe wie die übergebene, jedoch mit optimierten Hyperparametern.
- L_array-like der Form (n_samples, n_samples)
Unterdreieckige Cholesky-Zerlegung des Kernels in
X_train_.- alpha_array-like der Form (n_samples,)
Duale Koeffizienten von Trainingsdatenpunkten im Kernelraum.
- log_marginal_likelihood_value_float
Die logarithmische marginale Likelihood von
self.kernel_.theta.- n_features_in_int
Anzahl der während des fits gesehenen Merkmale.
Hinzugefügt in Version 0.24.
- feature_names_in_ndarray mit Form (
n_features_in_,) Namen der während fit gesehenen Merkmale. Nur definiert, wenn
XMerkmalnamen hat, die alle Zeichenketten sind.Hinzugefügt in Version 1.0.
Siehe auch
GaussianProcessClassifierGauß'sche Prozess-Klassifikation (GPC) basierend auf Laplace-Approximation.
Referenzen
Beispiele
>>> from sklearn.datasets import make_friedman2 >>> from sklearn.gaussian_process import GaussianProcessRegressor >>> from sklearn.gaussian_process.kernels import DotProduct, WhiteKernel >>> X, y = make_friedman2(n_samples=500, noise=0, random_state=0) >>> kernel = DotProduct() + WhiteKernel() >>> gpr = GaussianProcessRegressor(kernel=kernel, ... random_state=0).fit(X, y) >>> gpr.score(X, y) 0.3680... >>> gpr.predict(X[:2,:], return_std=True) (array([653.0, 592.1]), array([316.6, 316.6]))
- fit(X, y)[source]#
Trainiert das Gaußprozess-Regressionsmodell.
- Parameter:
- Xarray-like der Form (n_samples, n_features) oder Liste von Objekten
Feature-Vektoren oder andere Darstellungen von Trainingsdaten.
- yarray-like der Form (n_samples,) oder (n_samples, n_targets)
Zielwerte.
- Gibt zurück:
- selfobject
Instanz der Klasse GaussianProcessRegressor.
- get_metadata_routing()[source]#
Holt das Metadaten-Routing dieses Objekts.
Bitte prüfen Sie im Benutzerhandbuch, wie der Routing-Mechanismus funktioniert.
- Gibt zurück:
- routingMetadataRequest
Ein
MetadataRequest, der Routing-Informationen kapselt.
- get_params(deep=True)[source]#
Holt Parameter für diesen Schätzer.
- Parameter:
- deepbool, default=True
Wenn True, werden die Parameter für diesen Schätzer und die enthaltenen Unterobjekte, die Schätzer sind, zurückgegeben.
- Gibt zurück:
- paramsdict
Parameternamen, zugeordnet ihren Werten.
- log_marginal_likelihood(theta=None, eval_gradient=False, clone_kernel=True)[source]#
Gibt die logarithmische marginale Likelihood von Theta für Trainingsdaten zurück.
- Parameter:
- thetaarray-like der Form (n_kernel_params,) Standard=None
Kernel-Hyperparameter, für die die logarithmische marginale Likelihood ausgewertet wird. Wenn None, wird die vorab berechnete logarithmische marginale Likelihood von
self.kernel_.thetazurückgegeben.- eval_gradientbool, Standardwert=False
Wenn True, wird zusätzlich der Gradient der logarithmischen marginalen Likelihood in Bezug auf die Kernel-Hyperparameter an der Position theta zurückgegeben. Wenn True, darf theta nicht None sein.
- clone_kernelbool, Standard=True
Wenn True, wird das Kernel-Attribut kopiert. Wenn False, wird das Kernel-Attribut modifiziert, kann aber zu einer Leistungssteigerung führen.
- Gibt zurück:
- log_likelihoodfloat
Logarithmische marginale Likelihood von theta für Trainingsdaten.
- log_likelihood_gradientndarray der Form (n_kernel_params,), optional
Gradient der logarithmischen marginalen Likelihood in Bezug auf die Kernel-Hyperparameter an der Position theta. Wird nur zurückgegeben, wenn eval_gradient True ist.
- predict(X, return_std=False, return_cov=False)[source]#
Vorhersagen mit dem Gaußprozess-Regressionsmodell.
Wir können auch basierend auf einem ungefitteten Modell vorhersagen, indem wir den GP-Prior verwenden. Zusätzlich zum Mittelwert der Vorhersageverteilung werden optional auch deren Standardabweichung (
return_std=True) oder Kovarianz (return_cov=True) zurückgegeben. Beachten Sie, dass höchstens eine der beiden angefordert werden kann.- Parameter:
- Xarray-like der Form (n_samples, n_features) oder Liste von Objekten
Abfragepunkte, an denen der GP ausgewertet wird.
- return_stdbool, Standard=False
Wenn True, wird die Standardabweichung der Vorhersageverteilung an den Abfragepunkten zusammen mit dem Mittelwert zurückgegeben.
- return_covbool, Standard=False
Wenn True, wird die Kovarianz der gemeinsamen Vorhersageverteilung an den Abfragepunkten zusammen mit dem Mittelwert zurückgegeben.
- Gibt zurück:
- y_meanndarray der Form (n_samples,) oder (n_samples, n_targets)
Mittelwert der Vorhersageverteilung an den Abfragepunkten.
- y_stdndarray der Form (n_samples,) oder (n_samples, n_targets), optional
Standardabweichung der Vorhersageverteilung an den Abfragepunkten. Nur zurückgegeben, wenn
return_stdTrue ist.- y_covndarray der Form (n_samples, n_samples) oder (n_samples, n_samples, n_targets), optional
Kovarianz der gemeinsamen Vorhersageverteilung an den Abfragepunkten. Nur zurückgegeben, wenn
return_covTrue ist.
- sample_y(X, n_samples=1, random_state=0)[source]#
Zieht Stichproben aus dem Gaußprozess und wertet sie an X aus.
- Parameter:
- Xarray-ähnlich der Form (n_samples_X, n_features) oder Liste von Objekten
Abfragepunkte, an denen der GP ausgewertet wird.
- n_samplesint, Standard=1
Anzahl der aus dem Gaußprozess pro Abfragepunkt gezogenen Stichproben.
- random_stateint, RandomState-Instanz oder None, Standard=0
Bestimmt die Zufallszahlengenerierung zum zufälligen Ziehen von Stichproben. Übergeben Sie eine Ganzzahl für reproduzierbare Ergebnisse über mehrere Funktionsaufrufe hinweg. Siehe Glossar.
- Gibt zurück:
- y_samplesndarray der Form (n_samples_X, n_samples), oder (n_samples_X, n_targets, n_samples)
Werte von n_samples Stichproben, die aus dem Gaußprozess gezogen und an den Abfragepunkten ausgewertet wurden.
- score(X, y, sample_weight=None)[source]#
Gibt den Bestimmtheitskoeffizienten auf Testdaten zurück.
Der Bestimmtheitskoeffizient, \(R^2\), ist definiert als \((1 - \frac{u}{v})\), wobei \(u\) die Summe der quadrierten Residuen ist
((y_true - y_pred)** 2).sum()und \(v\) die Summe der quadrierten Abweichungen vom Mittelwert ist((y_true - y_true.mean()) ** 2).sum(). Der bestmögliche Wert ist 1,0 und er kann negativ sein (da das Modell beliebig schlechter sein kann). Ein konstantes Modell, das immer den Erwartungswert vonyvorhersagt, unabhängig von den Eingabemerkmalen, würde einen \(R^2\)-Score von 0,0 erzielen.- Parameter:
- Xarray-like der Form (n_samples, n_features)
Teststichproben. Für einige Schätzer kann dies eine vorab berechnete Kernelmatrix oder eine Liste von generischen Objekten sein, stattdessen mit der Form
(n_samples, n_samples_fitted), wobein_samples_fitteddie Anzahl der für die Anpassung des Schätzers verwendeten Stichproben ist.- yarray-like der Form (n_samples,) oder (n_samples, n_outputs)
Wahre Werte für
X.- sample_weightarray-like der Form (n_samples,), Standardwert=None
Stichprobengewichte.
- Gibt zurück:
- scorefloat
\(R^2\) von
self.predict(X)bezogen aufy.
Anmerkungen
Der \(R^2\)-Score, der beim Aufruf von
scoreauf einem Regressor verwendet wird, nutztmultioutput='uniform_average'ab Version 0.23, um konsistent mit dem Standardwert vonr2_scorezu bleiben. Dies beeinflusst diescore-Methode aller Multi-Output-Regressoren (mit Ausnahme vonMultiOutputRegressor).
- set_params(**params)[source]#
Setzt die Parameter dieses Schätzers.
Die Methode funktioniert sowohl bei einfachen Schätzern als auch bei verschachtelten Objekten (wie
Pipeline). Letztere haben Parameter der Form<component>__<parameter>, so dass es möglich ist, jede Komponente eines verschachtelten Objekts zu aktualisieren.- Parameter:
- **paramsdict
Schätzer-Parameter.
- Gibt zurück:
- selfestimator instance
Schätzer-Instanz.
- set_predict_request(*, return_cov: bool | None | str = '$UNCHANGED$', return_std: bool | None | str = '$UNCHANGED$') GaussianProcessRegressor[source]#
Konfiguriert, ob Metadaten für die
predict-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anpredictweitergegeben. Die Anforderung wird ignoriert, wenn keine Metadaten bereitgestellt werden.False: Metadaten werden nicht angefordert und die Meta-Schätzung übergibt sie nicht anpredict.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- return_covstr, True, False, oder None, Standard=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
return_covinpredict.- return_stdstr, True, False oder None, Standard=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
return_stdinpredict.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') GaussianProcessRegressor[source]#
Konfiguriert, ob Metadaten für die
score-Methode angefordert werden sollen.Beachten Sie, dass diese Methode nur relevant ist, wenn dieser Schätzer als Unter-Schätzer innerhalb eines Meta-Schätzers verwendet wird und Metadaten-Routing mit
enable_metadata_routing=Trueaktiviert ist (siehesklearn.set_config). Bitte lesen Sie das Benutzerhandbuch, um zu erfahren, wie der Routing-Mechanismus funktioniert.Die Optionen für jeden Parameter sind
True: Metadaten werden angefordert und, falls vorhanden, anscoreübergeben. Die Anforderung wird ignoriert, wenn keine Metadaten vorhanden sind.False: Metadaten werden nicht angefordert und der Meta-Schätzer übergibt sie nicht anscore.None: Metadaten werden nicht angefordert und der Meta-Schätzer löst einen Fehler aus, wenn der Benutzer sie bereitstellt.str: Metadaten sollten mit diesem Alias an den Meta-Schätzer übergeben werden und nicht mit dem ursprünglichen Namen.
Der Standardwert (
sklearn.utils.metadata_routing.UNCHANGED) behält die bestehende Anforderung bei. Dies ermöglicht es Ihnen, die Anforderung für einige Parameter zu ändern und für andere nicht.Hinzugefügt in Version 1.3.
- Parameter:
- sample_weightstr, True, False, oder None, Standardwert=sklearn.utils.metadata_routing.UNCHANGED
Metadaten-Routing für den Parameter
sample_weightinscore.
- Gibt zurück:
- selfobject
Das aktualisierte Objekt.
Galeriebeispiele#
Vergleich von Kernel Ridge und Gauß-Prozess-Regression
Prognose des CO2-Spiegels im Mona Loa Datensatz mittels Gauß-Prozess-Regression (GPR)
Fähigkeit der Gauß-Prozess-Regression (GPR) zur Schätzung des Datenrauschpegels
Gauß-Prozesse Regression: grundlegendes Einführungsexempel
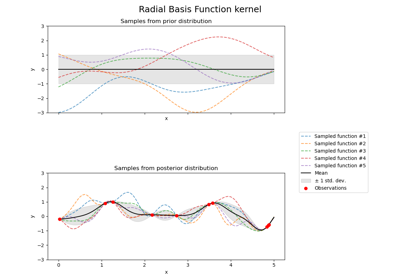
Illustration von Prior und Posterior Gauß-Prozess für verschiedene Kerne